de.wedoany.com-Bericht: Am 1. Juni brachte das chinesische KI-Unternehmen MiniMax das neue Universalmodell MiniMax M3 auf den Markt. Das Modell basiert auf der selbst entwickelten MiniMax Sparse Attention-Architektur, die API unterstützt maximal 1 Million Tokens Kontextfenster und garantiert mindestens 512.000 Tokens nutzbaren Kontext. Es richtet sich vor allem an langlaufende Agenten, komplexe Code-Aufgaben und native multimodale Anwendungen.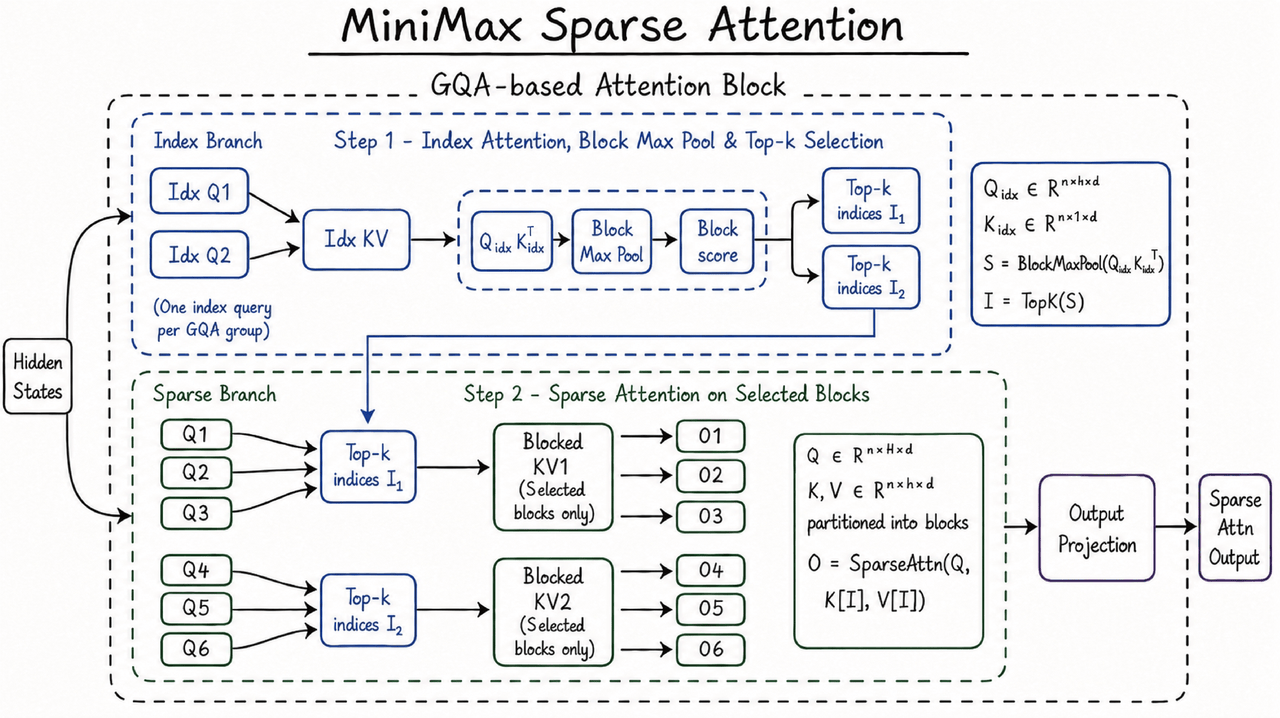
Der Kernwandel von MiniMax M3 besteht darin, dass die Langkontext-Fähigkeit von einem „Parameterindikator" zur „Trägerin von Engineering-Aufgaben" wird. Nachdem große Modelle in die Agentenphase eingetreten sind, müssen sie nicht mehr nur einzelne Frage-Antwort-Runden oder kurze Textgenerierung bewältigen, sondern langlaufende Aufgaben, die Code-Repositories, Produktdokumentationen, Aufgabenprotokolle, Tool-Aufrufaufzeichnungen sowie Bild- und Videoinformationen miteinander verweben. Ein Kontextfenster von 1 Million Tokens bedeutet, dass MiniMax M3 in einer Aufgabenkette mehr vor- und nachgelagerte Informationen behalten kann, wodurch Informationsverluste durch häufiges Abschneiden, wiederholte Zusammenfassungen und externe Abfragen reduziert werden. Für Softwareentwicklung, wissenschaftliche Reproduktion, Unternehmenswissensdatenbank-Fragen, Langvideo-Verständnis und komplexe Büroautomatisierungsszenarien wird ein langer Kontext zunehmend zu einer grundlegenden Fähigkeit, die darüber entscheidet, ob ein Modell stabil in den Produktionsprozess integriert werden kann.
