

de.wedoany.com-Bericht: Am 2. Juli wurde Version 2.0 des Open-Source-Projekts AReaL für verstärkendes Lernen (Infrastruktur) veröffentlicht. Ziel ist es, die Verbindung zwischen dem Training von Basismodellen und modernen Anwendungen intelligenter Agenten zu schließen und eine effiziente Unterstützung für das Training mit verstärkendem Lernen in Agent-Anwendungsszenarien zu bieten.
AReaL 2.0 richtet sich an Agenten, die bereits in realen Geschäftsszenarien eingesetzt werden, und bietet eine systemische Infrastruktur, die ihnen kontinuierliches Lernen während der Nutzung ermöglicht. Diese Version erlaubt es, die Interaktionsprozesse von Agenten bei der Erledigung realer Aufgaben aufzuzeichnen, aufzubereiten und in nachfolgende Trainingsabläufe einzubinden, um die zugrunde liegenden Modelle kontinuierlich zu optimieren. So werden die Agenten unter sicheren und kontrollierbaren Bedingungen mit zunehmender Nutzung immer leistungsfähiger.
Derzeit dringen Agenten in reale Produktionsumgebungen vor und erledigen komplexe Aufgaben wie das Schreiben von Code, das Recherchieren von Informationen und das Aufrufen von Tools. Obwohl Agenten täglich arbeiten, fällt es ihnen jedoch schwer, aus dieser Arbeit wirklich zu lernen. In realen Geschäftsabläufen generieren Agenten eine Vielzahl wertvoller Erfahrungen, wie z. B. den Erfolg von Aufgaben, die Gründe für fehlgeschlagene Tool-Aufrufe, die Benutzerzufriedenheit und die Entscheidungsrichtung. Diese Informationen werden meist nur in Form von Logs gespeichert und lassen sich nur schwer stabil und sicher in eine Leistungssteigerung für die nächste Iteration umwandeln.
AReaL 2.0 zielt darauf ab, das Problem zu lösen, wie Agenten nach ihrer Inbetriebnahme weiter wachsen können. Entwickler müssen den Agenten nicht neu entwickeln; es genügt, die Anfragen, die der Agent ursprünglich an das große Sprachmodell sendet, über die einheitliche Inferenzschnittstelle von AReaL 2.0 zu leiten, um sie in den Online-Verstärkungslernprozess einzubinden.
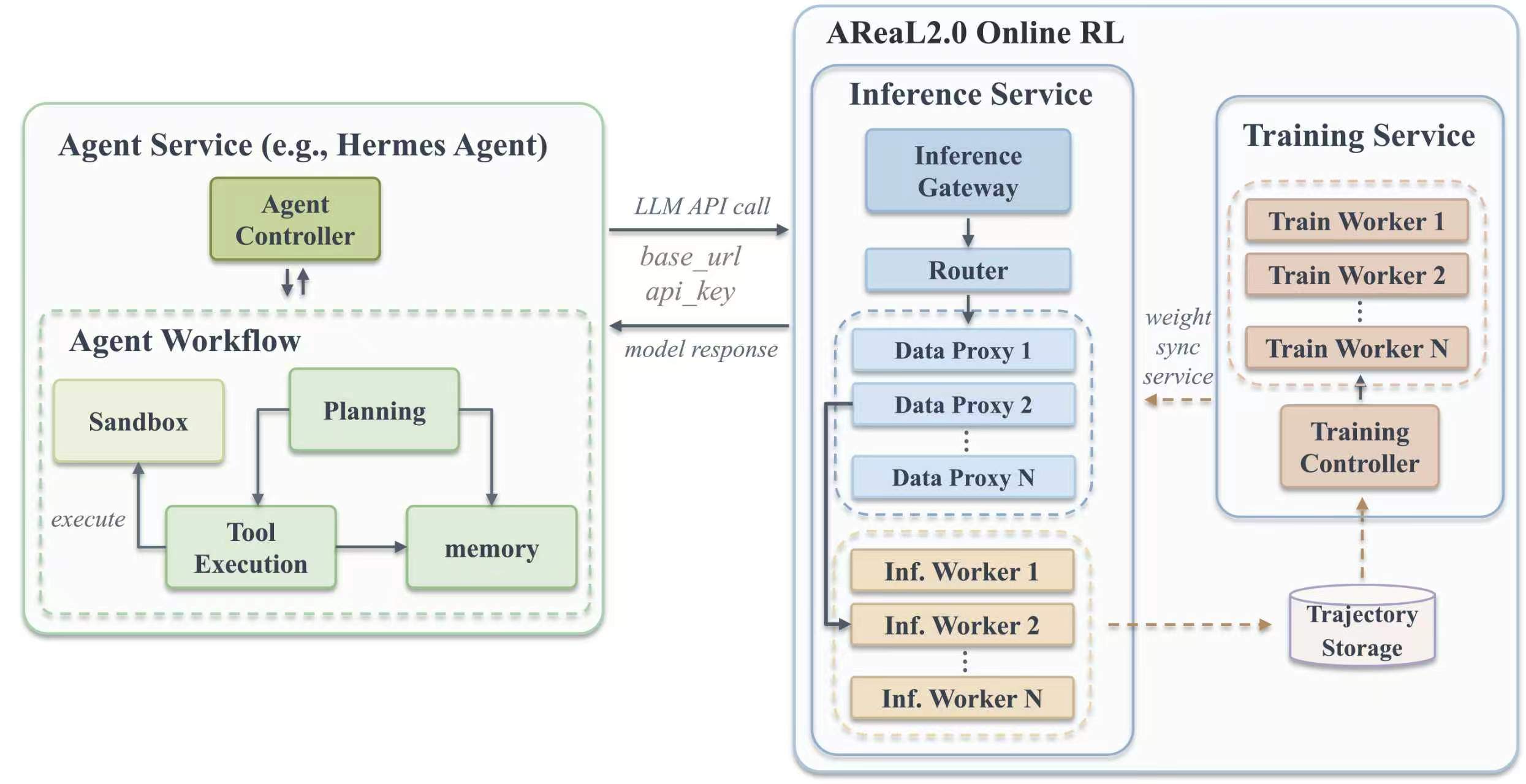
Am Beispiel von Hermes Agent: Hermes empfängt normal Aufgaben, plant Schritte und ruft Modelle auf. AReaL 2.0 zeichnet im Hintergrund die wichtigsten Interaktionsprozesse bei der Aufgabenerfüllung auf und kombiniert diese mit dem Feedback oder Belohnungssignal nach Abschluss der Aufgabe, um diese realen Trajektorien für das anschließende Training zu nutzen. Entwickler können Hermes durch ihren eigenen Agenten und ihre Aufgabenumgebung ersetzen, um auf die gleiche Weise einen Online-Verstärkungslernprozess für Agenten aufzubauen. Dies bedeutet, dass die Leistungssteigerung von Agenten nicht mehr ausschließlich auf manuell konstruierte Daten, Offline-Training und erneute Bereitstellung angewiesen ist. Mehrrunden-Dialoge, Tool-Aufrufe, Ausführungsergebnisse und Feedback-Signale aus realen Aufgaben können alle zu Lernmaterial für das Modell werden.
