de.wedoany.com-Bericht: Forscher des Shanghai Artificial Intelligence Laboratory haben ein neues Paradigma namens „Self-Harness“ vorgestellt, das es auf großen Sprachmodellen (LLMs) basierenden Agenten ermöglicht, ihre eigenen Betriebsregeln systematisch zu verbessern, ohne auf menschliche Ingenieure oder leistungsstärkere externe Modelle angewiesen zu sein.
Die Leistung von LLM-basierten Agenten hängt nicht nur vom Basismodell ab, sondern auch von ihrem Framework, das System-Prompts, Werkzeuge, Gedächtnis, Validierungsregeln, Laufzeitstrategien, Orchestrierungslogik und Fehlerbehebungsprozeduren umfasst. Häufige Agentenfehler sind oft auf das Framework und nicht auf das Modell selbst zurückzuführen. Beispielsweise könnte ein Agent einen Erfolg melden, ohne die Modellantwort zu überprüfen, oder fehlgeschlagene Vorgänge wiederholt versuchen. SWE-agent, Claude Code, Codex und OpenHands sind gängige Beispiele für Frameworks.
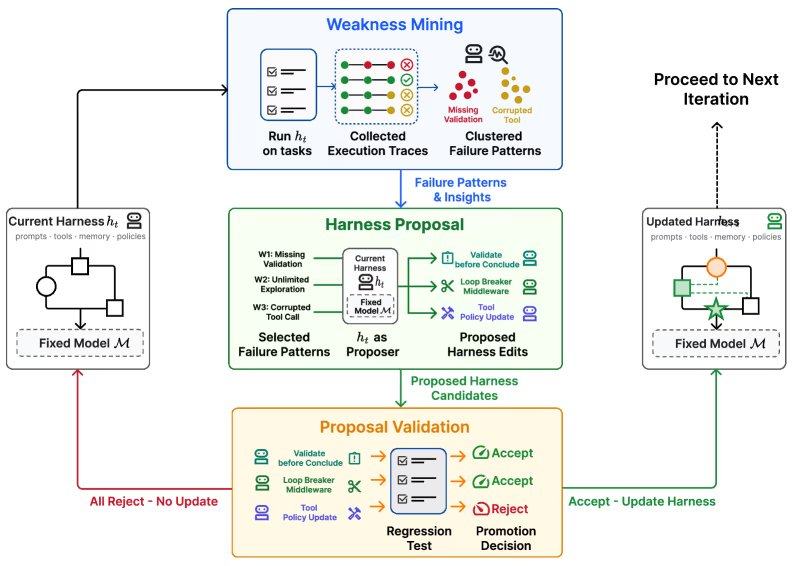
Hangfan Zhang, Erstautor der Self-Harness-Studie, erklärte, dass der eigentliche Engpass des manuellen Framework-Engineerings in der Abhängigkeit von Ad-hoc-Debugging und nicht von systematischen Feedbackschleifen liege. Viele Änderungen basierten auf Intuition oder wenigen Fehlerfällen und könnten mit der sich schnell entwickelnden LLM-Landschaft kaum Schritt halten. Das Self-Harness-Paradigma ermöglicht es LLM-basierten Agenten, sich durch einen dreistufigen iterativen Zyklus selbst zu verbessern.
Der Zyklus beginnt mit der Schwachstellenanalyse: Der Agent führt Aufgaben aus, erzeugt Ausführungsspuren, klassifiziert fehlgeschlagene Spuren und erkennt modellspezifische Fehlermuster. Es folgt die Framework-Vorschlagsphase: Der Agent nutzt die Rolle des „Vorschlagenden“, um eine Reihe vielfältiger und minimaler Framework-Änderungen zu generieren, die jeweils auf einen bestimmten Fehlermechanismus abzielen. Die letzte Phase ist die Vorschlagsvalidierung: Das System bewertet die Kandidatenänderungen durch Regressionstests und übernimmt sie nur, wenn die Bearbeitung nicht zu einer Leistungsverschlechterung bei den beibehaltenen Aufgaben führt. Bestehen mehrere Kandidaten die Tests, werden sie in der nächsten Framework-Version zusammengeführt.
