
de.wedoany.com-Bericht: GitHub hat einen internen KI-Analyse-Agenten namens Qubot eingeführt, der es Mitarbeitern ermöglicht, mit natürlicher Sprache beliebige Datenmodelle im Data Warehouse abzufragen und innerhalb von Sekunden Antworten zu erhalten.
Große Daten- und Analyseorganisationen haben oft Schwierigkeiten, einen Self-Service-Zugang zu Daten und Erkenntnissen zu ermöglichen. Bei GitHub gibt es intern Dutzende von Produktteams, und es ist eine Herausforderung, ihnen allen dedizierte Analyseunterstützung zu bieten. Daher müssen viele Teams ihre Datenanalyseprobleme selbst lösen. Obwohl eine große Menge wertvoller Produkt-Telemetriedaten für Entscheidungen zur Verfügung steht, ist es ohne die Unterstützung eines Datenanalysten stets schwierig, das zu verwendende Datenmodell, die Granularität und die Filter zu bestimmen, Abfragen zu schreiben und die Ergebnisse zu validieren.
Qubot, ein interner Analyse-Agent auf Basis von GitHub Copilot, ermöglicht es jedem Hubber (d. h. GitHub-Mitarbeiter), Fragen in natürlicher Sprache zu stellen, z. B. „Welche Nutzergruppe hat die höchste Bindungsrate bei dieser Funktion?" oder „Welches Produkt hat letzte Woche am meisten zur Steigerung dieser Kennzahl beigetragen?". Dieses Tool ersetzt keine Berichtswerkzeuge oder Dashboards, sondern eignet sich für explorative Fragen, hat null Wartungskosten und hilft Teams, sich schnell mit unbekannten Datensätzen vertraut zu machen.
Die Architektur von Qubot umfasst drei Hauptkomponenten: die Benutzeroberfläche, die Kontextebene und die Abfrage-Engine.
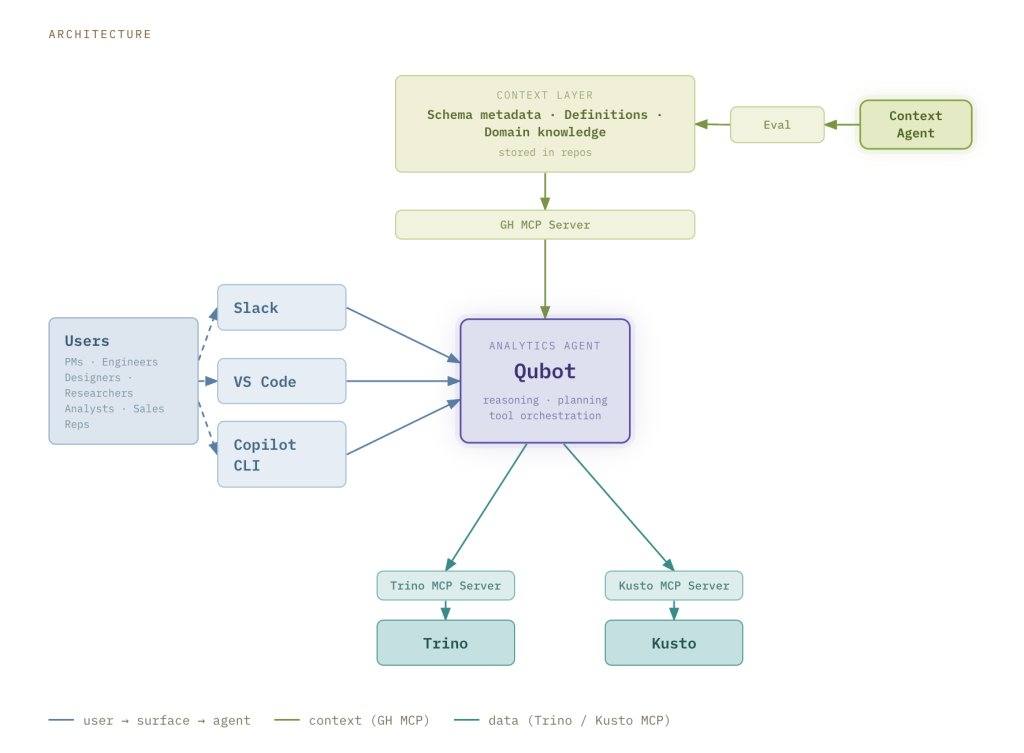
Die Benutzeroberfläche ist über Slack, VS Code und die Copilot CLI zugänglich. Die Slack-Oberfläche erfordert keine Konfiguration. Wenn jemand im Qubot-Slack-Kanal eine Frage stellt, wird eine Qubot-Instanz erzeugt, die Antwort direkt in Slack angezeigt, und die Nutzer können die Ergebnisse teilen und die Fragen iterativ verfeinern. Die Ergebnisse werden auch als Markdown-Berichte in Pull-Requests gespeichert. Qubot ist nach der Installation als Plugin in VS Code und der Copilot CLI sofort nutzbar.
