

de.wedoany.com-Bericht: Da die Skalierung der Transistordichte nachlässt, ist die fortschrittliche Gehäusetechnik zum wichtigsten Erweiterungsweg geworden. Allerdings sind Künstliche Intelligenz-Beschleuniger sperrig und benötigen extrem hohe Verbindungsgeschwindigkeiten, was die Gehäuse selbst an ihre Grenzen bringt. Runde Interposer begrenzen die Gehäusegröße und die Waferausbeute, die HBM4E-Technologie verdoppelt die I/O-Anzahl bei gleichzeitiger Geschwindigkeitssteigerung, und Gehäuse im Multikilowatt-Bereich überfordern herkömmliche Kühlarchitekturen.
Die ECTC ist die führende Branchenveranstaltung für Gehäusetechnik. Die diesjährigen Veröffentlichungen stehen in engem Zusammenhang mit kurz vor der Markteinführung stehenden kommerziellen Produkten. Intel skizzierte die EMIB-T-Integration, die Skalierung der Gehäusegröße und die zukünftige Roadmap. Marvell zeigte, wie durch kundenspezifisches HBM die Schnittstellenlogik aus dem Beschleuniger entfernt und gleichzeitig die Gehäuseverdrahtung verkürzt werden kann. TSMC und Microsoft integrieren Kühlmittel direkt in das Silizium, während Marvell und Lightmatter optische Verbindungen in das Gehäuse integrieren.
Diese Zusammenfassung behandelt die Technologien der ECTC 2026, die in den kommenden Jahren am ehesten die KI-Beschleuniger-Landschaft prägen werden.
Intel EMIB-T
Intel ist der größte Unternehmensredner auf der ECTC. Der Schwerpunkt liegt auf EMIB-T. Dies ist die nächste Generation von EMIB-Chips, die Silizium-Durchkontaktierungen (TSV) verwenden. Nach der ersten Veröffentlichung hat Intel die Architektur und Roadmap weiter verfeinert, einschließlich kleinerer Bump-Abstände, größerer Gehäusegrößen und Brückenfunktionen. Ihre Präsentation deutet darauf hin, dass EMIB-T voraussichtlich in Googles TPU v9 zum Einsatz kommen wird und die zuverlässigste Alternative zur CoWoS-Plattform von TSMC im Bereich der großen Gehäuse-KI-Beschleuniger darstellt.
EMIB-T-Erweiterungstestchip, Siliziumanteil entspricht dem Doppelten einer Retikel-Fläche. Rasterelektronenmikroskop-Aufnahmen von oben zeigen Bump-Abstände von 110, 55 und 36 Mikrometern.

Intel hat die EMIB-T-Technologie auf einem Chip mit doppelter Retikel-Größe validiert, mit einem Bump-Abstand von 36/35 Mikrometern. Dies entspricht einer Steigerung der Bump-Dichte um 65 % im Vergleich zum 45-Mikrometer-Abstand, der im Granite-Rapids-Gehäuse verwendet wird. Granite Rapids-AP ist ein großes Gehäuse mit den Abmessungen 70 mm × 105 mm, etwas kleiner als 9 Retikel. Derzeit wird die Validierung für den 36/35-Mikrometer-Bump-Abstand auf Gehäuse mit 4,5-facher Retikel-Größe ausgeweitet, mit dem Ziel der Zertifizierung bis Ende 2026.

Der nächste Abstandsschritt ist ebenfalls in Arbeit; Intel testet einen 25-µm-Bump-Abstand, basierend auf einem Chip, der aus zwei 1-Retikel-Siliziumchips besteht, die durch eine einzelne 3 mm × 18 mm große EMIB-T-Brücke verbunden sind.
Eine weitere Verkleinerung wird schwieriger. Unter 25 µm wird das Lotvolumen in jedem Lotball sehr klein. Die Wahrscheinlichkeit von Kurzschlüssen, Unterbrechungen und Ausbeuteverlusten während der Montage steigt erheblich. EMIB-T kann weiter verkleinert werden, aber der limitierende Faktor verschiebt sich von der Brückenverdrahtungsdichte hin zur Lotballbildung, Platzierungsgenauigkeit und Montageausbeute.
Intel zeigte auch die Größengrenzen des EMIB-T-Gehäuses auf. Während Gehäuse in voller Panelgröße realisierbar sind, betrachtet Intel Viertelpanel-Gehäuse als praktisches Ziel. Sie präsentierten einen Testmuster mit 240 mm × 240 mm, einer Fläche, die etwa 67 Fotolithografiemasken entspricht. Allerdings wies das Muster am Stand eine starke Verbiegung auf. Bei dieser Größe sind Brücken nur ein Teil des Problems. Substrathandhabung, Verbiegung, Ausrichtungsgenauigkeit und Panel-Level-Musterung werden zu den primären limitierenden Faktoren. Intel evaluiert auch fortschrittliche Lithografie, um eine ausreichend hohe Ausrichtungsgenauigkeit für diese großen Substrate bei Viertelpanel- oder sogar Vollpanelgröße sicherzustellen.