Dies ist besonders in Unternehmensszenarien wichtig. Agenten in Unternehmensworkflows stehen vor realen, komplexen und sich ständig ändernden Aufgaben, darunter Code-Bibliotheks-Updates, Anpassungen von Geschäftsprozessen, sich ändernde Benutzeranforderungen sowie Änderungen an Tools und Systemen. Wenn die Fähigkeiten eines Agenten nach der Inbetriebnahme weitgehend statisch bleiben, kann er sich nur schwer langfristig an die reale Umgebung anpassen. AReaL 2.0 zielt darauf ab, die fehlende Verbindung zwischen dem „Werkzeuge verwenden können" und dem „aus der Nutzung lernen können" zu schließen.
Gleichzeitig kann kontinuierliches Lernen in realen Geschäftsabläufen nicht einfach „Daten sammeln und neu trainieren" bedeuten. Agenten können mit Code, Kundeninformationen, Unternehmenswissensdatenbanken und internen Systemen in Kontakt kommen. Daher müssen bei der Trainingskette Anforderungen wie Zugriffskontrolle, Datenschwärzung, Isolierung und Prüfung berücksichtigt werden. AReaL 2.0 führt im Systemdesign einen Datenvermittlungsmechanismus für Agent-Trajektorien ein, der eine sicherere und kontrollierbarere Verwaltung und Nutzung realer Aufgabendaten ermöglicht, wenn diese in den Trainingsprozess einfließen.
Das AReaL-Team weist in seinem technischen Bericht darauf hin, dass der entscheidende Engpass für sich selbst weiterentwickelnde Agenten nicht nur im Modell selbst oder im Verstärkungslernalgorithmus liegt, sondern vor allem im Fehlen einer Online-Verstärkungslern-Infrastruktur, die reale Agenten bedienen kann. AReaL 2.0 wurde für die nächste Generation von Agentenanwendungen architektonisch aufgerüstet und verbindet Agent-Dienste, reale Aufgabentrajektorien, Datenverwaltung und Online-Verstärkungslern-Training. Damit bietet es eine umsetzbare technische Grundlage für das weitere Lernen von Agenten nach der Bereitstellung.
Das AReaL-Projekt wurde 2024 von Teams der Ant Group, der Tsinghua-Universität und der Hong Kong University of Science and Technology ins Leben gerufen. Im Mai 2026 wurde AReaL von Ant InclusionAI als unabhängige Open-Source-Community ausgegründet und trat dem PyTorch Foundation Ecosystem-Projekt bei, um sich in das Ökosystem der Mainstream-Verstärkungslern-Infrastruktur zu integrieren. Mit der unabhängigen Entwicklung der Community erhält AReaL weiterhin Beteiligung und Unterstützung von Industrie- und Open-Source-Ökosystempartnern, darunter das Huawei Cloud Team und MindLab. In Zukunft wird sich AReaL auf Bereiche wie Online-Verstärkungslernen, automatisierte Bewertung und multimodales Agenten-Training konzentrieren und gemeinsam mit der Community die Entwicklung eines Ökosystems sich selbst weiterentwickelnder Agenten vorantreiben. Der technische Bericht und der Code von AReaL 2.0 sind derzeit als Open Source verfügbar.










