de.wedoany.com-Bericht: Die Chinesische Volksuniversität hat gemeinsam mit Microsoft Research das Arbor-Framework entwickelt, das die autonome Optimierung von KI-Systemen von einem Trial-and-Error-Prozess in einen kumulativen Lernmechanismus verwandelt. Durch strukturiertes Hypothesenmanagement erzielt das Framework bei realen Ingenieuraufgaben eine nachweisbare Leistungssteigerung von mehr als dem 2,5-Fachen.

Mit der zunehmenden Leistungsfähigkeit großer Sprachmodelle und KI-Systeme wird die autonome Optimierung zu einer zentralen Herausforderung. Bei der Optimierung von KI-Agenten müssen Ingenieurteams häufig mehrere Parameter gleichzeitig anpassen, darunter Chunking-Strategien, Retrieval-Methoden und System-Prompts. Diese Anpassungen sind miteinander verflochten und lassen sich nur schwer präzise zuordnen, was den Optimierungsprozess ineffizient macht. Der Koautor der Studie, Jiajie Jin, weist darauf hin, dass es nicht zu besseren Ergebnissen führe, wenn man Codierungsagenten einfach mehr Zeit oder Rechenressourcen gebe: „Wenn die Ziele vage sind oder Metriken leicht manipuliert werden können, führen längere Laufzeiten meist nur schneller zu ‚Verbesserungen‘, die niemand wirklich will.“
Bestehende Codierungsagenten verlassen sich auf Gesprächsverläufe als Gedächtnis, doch autonome Optimierungsaufgaben umfassen hunderte Interaktionsrunden, die leicht die Grenzen des Kontextfensters überschreiten. Agenten haben Schwierigkeiten, faktische Belege über lange Verläufe hinweg zu bewahren, verlieren die Gesamtstruktur des Forschungsprozesses und bleiben entweder an frühen Fehlschlägen hängen oder jagen verrauschten Bewertungsschwankungen hinterher. Gleichzeitig organisieren allgemeine Frameworks die Werkzeugaufrufketten in einem gemeinsamen Arbeitsbaum, was das Testen paralleler Hypothesen in isolierten Umgebungen unmöglich macht.
Arbor löst diese Herausforderung durch eine Trennung von Koordinator und Ausführer: Der Koordinator fungiert als Hauptforscher, der den Gesamtzustand der Optimierungsstudie verwaltet, Hypothesen aufstellt und die Experimentrichtung bestimmt, ohne direkt in die Codebasis einzugreifen. Die Ausführer sind kurzlebige Agenten, die spezifische Hypothesen in unabhängigen Git-Arbeitsbäumen testen. Beide Komponenten arbeiten über den Mechanismus der „Hypothesenbaum-Verfeinerung“ zusammen, der den Forschungsprozess als persistenten Verzweigungsbaum darstellt. Jeder Knoten ist mit einer Hypothese, ausführbaren Artefakten, faktischen Belegen und destillierten Erkenntnissen verknüpft. Der Koordinator platziert breite Ideen im Wurzelknoten und konkrete Verfeinerungen in den Blattknoten, sodass mehrere konkurrierende Richtungen gleichzeitig erkundet werden können. Fehlgeschlagene Experimente werden als negative Einschränkungen aufgezeichnet, um zu verhindern, dass das System dieselben Fehler wiederholt.
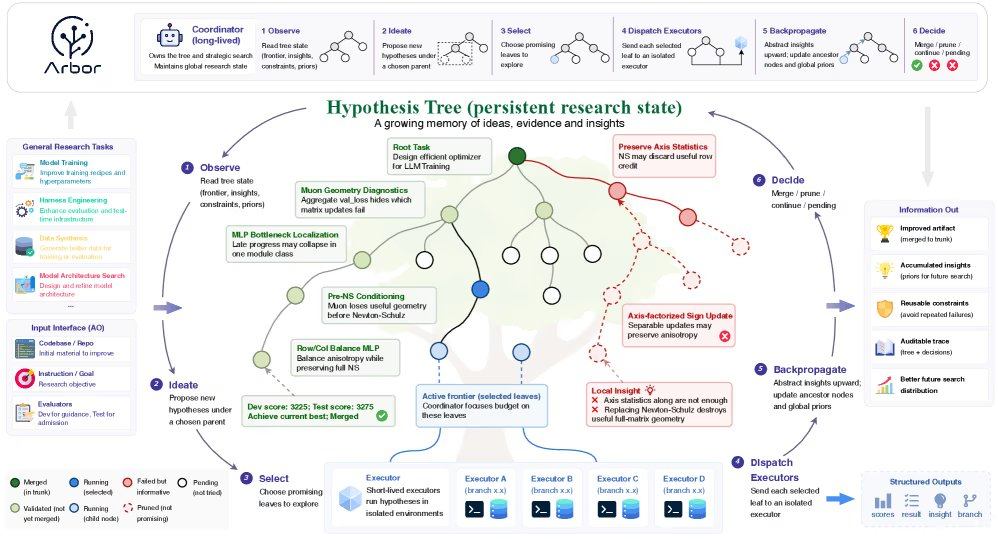
In realen Ingenieurszenarien erzielt Arbor durch die Behandlung jedes Optimierungshebels als separate Hypothese eine klare Attributzuschreibung. Nachdem der Ausführer einen Bericht zurückgegeben hat, schreibt der Koordinator die Belege in den Baum und propagiert die Erkenntnisse zurück zum Elternknoten. Um Überanpassung zu verhindern, erzwingt das Framework ein „Merge-Gate“, das Kandidatenlösungen in unabhängigen Arbeitsbäumen testet und sie nur dann in den aktuell besten Hauptzweig einfügt, wenn sie die zurückgehaltenen Testwerte verbessern.
