
de.wedoany.com-Bericht: In Zusammenarbeit mit der National University of Singapore, der Shanghai Jiao Tong University, dem Institut für Automatisierung der Chinesischen Akademie der Wissenschaften und der Fudan-Universität hat Tashizhihang auf einer Preprint-Plattform die Arbeit „TacForeSight: Force-Guided Tactile World Model for Contact-Rich Manipulation“ veröffentlicht. Die Studie stellt ein kraftbedingtes taktiles Weltmodell vor, das erstmals Handgelenkskraftsignale als Leitinformationen für zukünftige taktile Zustände nutzt, um kurzzeitige Kontaktentwicklungen vorherzusagen und die Vorhersagen in den Bewegungsgenerierungsprozess von Robotern einzubeziehen.
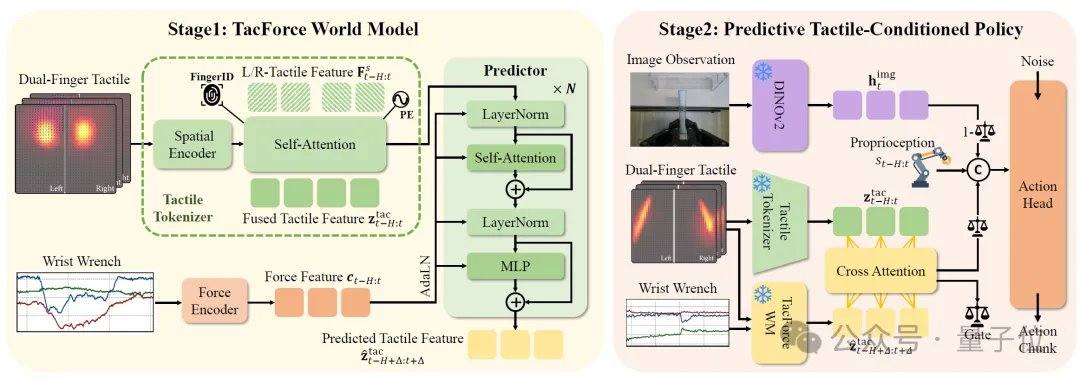
Bei kontaktintensiven Manipulationen wie Abwischen, Stecken und Festziehen ändern sich die Kontaktzustände kontinuierlich über die Zeit. Kraftabweichungen und Positionsänderungen können leicht zu Aufgabenfehlern führen. Bestehende Methoden verlassen sich meist auf nachträgliche Anpassungen durch Rückmeldungssignale. Der Kernansatz von TacForeSight besteht darin, die zeitliche Abfolge von Kraft- und Tastsinn zu erkennen: Die Handgelenkskraft liefert ein Leitsignal für den gesamten Kraftverlauf, während der Tastsinn lokale Kontaktdetails widerspiegelt. Basierend darauf entwickelte das Team das Kernmodul TacForceWM, das das taktile Feld zweier Finger in kompakte latente taktile Variablen kodiert und hochfrequente Handgelenkskraft- oder Drehmomentsignale nutzt, um die kurzzeitige taktile Entwicklung vorherzusagen. Dies reduziert den Rechenaufwand für die Erzeugung hochdimensionaler taktiler Bilder und nutzt die Vorhersageinformationen für die Generierung leichtgewichtiger Bewegungsstrategien.

Nach der Vorhersage des zukünftigen taktilen Zustands modelliert das System über die Predictive Tactile-Conditioned Policy mittels eines Cross-Attention-Mechanismus explizit die Beziehung zwischen aktuellem Kontakt und zukünftigen Trends, sodass die Bewegungsgenerierung sowohl den aktuellen Kontakt als auch bevorstehende Kontaktänderungen berücksichtigt. Gleichzeitig passt ein taktil gesteuerter adaptiver Gating-Mechanismus dynamisch die Gewichtung von visuellen und taktilen Informationen je nach Aufgabenphase an: In kontaktintensiven Phasen liegt der Schwerpunkt auf der taktilen Steuerung, während in Phasen ohne Kontakt auf visuelle Informationen zurückgegriffen wird.
