
de.wedoany.com-Bericht: Baidu hat am 22. Juni das Unlimited OCR-Modell als Open Source veröffentlicht, um das Problem zu lösen, dass End-to-End-OCR-Modelle bei der Analyse langer Dokumente mit zunehmender Generierung langsamer werden. Das Modell verfügt über insgesamt 3 Milliarden Parameter, von denen bei der Inferenz nur 500 Millionen aktiviert werden.
End-to-End-OCR-Modelle verwenden eine einheitliche neuronale Netzwerkarchitektur, die Texterkennung und Zeichenerkennung in einem System vereint und direkt vom Eingabebild zur Textsequenzausgabe übergeht, wodurch der herkömmliche Prozess der Erkennung von Textrahmen und anschließender separater Erkennung entfällt. Bei gängigen End-to-End-OCR-Modellen wird bei jedem generierten Token der Key-Value-Cache (KV-Cache) erweitert, was zu einem kontinuierlichen Anstieg des Speicherverbrauchs und der Latenz führt. Benutzer bemerken, dass die Analyse mehrseitiger Dokumente mit zunehmender Seitenzahl langsamer wird.
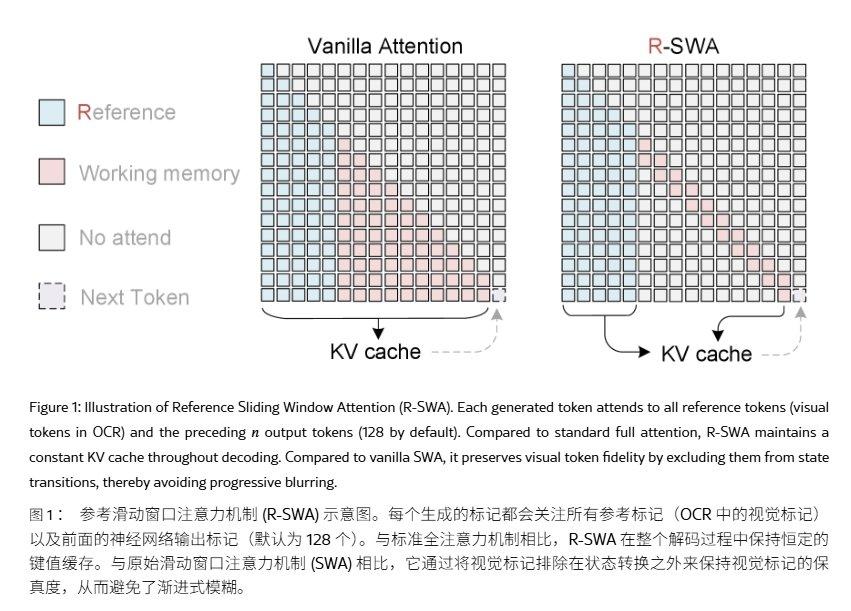
Unlimited OCR übernimmt die DeepSeek OCR-Architektur und behält den DeepEncoder sowie den Mixture-of-Experts (MoE)-Decoder bei. Auf der Encoder-Seite wird eine zweistufige visuelle Kodierung verwendet, bei der in der Verbindungsphase eine 16-fache Token-Kompression durchgeführt wird. Ein 1024×1024 großes PDF-Bild wird auf 256 visuelle Token komprimiert, wodurch die Vorladung von Anfang an reduziert wird.
Im Training wird Unlimited OCR basierend auf dem DeepSeek OCR-Checkpoint für 4000 Schritte weiter trainiert, wobei der DeepEncoder eingefroren und nur der Decoder trainiert wird. Die Trainingsdaten umfassen etwa 2 Millionen Dokumentenproben und laufen auf 8×16 A800 GPUs. Das Datenverhältnis zwischen einseitigen und mehrseitigen Dokumenten beträgt etwa 9:1, wobei mehrseitige Proben durch Verkettung erstellt werden.
Benchmark-Tests zeigen, dass Unlimited OCR auf OmniDocBench v1.5 eine Gesamtpunktzahl von 93,23 erreicht, höher als DeepSeek OCR mit 87,01 und DeepSeek OCR 2 mit 89,17. Die Textbearbeitungsdistanz beträgt 0,038, der Formel-CDM 92,61, der Tabellen-TEDS 90,93 und die Leseordnungs-Bearbeitungsdistanz 0,045. Auf OmniDocBench v1.6 erreicht das Modell eine Gesamtpunktzahl von 93,92.

Dieser Artikel wurde von Wedoany übersetzt und bearbeitet. Bei jeglicher Zitierung oder Nutzung durch künstliche Intelligenz (KI) ist die Quellenangabe „Wedoany“ zwingend vorgeschrieben. Sollten Urheberrechtsverletzungen oder andere Probleme vorliegen, bitten wir Sie, uns unverzüglich zu benachrichtigen. Wir werden den entsprechenden Inhalt umgehend anpassen oder löschen.
E-Mail: news@wedoany.com