Die Forscher evaluierten Arbor anhand einer Suite autonomer Optimierungsaufgaben auf Basis realer Forschungsumgebungen sowie des Machine-Learning-Engineering-Benchmarks MLE-Bench Lite. Die AO-Suite umfasst Aufgaben wie Modelltraining, Framework-Engineering und Datensynthese. Bei Verwendung von Backbone-Modellen wie Claude Opus 4.6, GPT-5.5 und Gemini-3-Flash erzielte Arbor einen durchschnittlichen relativen Gewinn, der mehr als 2,5-mal so hoch war wie der von Codex und Claude Code. Bei der Optimierung des Suchagenten in der BrowseComp-Aufgabe steigerte Arbor die zurückgehaltene Systemgenauigkeit von 45,33 % auf 67,67 %, während Codex und Claude Code bei 50 % bzw. 53,33 % stagnierten. Auf MLE-Bench Lite erzielte Arbor mit GPT-5.5 die stärksten Ergebnisse.
Arbor zeigt Widerstandsfähigkeit gegenüber Überanpassung. Im Terminal-Bench-2.0-Experiment erreichte Claude Code einen Entwicklungswert von 75, fiel jedoch bei den zurückgehaltenen Daten auf 71 zurück; Arbor erzielte mit 72,22 einen niedrigeren Entwicklungswert, aber mit 77,36 den höchsten zurückgehaltenen Wert. Experimente zur Aufgabenübertragung zeigten, dass die nach der Optimierung des BrowseComp-Suchframeworks erstellte Codebasis die Leistung bei den nicht verwandten Aufgaben HLE und DeepSearchQA signifikant verbesserte.
Das Framework ist so konzipiert, dass es auf bestehenden Git-Workflows aufbaut. Jin erklärt, dass Arbor gewöhnliche Git-Branches ausgibt, die von bestehenden Code-Reviews und manuellen Prüfungen direkt überprüft werden können. Die Hauptkosten beim Einsatz entstehen durch den Token-Verbrauch für die Aufrechterhaltung des Koordinators und die Verwaltung des Baums sowie durch den Rechen- und Speicherressourcenbedarf mehrerer isolierter Arbeitsbäume. Das Framework eignet sich für Aufgaben mit klaren, vertrauenswürdigen Metriken, die lange Zeiträume tolerieren und mehrere sinnvolle Suchrichtungen aufweisen, wie z. B. Pipeline-Optimierung, Qualität der Datensynthese und Optimierung des Modelltrainings. Es sollte nicht für Echtzeit-Latenzaufgaben, einfache Reparaturen oder Szenarien mit fehlerhaften Bewertungsmetriken verwendet werden. Jin sieht den nächsten Entwicklungsschritt darin, die Artefakte jedes Knotens von einem einzelnen Skalarwert auf eine mehrdimensionale Pareto-Suche umzustellen, die Genauigkeit, Latenz und Kostenvektoren umfasst.
Dieser Artikel wurde von Wedoany übersetzt und bearbeitet. Bei jeglicher Zitierung oder Nutzung durch künstliche Intelligenz (KI) ist die Quellenangabe „Wedoany“ zwingend vorgeschrieben. Sollten Urheberrechtsverletzungen oder andere Probleme vorliegen, bitten wir Sie, uns unverzüglich zu benachrichtigen. Wir werden den entsprechenden Inhalt umgehend anpassen oder löschen.
E-Mail: news@wedoany.com