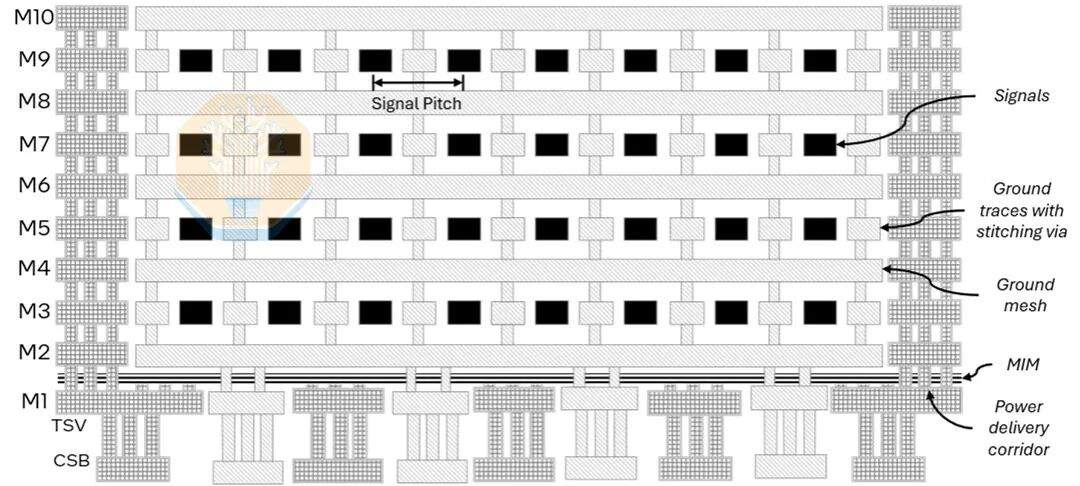
Obwohl Bump-Abstand und Gehäusegröße wichtig sind, ist die Brückenschaltung ebenso entscheidend. EMIB-T ist viel komplexer als die derzeit in Produkten verwendeten EMIBs. Es wurden TSVs, mehr Metalllagen, Stromversorgungsnetze und MIM-Kondensatorschichten hinzugefügt, sodass die Brückenschaltung gleichzeitig hochdichte Signale und vertikale Stromversorgung übertragen kann. Intel zeigte ein Querschnittsbild mit 10 Metalllagen (einschließlich 4 Verdrahtungslagen) sowie einem MIM-Kondensator zwischen M1 und M2. Intel hob die Verbesserungen für HBM4E hervor.
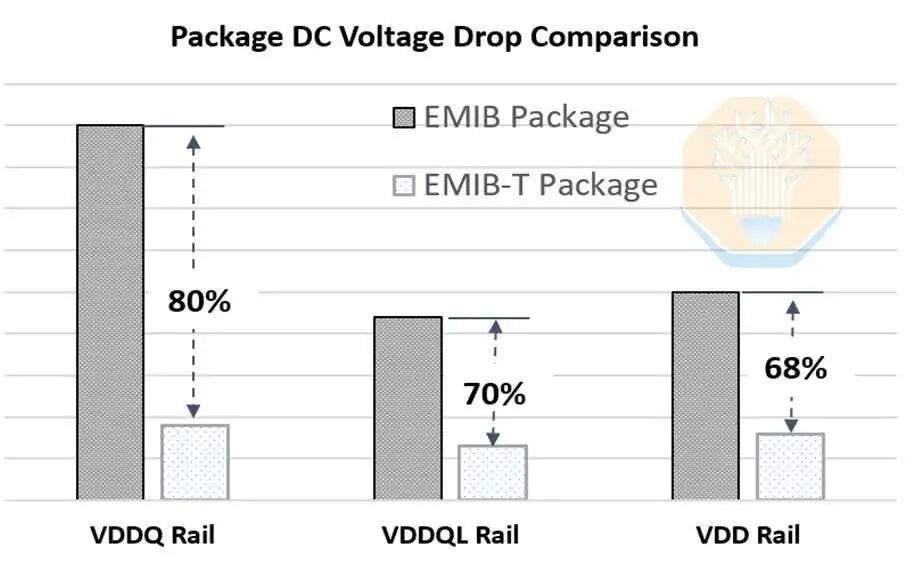
Das „T" in EMIB-T steht für TSV (Silizium-Durchkontaktierungen). Ihre Aufgabe ist die Stromversorgung. Bei herkömmlichen EMIBs wird die Stromversorgung in Nicht-Brückenbereichen vertikal durch das Substrat geführt, während die Stromversorgung in der Nähe des Brückenbereichs lateral in die Gehäuse- und Chip-Seitenverdrahtung verteilt werden muss. Durch die Verwendung von TSVs im Brückenbereich kann die Stromversorgung direkt durch den Brückenbereich geleitet werden, wodurch der Strompfad erheblich verkürzt wird. Intel gibt an, dass die Verwendung dieser TSVs den Gleichspannungsabfall um 68 % bis 80 % reduzieren kann.
Die Herausforderung bei HBM4E besteht darin, dass die Verbindungen gleichzeitig die Signaldichte und die Stromversorgungsfähigkeit erhöhen müssen. HBM4 hat doppelt so viele Pins wie HBM3, und das PHY benötigt zusätzliche Spannungsschienen wie VDDQ und VDDQL. Diese Spannungsschienen belegen einen Teil des Signalverdrahtungsraums und erhöhen so die Signaldichte im verbleibenden Raum.
Um dieses Problem zu lösen, verwendet Intel nicht für alle HBM-Kanäle die gleiche Verdrahtung. Die längsten Signalpfade werden auf Lagen mit saubererer Verdrahtung platziert. Auf der M9-Lage verlaufen nur etwa 28 % der längsten Kanallängen durch die am dichtesten verdrahteten Bereiche, während dieser Anteil auf niedrigeren Lagen wie M3 auf etwa 84 % ansteigt, diese Kanäle jedoch kürzer sind. Dadurch wird vermieden, dass Übersprechen und Einfügungsdämpfung hauptsächlich durch die am schlechtesten verdrahteten Bereiche verursacht werden.