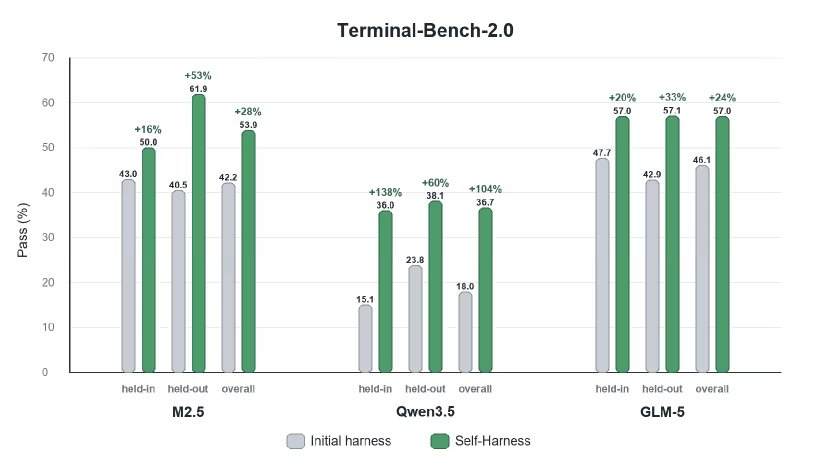
Die Forscher evaluierten Self-Harness auf dem Terminal-Bench-2.0-Benchmark, der werkzeugbasierte Ausführungen testet, darunter Artefaktverwaltung, Befehlsnutzung, Validierungsverhalten und die Wiederherstellung nach Ausführungsfehlern. Sie wandten Self-Harness auf MiniMax M2.5, Qwen3.5-35B-A3B und GLM-5 an. Die quantitativen Ergebnisse zeigten, dass die Agenten durch automatisierte Framework-Bearbeitungen ihre Leistung verbesserten, mit relativen Verbesserungen zwischen 33 % und 60 % bei den beibehaltenen Aufgaben, je nach Modell.
Die Experimente zeigten, dass Self-Harness gezielte Änderungen einführte, die die wiederkehrenden Probleme jedes Modells während der Ausführung widerspiegelten. Beispielsweise durchsuchte MiniMax M2.5 unter dem Basis-Framework endlos Datenkonfigurationen, bis ein Timeout eintrat. Das System behob dies durch die Implementierung einer „Schleifenunterbrechungs“-Regel (Stopp nach 50 Tool-Aufrufen und Umleitung der Methode) sowie durch die Anforderung, frühzeitig eine erste Version zu erstellen. Qwen-3.5 wiederholte denselben Befehl nach Dateiüberschreibungsfehlern; das System führte eine strenge Wiederholungsdisziplin (vollständige Wiederholungen von Befehlen verboten) sowie einen Mechanismus zur sofortigen Neuerstellung verlorener Artefakte nach Dateifehlern ein. GLM-5 hatte Schwierigkeiten, Umgebungsänderungen zwischen verschiedenen Befehlen beizubehalten; sein selbstgeneriertes Framework führte Regeln zur Persistenz der PATH-Variablen, zur Einschränkung externer Berechnungen und zur Behebung fehlgeschlagener Integritätsprüfungen vor dem Ende der Ausführung ein.
Zhang wies darauf hin, dass automatisiertes Framework-Engineering Rechenaufwand für wiederholte Generierung, parallele Evaluierung und Regressionstests erfordert. Das System ist zudem auf die Genauigkeit der Evaluierungspipeline angewiesen und stützt sich in den Experimenten auf strenge, deterministische Validatoren. Seiner Ansicht nach sind die besten Einsatzziele Bereiche wie Codierung, interne Workflow-Automatisierung und DevOps-Datenpipelines, in denen Fehler messbar und Versuche relativ sicher sind. Bereiche wie medizinische Entscheidungen, sicherheitskritische Infrastruktur oder rechtliche Entscheidungen, in denen Evaluierungen subjektiv und kostspielig sind, sollten hingegen vollständig automatisierte Ansätze vermeiden. Mit zunehmender Leistungsfähigkeit der Basismodelle werden Frameworks nach außen expandieren und reichhaltigere externe Umgebungen anbinden. Die Rolle der Ingenieure wird sich von der manuellen Anpassung einzelner Prompts oder Tool-Aufrufe hin zum Design von Feedbacksystemen verlagern, die Agentenverbesserungen ermöglichen.
Dieser Artikel wurde von Wedoany übersetzt und bearbeitet. Bei jeglicher Zitierung oder Nutzung durch künstliche Intelligenz (KI) ist die Quellenangabe „Wedoany“ zwingend vorgeschrieben. Sollten Urheberrechtsverletzungen oder andere Probleme vorliegen, bitten wir Sie, uns unverzüglich zu benachrichtigen. Wir werden den entsprechenden Inhalt umgehend anpassen oder löschen.
E-Mail: news@wedoany.com