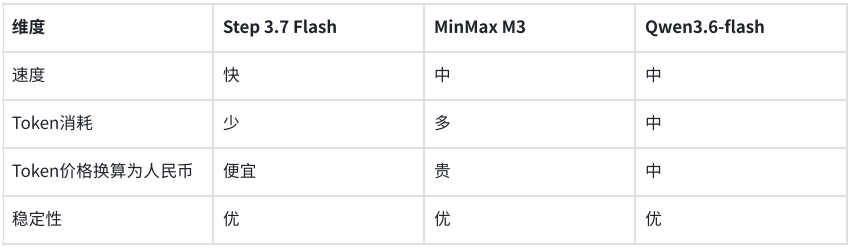
de.wedoany.com-Bericht: Vor dem Hintergrund, dass multimodale Modelle von der Demonstration zur Produktionseinführung übergehen, wurden die drei Modelle Step 3.7 Flash, Qwen3.6-flash und MiniMax M3 in Entwicklungs- und Geschäftsszenarien einem Praxistest unterzogen. Ein Vergleichstest, der sich auf die beiden Aufgaben Flussdiagrammerkennung und Beleganalyse konzentrierte, zeigte, dass die Qualität der drei Modelle in Bezug auf visuelles Verständnis und strukturierte Ausgabe relativ stabil war, es jedoch Unterschiede in der Antwortgeschwindigkeit und im Token-Verbrauch gab.
Der Test bewertete die drei Dimensionen Qualität, Geschwindigkeit und Kosten und wählte zwei Arten von Industrieszenarien aus: Erstens die Rekonstruktion von Geschäftslogiken basierend auf Systemflussdiagrammen während der Agententwicklung, und zweitens die strukturierte Extraktion von Rechnungsinformationen über API-Aufrufe in Geschäftssystemen. Die Tests zeigten, dass keines der drei Modelle bei den beiden Aufgaben schwerwiegende Fehlerkennungen aufwies und die Ausgabe eine hohe Nutzbarkeit aufwies.
Im Szenario des Flussdiagrammverständnisses musste das Modell basierend auf einem Flussdiagramm zur Anmeldung und Authentifizierung eines WeChat-Miniprogramms die Geschäftslogik von 10 Schritten genau extrahieren. Step 3.7 Flash erkannte alle 10 Schritte vollständig, wobei jeder Schritt logisch perfekt mit dem ursprünglichen Flussdiagramm übereinstimmte. MiniMax M3 gab ebenfalls 10 Schritte aus, die Logik war korrekt. Qwen3.6-flash fasste die Schritte 3 und 4 zusammen und gab 9 Schritte aus, aber die Gesamtlogik war fehlerfrei. Bei vergleichbarer Ausgabequalität hatte Step 3.7 Flash die schnellste Antwortgeschwindigkeit und den niedrigsten Token-Verbrauch.