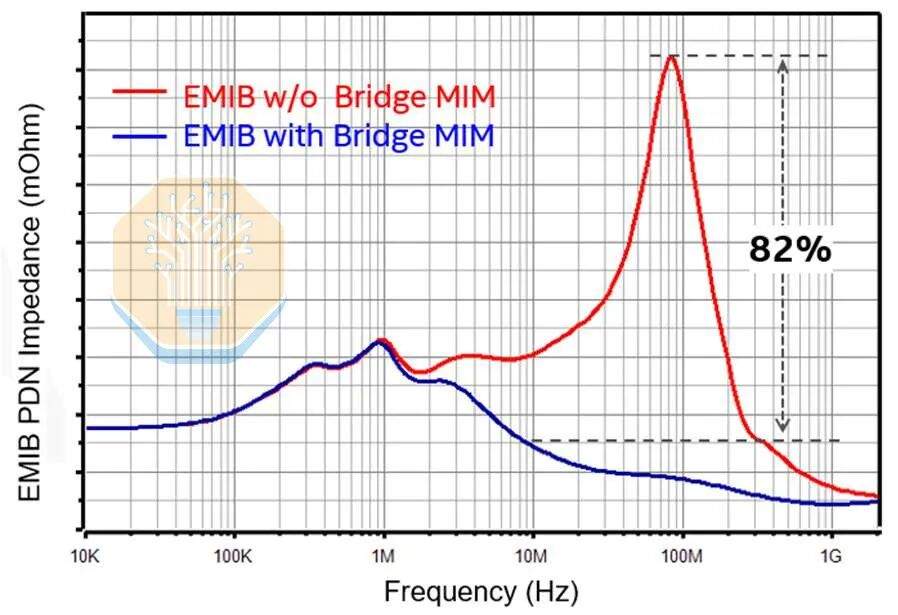
Die Stromübertragung wurde ebenfalls auf die Brückenlage verlagert. EMIB-M führte Metall-Isolator-Metall (MIM)-Kondensatoren zwischen M1 und M2 ein, und EMIB-T baut darauf auf. Intel gab eine Kapazitätsdichte von 500 nF/mm² an, was in etwa der MIM-Kapazität von Intel 18A entspricht. Intel behauptet, dass diese Brückenkondensatoren die AC-Impedanz des Stromversorgungsnetzes (PDN) im Vergleich zu einem EMIB-T-Gehäuse ohne Brücken-MIM-Kondensatoren um über 82 % reduzieren können.
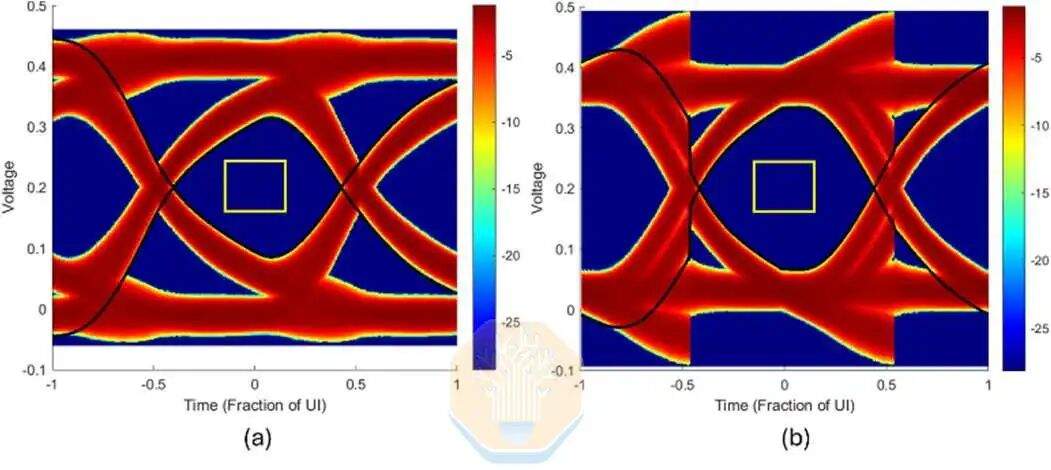
Intel führte auch Simulationen für EMIB-T mit HBM4E durch. Bei 12 Gb/s betrug die UI-Augenöffnungsweite von Intel ohne Empfänger-Entzerrung etwa 67 %. Mit einem Entscheidungsrückkopplungs-Entzerrer (DFE) mit einem Tap konnte dieser Wert auf etwa 72,5 % gesteigert werden. DFE ist eine Empfängerschaltung, die die Störung durch vorherige Bits reduziert, nachdem das Signal den Gehäusekanal durchlaufen hat.
Intel simulierte auch höhere Übertragungsgeschwindigkeiten von 12,8 Gb/s, 14 Gb/s und 16 Gb/s. Bei allen getesteten Geschwindigkeiten blieb die UI-Augenöffnungsweite über 60 %, mit einem leichten Rückgang der Pad-Kapazität.
Intels EMIB-Roadmap geht über passive Brückentechnologie, die nur Verdrahtung und Kondensatoren umfasst, hinaus. Zukünftige Versionen werden höherdichte Brücken-MIM-Kondensatoren, größere Brücken-Chips mit hohem Aspektverhältnis, Bump-Abstände unter 25 Mikrometern, aktive Brücken und in den EMIB-Chip integrierte Spannungsregler umfassen. Intel hat auch das Konzept von im Substratkern eingebetteten Tiefengrabenkondensatoren (DTC) und >2500 nF/mm² eMIM-T-Kondensatoren, die unter dem Substrat eingebettet sind, offengelegt, obwohl diese Technologien noch nicht in ausgelieferten EMIB-Produkten zu sehen sind.