Die Kontextebene ist föderiert aufgebaut, wobei das Wissen auf den Datentyp zugeschnitten ist. Für Rohdaten (Bronze-Ebene) gibt es Telemetriekontext, der von den Produktteams beigesteuert wird. Für Fakten- und Dimensionsdaten (Silber-Ebene) gibt es Abfragebeispiele und Nutzungsanleitungen, die vom Daten- und Analyseteam gepflegt werden. Für kuratierte Gold-Ebenen-Daten, die für spezifische Geschäftsanwendungsfälle erstellt wurden, gibt es Geschäftsregeln und Kennzahldefinitionen. ETL-Pipelines reichern die Kontextebene mit zusätzlichen Signalen und abgeleiteten Metadaten an. Zur Laufzeit wird sie über den GitHub MCP-Server geladen.
Kontext-Agenten vereinfachen den Beitrag zur föderierten Kontextebene. Teams können Kontext über standardisierte Vorlagen oder Referenz-Repositories beisteuern. Der Agent nimmt die Informationen auf, organisiert und normalisiert sie in ein strukturiertes Format. Jede Änderung an der Kontextebene oder der Agentenkonfiguration wird vor der Veröffentlichung durch ein Evaluierungs-Framework gemessen, das sorgfältig entworfene Testfälle, eine automatische Ausführungsorchestrierung und statistische Aggregationskomponenten umfasst, um die Antwortgenauigkeit und Latenz zu messen und Regressionsprobleme zu erfassen.
Die Abfrage-Engine verbindet sich über MCP-Server mit Kusto und Trino. Kusto ist schnell und eignet sich für explorative Abfragen aktueller Ereignisdaten; Trino verarbeitet komplexe Joins und tiefergehende historische Analysen. Qubot verwendet standardmäßig Kusto und wechselt bei Bedarf automatisch zu Trino.
Qubot wird bei GitHub bereits umfassend eingesetzt; Hunderte von Nutzern haben Tausende von Abfragen ausgeführt. Die Anzahl der Fragen in den Daten- und Analysekanälen ist drastisch zurückgegangen, und die Mitarbeiter können Daten eigenständiger erkunden. Die Kontextebene ist der Schlüssel zur Verbesserung der Copilot-Schlussfolgerungsfähigkeiten. Ein gut strukturierter Kontext macht Qubot nicht nur genauer, sondern kann auch die Geschwindigkeit, mit der korrekte Antworten zurückgegeben werden, verdreifachen.
Dieser Artikel wurde von Wedoany übersetzt und bearbeitet. Bei jeglicher Zitierung oder Nutzung durch künstliche Intelligenz (KI) ist die Quellenangabe „Wedoany“ zwingend vorgeschrieben. Sollten Urheberrechtsverletzungen oder andere Probleme vorliegen, bitten wir Sie, uns unverzüglich zu benachrichtigen. Wir werden den entsprechenden Inhalt umgehend anpassen oder löschen.
E-Mail: news@wedoany.com