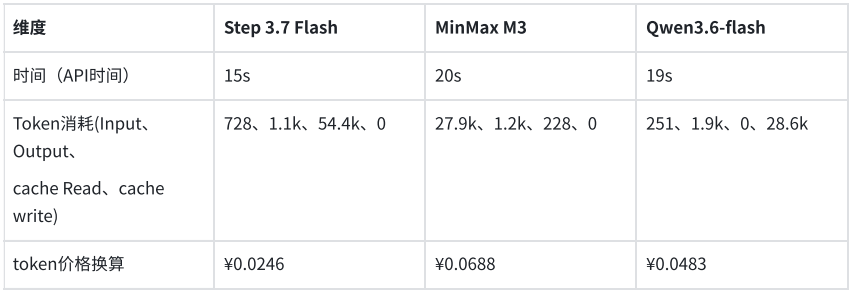
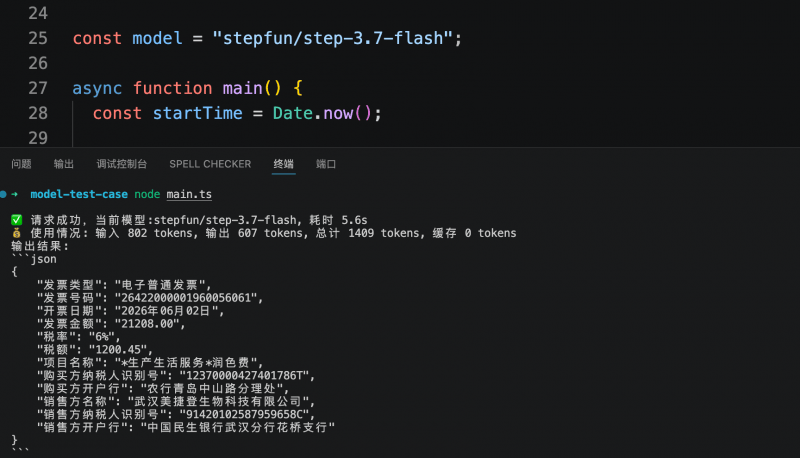
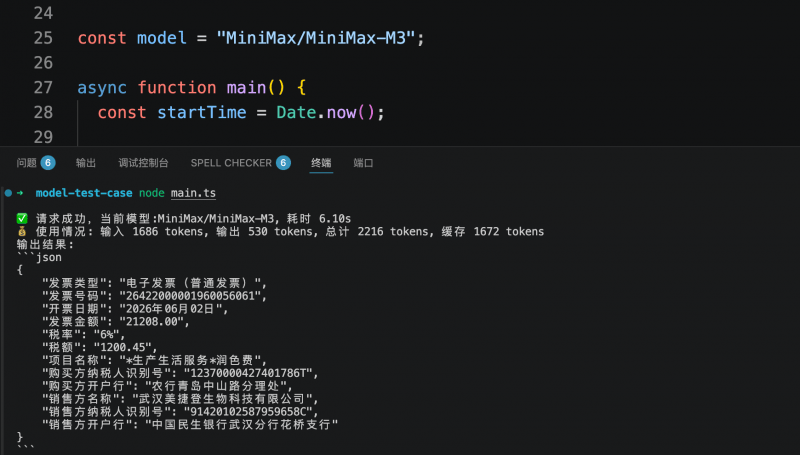
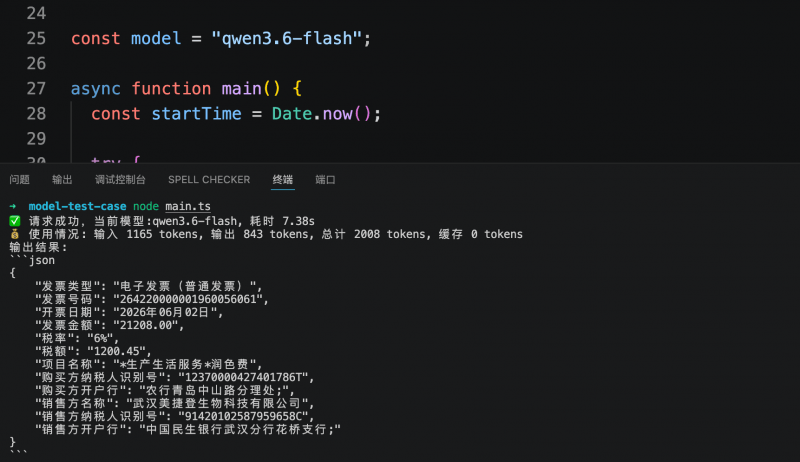
In einem weiteren Test für Geschäftssysteme musste das Modell die Schlüsselfelder einer elektronischen Rechnung gemäß einer vorgegebenen JSON-Struktur ausgeben. Alle drei Modelle konnten die benötigten Informationen genau erkennen und strukturiert ausgeben. Step 3.7 Flash benötigte für diese Aufgabe 5,6 Sekunden und verbrauchte 1409 Tokens; MiniMax M3 benötigte 6,1 Sekunden und verbrauchte 2216 Tokens; Qwen3.6-flash benötigte 7,38 Sekunden und verbrauchte 2008 Tokens. Die Kosten für die strukturierte Extraktion eines einzelnen Belegs lagen unter 1 Cent.
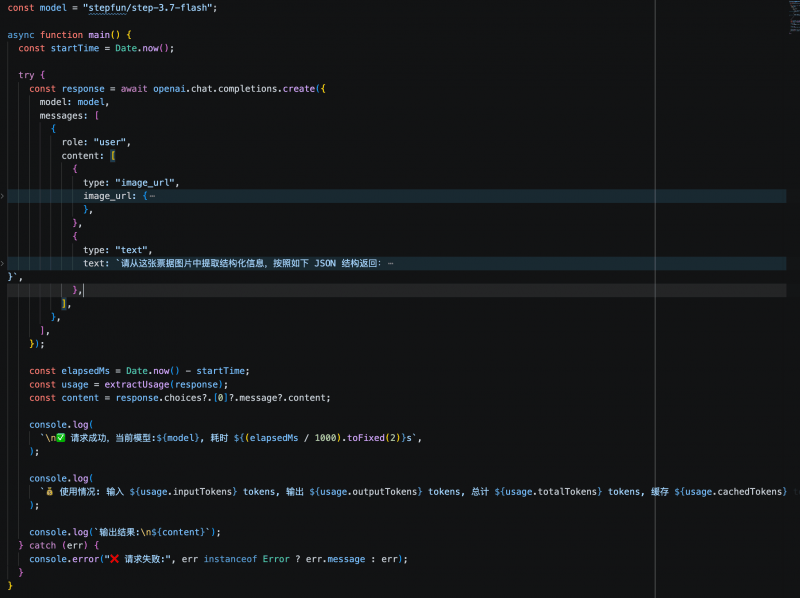

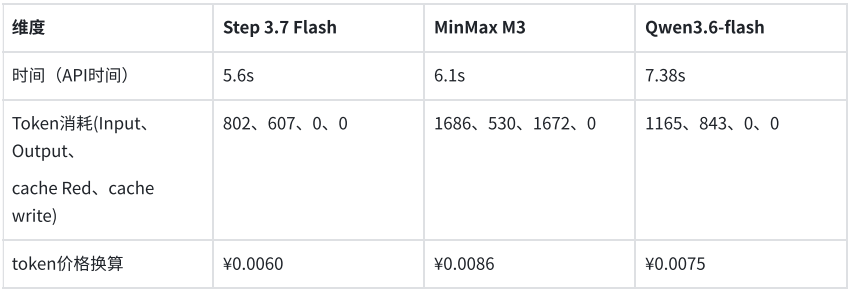
Zusammenfassend lässt sich sagen, dass die Qualitätsstabilität der drei Modelle in Bezug auf visuelles Verständnis und strukturierte Ausgabe in beiden Tests die grundlegenden Anforderungen für die Produktion erfüllt und keine Fehlextraktionen aufgetreten sind. Für Szenarien mit häufigen API-Aufrufen von Agenten oder Geschäfts-APIs werden Antwortlatenz und Token-Verbrauch zu entscheidenden Unterscheidungsmerkmalen. In diesem Vergleich bietet Step 3.7 Flash bei gleichbleibender Ausgabequalität eine schnellere Antwortgeschwindigkeit und niedrigere Kosten, was es zur bevorzugten Wahl für den ersten Produktionseinsatz in Tests macht.