EMIB-T hinkt der CoWoS-Plattform von TSMC in mehreren Bereichen noch hinterher. TSMC hat die DTC/eDTC-Integration realisiert und ist bei integrierten Spannungsreglern und aktiven lokalen Siliziumverbindungen (LSI) weiter fortgeschritten. EMIB-T schließt die Lücke, aber Intel holt zu einem Ökosystem auf, das bereits seit Jahren im großen Maßstab läuft.
Marvell kundenspezifisches HBM
Auf dem Branchenanalystentag von Marvell im Jahr 2024 kündigte Marvell kundenspezifisches HBM an. Damals war dies eine vage Aussage ohne technische Details. Das Design von HBM drehte sich immer um JEDEC-Kompatibilität: Standard-DRAM-Stapel von Speicheranbietern, standardmäßige HBM-PHYs auf den Beschleunigern und eine feste, breite Schnittstelle dazwischen. Auf der Hot Chips 2025 zeigte Marvell ein Layout des kundenspezifischen Basis-Chips.

Auf der ECTC lieferte Marvell schließlich Details auf Gehäuseebene für kundenspezifisches HBM4E.
Die JEDEC-Spezifikation legt die Schnittstelle zwischen dem HBM-Stapel und dem Host fest. Dies begünstigt die Interoperabilität: HBM eines beliebigen Speicheranbieters kann mit jedem kompatiblen Host gepaart werden. Dies ist jedoch nachteilig für Leistungsaufnahme, Leistung und Fläche. Der Host-ASIC muss ein standardmäßiges HBM-PHY mit standardisiertem Pad-Layout und Ausleitungsregeln implementieren und eine sehr breite parallele Schnittstelle verdrahten. Mit zunehmender Gehäusegröße und steigender HBM-Geschwindigkeit wird es durch diese feste Grenze schwieriger, die Küstenlinie, Verdrahtungsdichte, Stromversorgung und Signalintegrität zu optimieren.

Die kundenspezifische HBM-Technologie erfordert keine Änderungen an den DRAM-Kern-Chips. Stattdessen wird ein kundenspezifischer Basis-Chip mit optimierter Chip-zu-Chip-Schnittstelle in einem fortschrittlichen Logikprozess gefertigt. Dieser kundenspezifische Basis-Chip kann den HBM-Controller, Verwaltungs- und Überwachungsfunktionen, kundenspezifische Logik und erweiterte Schnittstellen integrieren.

Marvell gibt an, dass dies den Platzbedarf des Host-ASICs für das HBM-PHY und die zugehörige Logik um etwa 60 % reduziert, wodurch direkt mehr Platz für Recheneinheiten, Cache oder I/O frei wird. Diese kundenspezifische Schnittstelle verlagert einen Großteil der speicherseitigen Schnittstelle in den HBM-Basis-Chip.
Das Beispiel von Marvell verwendet 1024 Kanäle mit 32 Gb/s, was 4,1 TB/s entspricht, vergleichbar mit einer 2048-Bit-JEDEC-HBM4(E)-Schnittstelle mit 16 Gb/s.
Die Verdrahtung des Gehäuses wird ebenfalls einfacher; die kundenspezifische Schnittstelle verkürzt die Interposer-Kanallänge von 6,5 mm auf 1,5 mm, sodass Marvell die Bandbreite erhöhen kann, während die gleichen 9 Verdrahtungslagen und 2/2 µm Leiterbahnbreite/-abstand (L/S) beibehalten werden.
Im Beispiel von Marvell wird ein organisches RDL-Interposer anstelle von Silizium verwendet, was die Gehäusekosten senkt. Organische RDLs haben eine viel geringere Leiterbahnbreite und einen viel geringeren Leiterbahnabstand als Silizium-Interposer in CoWoS-S oder Siliziumbrücken in CoWoS-L und EMIB-T, was das Layout erschwert. Marvell verlässt sich auf kundenspezifische Abschirmung und Verdrahtungsmuster in verschiedenen Abschnitten, um die Bandbreitendichte zu maximieren und gleichzeitig das Übersprechen zu kontrollieren.

Auf der GTC kündigte Nvidia an, dass Feynman kundenspezifisches HBM verwenden wird. Die Gründe von Nvidia ähneln wahrscheinlich denen von Marvell: höhere Bandbreite, geringere Leistungsaufnahme und weniger Chipfläche für den HBM-Beschleuniger. Etwa 16 % der Chipfläche des Rubin-GPUs werden für HBM-bezogene Logik und PHYs verwendet. Kundenspezifisches HBM könnte es Nvidia ermöglichen, einen Großteil dieser Last auf den HBM-Basis-Chip zu verlagern.
Kundenspezifisches HBM unterstützt auch erweiterte Schnittstellen über die standardmäßigen HBM-Verbindungen hinaus. Der Basis-Chip kann als sekundärer Speichercontroller fungieren und den Datenverkehr zu zusätzlichem Speicher weiterleiten, anstatt den gesamten Speicherverkehr durch die begrenzten Kantenkanäle des Beschleuniger-Chips zu zwingen. Bei diesem zusätzlichen Speicher kann es sich um LPDDR mit größerer Kapazität und geringerer Bandbreite oder sogar um eine zweite HBM-Ebene handeln. Dies ermöglicht es Beschleunigern, die Speicherkapazität zu erweitern, ohne die wertvollen Chip-Kantenkanäle zu belegen, die für externe I/Os benötigt werden. Dies ist besonders wichtig für AMDs kommende MI450- und zukünftige MI500-GPUs, die LPDDR zur Erhöhung der Speicherkapazität unterstützen werden.