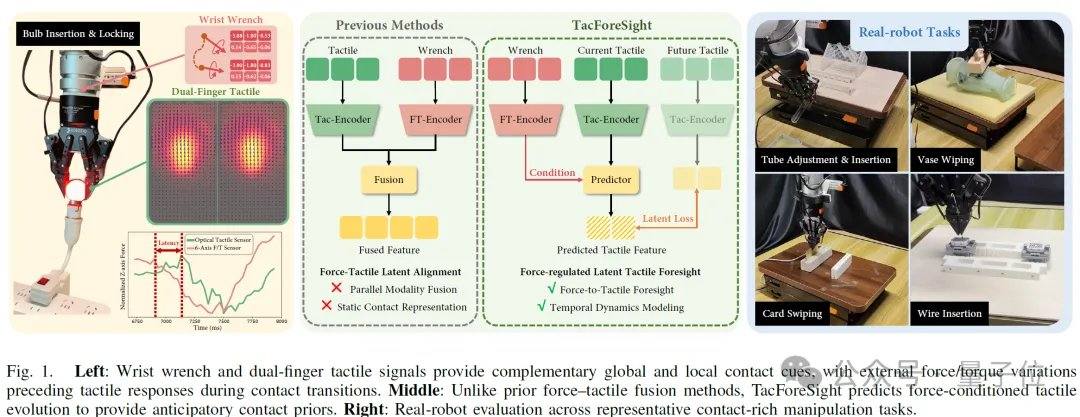
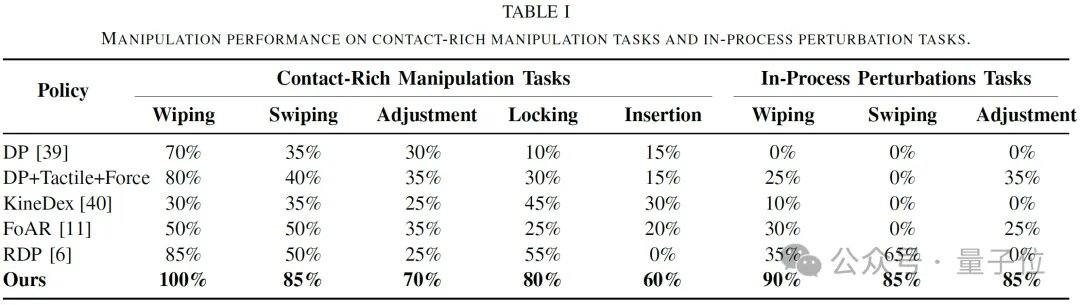
Die Experimente wurden auf einer realen Roboterplattform durchgeführt, die einen Roboterarm, einen Greifer, eine Kamera, einen sechsachsigen Kraft-/Drehmomentsensor und einen taktilen Zweifingersensor umfasst. Fünf typische kontaktintensive Aufgaben wurden abgedeckt: Abwischen einer Vase, Schieben einer Karte, Einführen eines Rohrs, Festziehen einer Glühbirne und Einführen eines flexiblen Kabelbaums. Die Ergebnisse zeigen eine durchschnittliche Erfolgsrate von nahezu 80 % bei Standardaufgaben, was reine visuelle Modelle, einfache visuell-taktil-kraftbasierte Fusionen sowie Baseline-Methoden wie KineDex, FoAR und RDP übertrifft. Unter dynamischen Störungen wie Höhen-, Winkel- und Haltungsänderungen lagen die Erfolgsraten bei 90 %, 85 % bzw. 85 %, im Durchschnitt bei 86,7 %. Das Modell unterstützt Echtzeit-Inferenz mit 20 Hz und kann in hochfrequente Roboterrückkopplungsregelungen integriert werden.

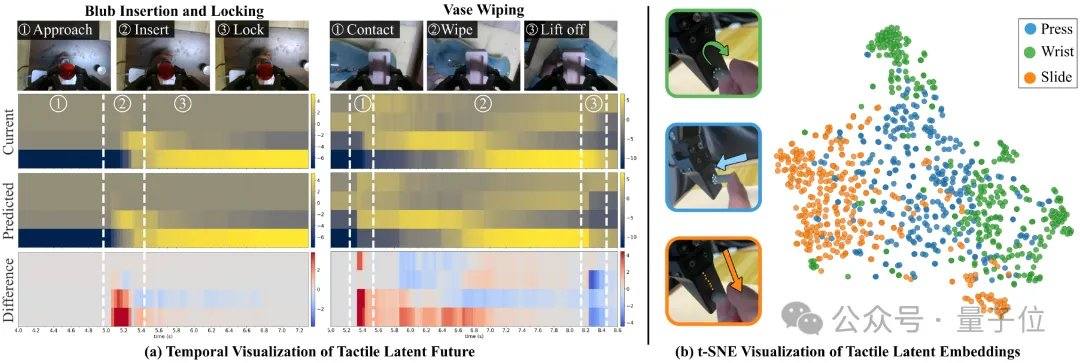
Die Visualisierung latenter Variablen zeigt, dass bei den Aufgaben „Glühbirne festziehen“ und „Vase abwischen“ die vorhergesagten latenten taktilen Variablen etwa 200 Millisekunden früher kontaktbezogene Änderungen aufweisen als die aktuellen latenten taktilen Variablen. Bei ungesehenen Kraft-Tastsinn-Interaktionssequenzen wie Drücken, Drehen und Gleiten bilden die vom taktilen Encoder extrahierten latenten Variablen in der t-SNE-Visualisierung trennbare Cluster, was auf die Fähigkeit des Modells zur Unterscheidung von Kontaktmustern hinweist. Dies ist ein weiterer Fortschritt von Tashizhihang im Bereich der Feinmanipulation; bereits im März hatte das Unternehmen das visuell-taktile Manipulationsframework OmniVTA und den groß angelegten visuell-taktilen Datensatz OmniViTac veröffentlicht, um Robotern das Verständnis von Kontakt durch Sehen und Tasten zu ermöglichen.
Dieser Artikel wurde von Wedoany übersetzt und bearbeitet. Bei jeglicher Zitierung oder Nutzung durch künstliche Intelligenz (KI) ist die Quellenangabe „Wedoany“ zwingend vorgeschrieben. Sollten Urheberrechtsverletzungen oder andere Probleme vorliegen, bitten wir Sie, uns unverzüglich zu benachrichtigen. Wir werden den entsprechenden Inhalt umgehend anpassen oder löschen.
E-Mail: news@wedoany.com










