de.wedoany.com-Bericht: Forscher von Alibaba haben ein Framework namens SkillWeaver entwickelt, um das Problem der Tool-Routing von KI-Agenten bei mehrstufigen Aufgaben zu lösen. Durch eine kombinierte Skill-Routing-Methode reduziert dieses Framework den Token-Verbrauch um über 99 %.
Bei der Skalierung von Unternehmens-KI-Systemen müssen Agenten eine große Anzahl von Tools und Skills verarbeiten. Bestehende Einzel-Skill-Auswahlmethoden können Geschäftsanfragen, die eine mehrstufige Ausführung erfordern, wie z. B. „Datensatz herunterladen, Daten konvertieren und einen visuellen Bericht erstellen", nur schwer bewältigen. Das Forschungsteam definierte solche Probleme als „kombiniertes Skill-Routing", bei dem der Agent gleichzeitig bestimmen muss, wie eine Aufgabe zerlegt, wie Teilaufgaben auf Skills abgebildet und wie sie zu einem ausführbaren Plan kombiniert werden.
SkillWeaver realisiert diesen Prozess in drei Phasen: Zerlegung, Abruf und Kombination. In der Zerlegungsphase zerlegt ein großes Sprachmodell die Benutzeranfrage in eine Reihe von Teilaufgaben. In der Abrufphase wird ein Einbettungsmodell verwendet, um für jede Teilaufgabe eine Shortlist von Kandidaten-Tools aus der Skill-Bibliothek zu extrahieren. In der Kombinationsphase wird die Kompatibilität der Kandidaten-Tools bewertet und ein Ausführungsplan in Form eines gerichteten azyklischen Graphen erstellt. Das Forschungsteam führte außerdem die iterative skill-bewusste Zerlegung (Iterative Skill-Aware Decomposition, SAD) ein, bei der das große Sprachmodell durch eine Rückkopplungsschleife die Zerlegung basierend auf den zunächst abgerufenen Skill-Informationen umschreibt, um die Granularität an die Tool-Bibliothek anzupassen.
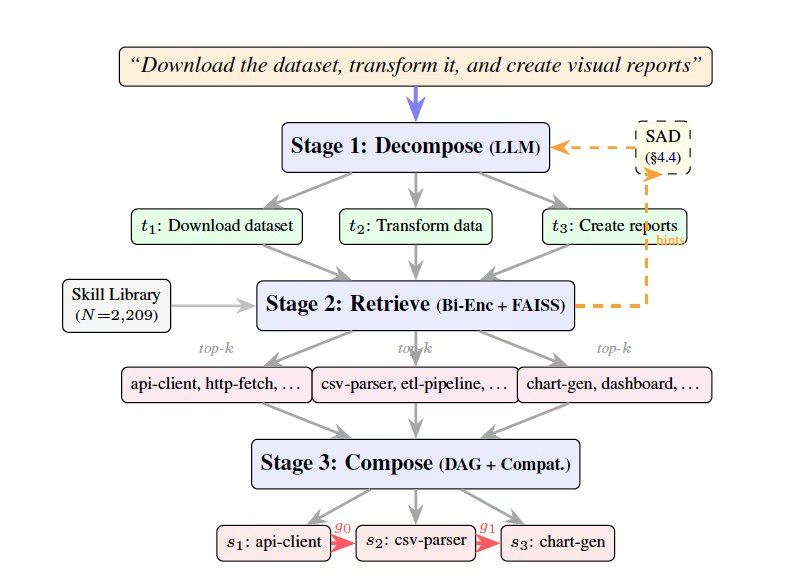
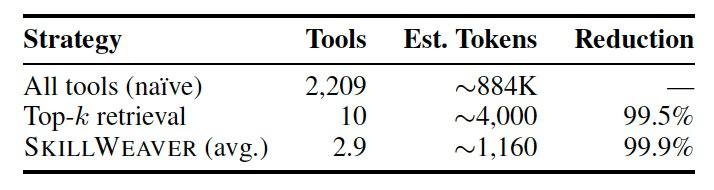
Zur Leistungsbewertung erstellten die Forscher den Benchmark CompSkillBench mit 300 mehrstufigen Abfragen und verwendeten eine Skill-Bibliothek mit 2.209 Skills aus dem öffentlichen MCP-Ökosystem, die 24 Funktionskategorien wie Cloud-Infrastruktur, Finanzen und Datenbanken abdeckt. Die Kern-Engine verwendete das Modell Qwen2.5-7B-Instruct zur Aufgabenzerlegung und den semantischen Such-Retriever MiniLM zum Auffinden von Tools. Experimente zeigten, dass die Zerlegungsgenauigkeit des 7B-Modells im normalen Setup ohne SAD bei 51,0 % lag, nach Aktivierung der SAD-Rückkopplungsschleife auf 67,7 % anstieg und das größere Modell Qwen-Max 92 % erreichte. Bei schwierigen Aufgaben, die vier bis fünf Skills erforderten, steigerte SAD die Genauigkeit um 50 %. Im Vergleich zur LLM-Direct-Methode, bei der alle Tools dem Modell ausgesetzt werden, verbesserte das Retrieval-Rerouting von SkillWeaver die Genauigkeit erheblich und reduzierte den Kontextfensterverbrauch pro Abfrage von etwa 884.000 Token auf etwa 1.160 Token, eine Reduzierung um 99,9 %.
Das Forschungsteam wies darauf hin, dass das Framework auf Basis fertiger Open-Source-Komponenten aufgebaut ist, darunter das Einbettungsmodell all-MiniLM-L6-v2 und der FAISS-Index. Die Einbettung und Indizierung der 2.209 Skills dauert nur 15 Sekunden. Entwickler können es mit Orchestrierungsbibliotheken wie LangChain oder LlamaIndex selbst implementieren. Derzeit fehlt der Ausführungsphase von SkillWeaver noch die Fehlerbehebungsfähigkeit; ein fehlgeschlagener API-Aufruf im zweiten Schritt führt zum Abbruch der Kette. Das Team empfiehlt, für den Produktionseinsatz eigene Fallback- und Wiederholungsmechanismen zu implementieren.