Samsung HBM-Interposer
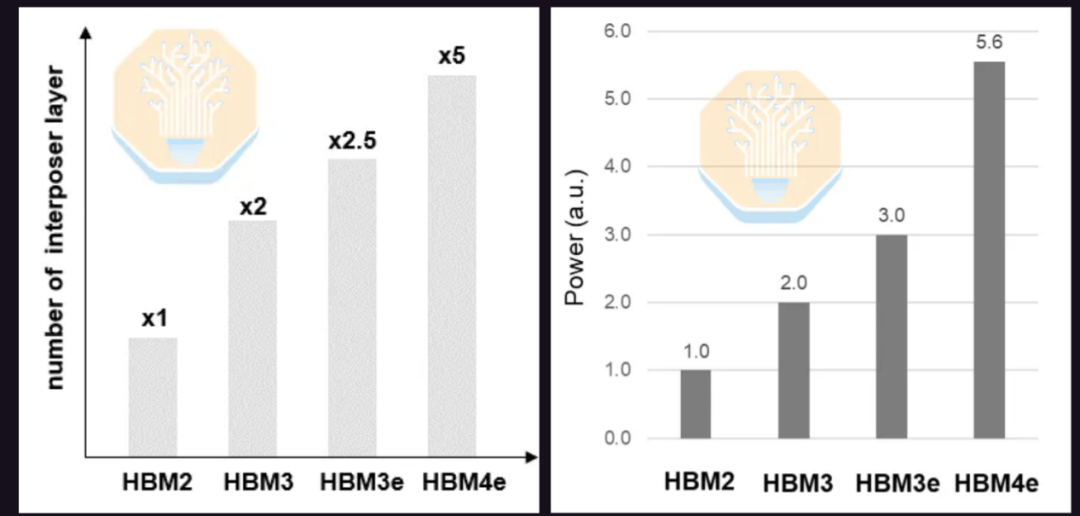
Samsung zeigte auch seine interposerbasierte HBM4E-Lösung. HBM4E erhöht die Datenübertragungsrate auf 12 Gb/s und mehr und verdoppelt die Anzahl der I/O-Pins, was die Verdrahtungskomplexität erhöht. HBM4E könnte die doppelte Anzahl an Interposer-Lagen im Vergleich zu HBM3E und die fünffache Anzahl im Vergleich zu HBM2 benötigen. Aufgrund der erhöhten I/O-Pin-Anzahl und der höheren Datenübertragungsrate wird erwartet, dass die Leistungsaufnahme im Vergleich zu HBM3E um 86 % und im Vergleich zu HBM2 um das 5,6-fache steigt.
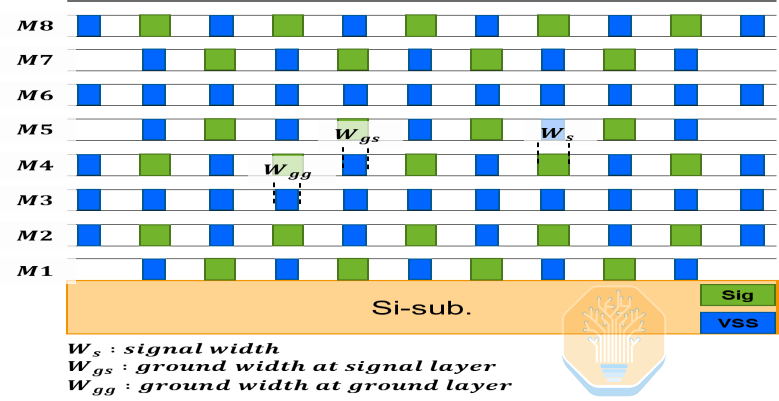
Samsung schlug einen 8-Lagen-Silizium-Interposer vor, der angeblich eine Reduzierung der Lagenzahl um 20 % im Vergleich zum geschätzten Bedarf darstellt. Der Interposer verwendet eine wiederholte Anordnung von zwei Signalleitungen und einer Masseleitung zur Abschirmung von Hochgeschwindigkeitssignalen, wobei 75 % der Lagen für die Signalverdrahtung genutzt werden.