Diese Fähigkeit wird durch die selbst entwickelte MiniMax Sparse Attention-Architektur (MSA) unterstützt. Herkömmliche Full-Attention-Mechanismen sehen sich bei zunehmender Kontextlänge mit einem rapiden Anstieg des Rechenaufwands konfrontiert. MSA verbessert die Recheneffizienz bei langen Kontexten durch sparse Attention, sodass MiniMax M3 in einem Millionen-Kontextfenster eine nutzbare Inferenzleistung aufrechterhalten kann. Offiziellen Angaben zufolge beträgt der Rechenaufwand pro Token bei M3 bei einer Kontextlänge von 1 Million etwa 1/20 des Vorgängermodells. Die Geschwindigkeit in der Prefill-Phase ist um mehr als das 9-fache gestiegen, in der Decode-Phase um mehr als das 15-fache. Für Entwickler und Unternehmensnutzer wirken sich solche Effizienzänderungen direkt auf die API-Kosten, die Antwortgeschwindigkeit und die Fähigkeit zur kontinuierlichen Ausführung langer Aufgaben aus und bestimmen auch, ob MiniMax M3 von Demonstrationsszenarien in häufigere geschäftliche Aufrufe übergehen kann.
MiniMax M3 betont gleichzeitig die Fähigkeiten in den Bereichen Codierung und Agenten. Software-Engineering-Aufgaben sind zu einem entscheidenden Szenario im Wettbewerb großer Modelle geworden, da reale Entwicklungsabläufe in der Regel Anforderungsklärung, Code-Änderungen, Testrückmeldungen, Tool-Aufrufe, Versionsiterationen und mehrfache Zusammenarbeit umfassen. MiniMax gibt an, dass M3 in Benchmarks wie SWE-Bench Pro, Terminal-Bench 2.1, KernelBench Hard und MCP Atlas hohe Ergebnisse erzielt hat und das Modell durch ein Benutzersimulationsframework auf kontinuierliche Kollaborationsszenarien trainiert wurde. Diese Ausrichtung zeigt, dass MiniMax M3 seine Fähigkeiten nicht nur um das „Schreiben eines Codeabschnitts" herum verbessert, sondern versucht, die gesamte Entwicklungskette von Aufgabenzerlegung, Ausführung, Verifikation bis hin zu wiederholten Korrekturen abzudecken.
Multimodalität ist ebenfalls eine der Schlüsselfähigkeiten von MiniMax M3. Das Modell führt bereits in der frühen Trainingsphase gemischte modale Daten ein, sodass Text-, Bild- und Videoinformationen in einer einheitlichen Aufgabe gemeinsam verarbeitet werden können. In offiziellen Fallbeispielen wird MiniMax M3 für langlaufende Aufgaben wie die Reproduktion wissenschaftlicher Arbeiten, die Optimierung von CUDA-Operatoren und die Automatisierung von Modelltrainingsabläufen eingesetzt, was den kombinierten Wert von langem Kontext, Codierungsfähigkeit, Tool-Aufrufen und multimodalem Verständnis demonstriert. Für unternehmerische KI-Anwendungen bedeutet diese Kombinationsfähigkeit, dass das Modell gleichzeitig Dokumente lesen, Diagramme verstehen, Protokolle analysieren, Code generieren und Tools aufrufen kann. Die Grenzen von Agentenanwendungen erweitern sich so von „punktuellen Fähigkeiten" hin zur „ausführung über mehrere Schritte hinweg".
Die Einführung von MiniMax M3 spiegelt auch wider, dass sich der Wettbewerb bei großen chinesischen Modellen von reinen Modellparametern, Preisen und allgemeinen Dialogerfahrungen hin zu Fähigkeiten wie langem Kontext, Agentenausführung, Code-Engineering und multimodaler Fusion verlagert, die näher an der Produktionsumgebung sind. Da Unternehmen große Modelle in ihre Forschungs- und Entwicklungs-, Betriebs-, Kundenbetreuungs-, Büro- und Wissensmanagementprozesse integrieren, müssen Modellanbieter gleichzeitig Probleme in den Bereichen Leistung, Kosten, Kontextkapazität, Stabilität und Tool-Ökosystem lösen. Die Investitionen von MiniMax M3 in den Millionen-Kontext und die MSA-Architektur zeigen, dass langlaufende Aufgaben-Agenten zum neuen Brennpunkt des Wettbewerbs um die kommerzielle Umsetzung großer Modelle werden.
Dieser Artikel wurde von Wedoany übersetzt und bearbeitet. Bei jeglicher Zitierung oder Nutzung durch künstliche Intelligenz (KI) ist die Quellenangabe „Wedoany“ zwingend vorgeschrieben. Sollten Urheberrechtsverletzungen oder andere Probleme vorliegen, bitten wir Sie, uns unverzüglich zu benachrichtigen. Wir werden den entsprechenden Inhalt umgehend anpassen oder löschen.
E-Mail: news@wedoany.com