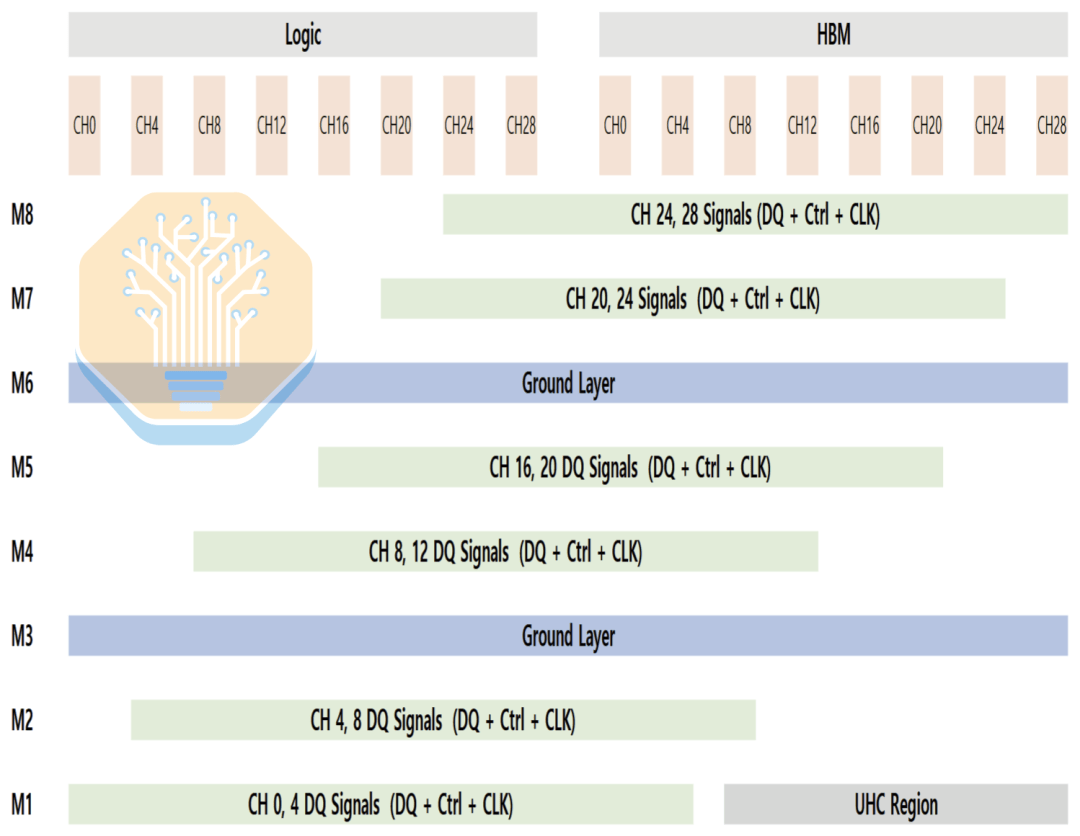
Ein weiteres Schlüsselmerkmal des Interposers sind die Ultra-High-Density-Kondensatoren (UHC). Samsung hat die genaue Kondensatorstruktur nicht spezifiziert, aber sie ähneln wahrscheinlich den Intel EMIB-T MIM-Kondensatoren oder den TSMC CoWoS DTC-Kondensatoren. UHC-Kondensatoren können nur auf der M1-Lage platziert werden, die ebenfalls hauptsächlich für die Signalverdrahtung genutzt wird, sodass die verfügbare Fläche begrenzt ist.
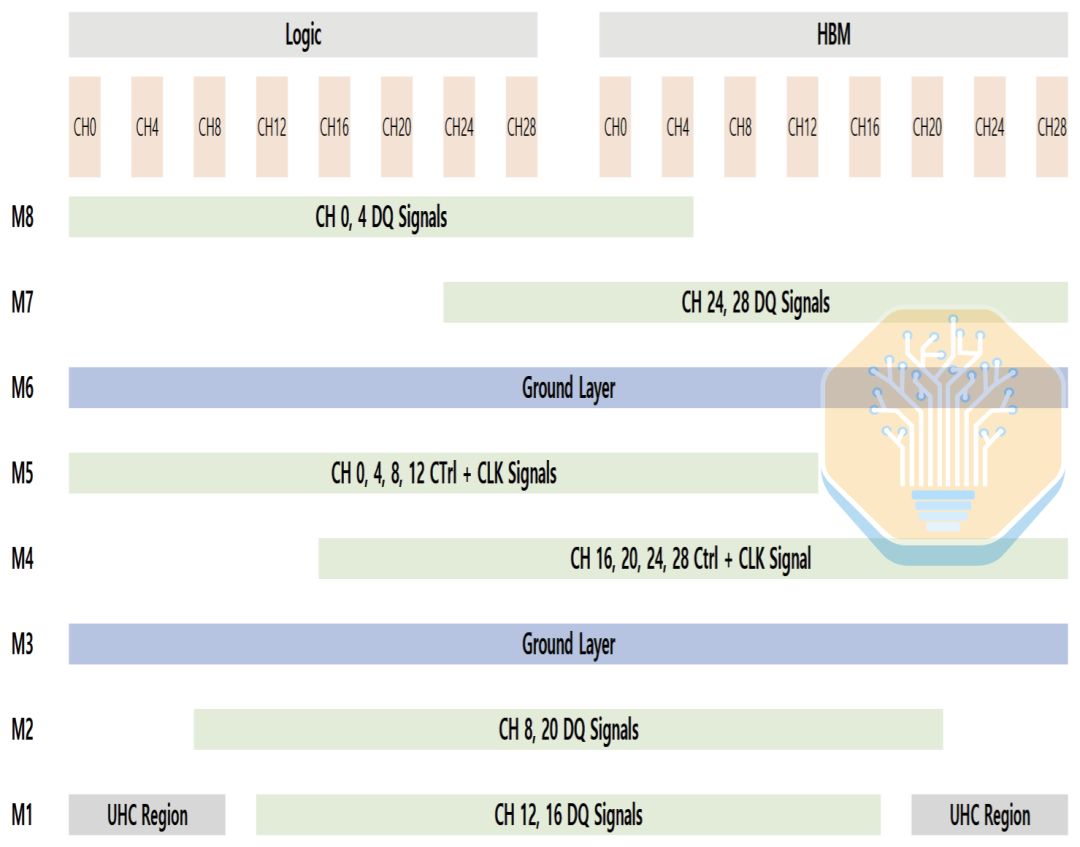
Wenn die Verdrahtung unausgeglichen ist, werden die Kondensatoren zu einer Seite der Schnittstelle gedrängt, was zu einer ungleichmäßigen PDN-Leistung zwischen der Logikseite und der HBM-Seite führt. Samsungs Layout verteilt die Verdrahtung neu auf die M1-Lage und andere Lagen, sodass die UHC gleichmäßiger über die gesamte Schnittstelle verteilt werden können. Dies reduziert die PDN-Impedanz und Spannungsrauschen, während die Verdrahtungsdichte beherrschbar bleibt.
Samsung HBM Hybrid Bonding Thermik
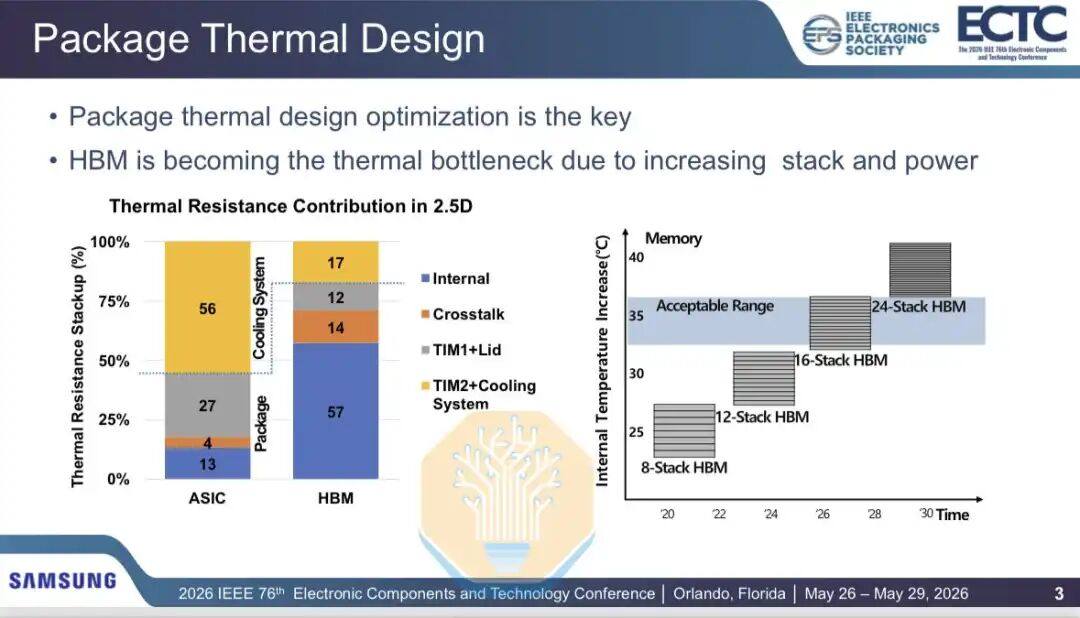
Samsung diskutierte auch die thermischen Probleme von HBM, insbesondere die Hybrid-Bonding-Technologie. HBM-Stapel werden immer höher und schneller, und die Logikchips darunter verbrauchen ebenfalls mehr Leistung. Für 16-Lagen-HBM ist der thermische Widerstand noch akzeptabel, aber mit der Entwicklung hin zu 20 und 24 Lagen in zukünftigen Generationen sind neue Lösungen erforderlich.
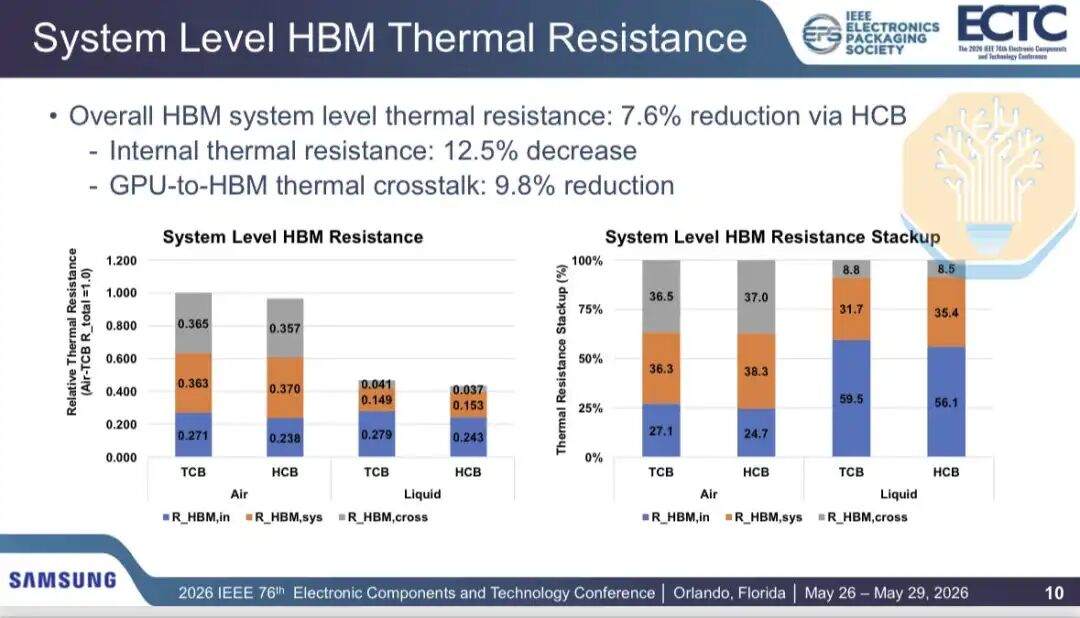
Samsung verglich die HBM-Wärmeableitungsleistung von Thermokompressionsbonden (TCB) und Hybrid Copper Bonding (HCB) in einem 2,5D-GPU-Gehäuse (mit 2 GPU-Chips und 8 HBM-Stapeln, ähnlich der Nvidia Blackwell-Architektur). Die Ergebnisse zeigten, dass Luftkühlung den internen HBM-Wärmewiderstand um 12,2 % und Flüssigkeitskühlung um 12,9 % senken kann. Der gesamte HBM-Wärmewiderstand konnte bei Luftkühlung um 3,5 % und bei Flüssigkeitskühlung um 7,7 % gesenkt werden.
Da HCB nur einen Teil des Wärmenetzes betrifft, sind die Verbesserungen ungleichmäßig. Samsung unterteilte den Wärmepfad in internen Wärmewiderstand, systemischen Wärmewiderstand und GPU-zu-HBM-Übersprechen. Der interne Wärmewiderstand und das Übersprechen sanken um etwa 12,5 % bzw. 9,8 %, aber der systemische Wärmewiderstand, der Wärmeleitmaterial und Kühlkörper umfasst, stieg um etwa 2,3 %.
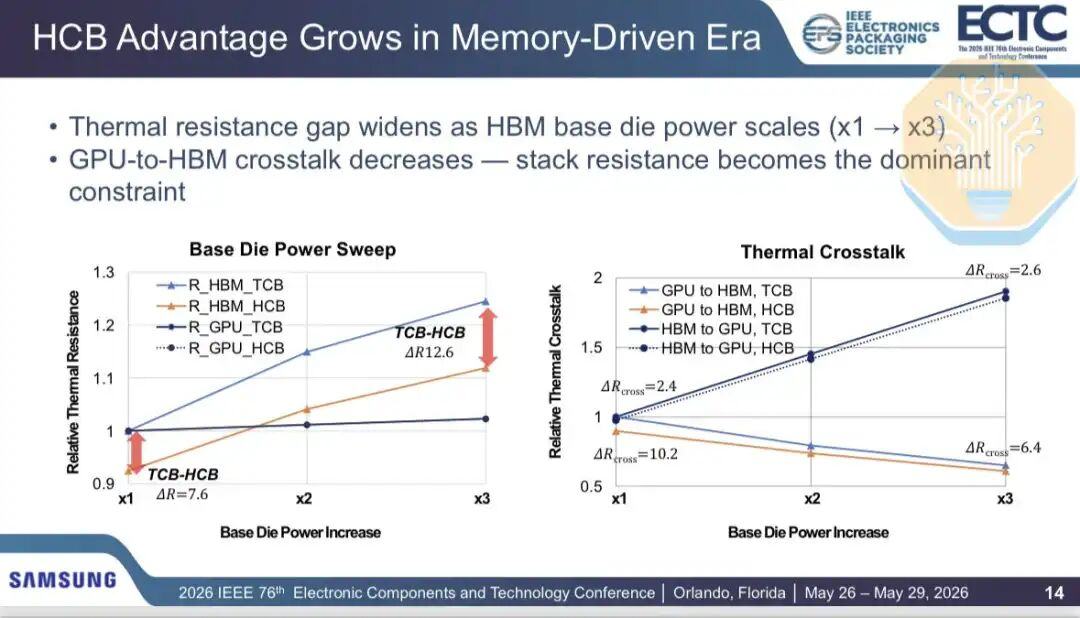
Wenn mehr Leistung auf das HBM-Substrat verlagert wird (z. B. bei speicherintensiven Arbeitslasten), verschiebt sich der thermische Engpass. Dies ist besonders wichtig für kundenspezifisches HBM, bei dem der Speichercontroller und mehr Logik in das Substrat integriert sind. Der Anteil des GPU-zu-HBM-Übersprechens am Gesamtwärmewiderstand sinkt von 13 % bei einer Verdopplung der Substratleistung auf 5 % bei einer Verdreifachung der Substratleistung.
Samsung gab an, dass die HCB-Technologie höhere Lufteintrittstemperaturen oder eine höhere Gehäuseleistung ermöglicht. Schätzungen zufolge kann die Lufteintrittstemperatur bei gleichbleibender Gehäuseleistung um 1-2 °C erhöht werden, oder die Gehäuseleistung kann bei gleichbleibender Temperatur um etwa 4 % gesteigert werden. Samsung schätzt auch, dass die Kühlleistung um etwa 7 % reduziert wird.
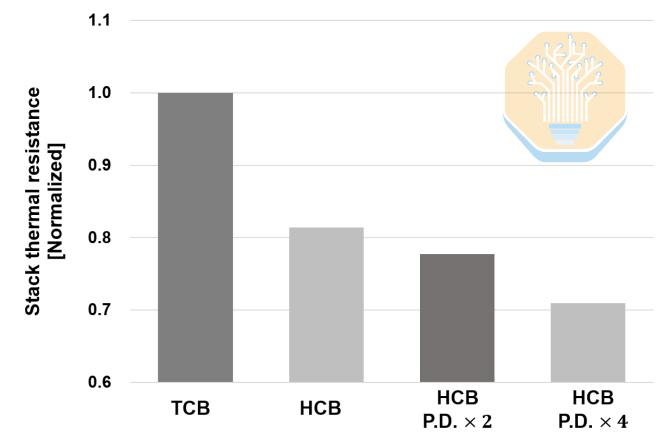
Samsung untersuchte auch separat die Auswirkungen von HCB auf Stapelebene. Die Verbesserungen sind hier größer: Im Vergleich zu TCB reduziert das Basis-HCB den Stapelwärmewiderstand um etwa 19 %. Eine Erhöhung der Anzahl der HCB-Pads führt bei einer Verdopplung der Pad-Dichte zu einer Reduzierung des Wärmewiderstands um 22,3 % und bei einer Vervierfachung der Pad-Dichte um 29,1 %.
Mikrofluid-Kühlung
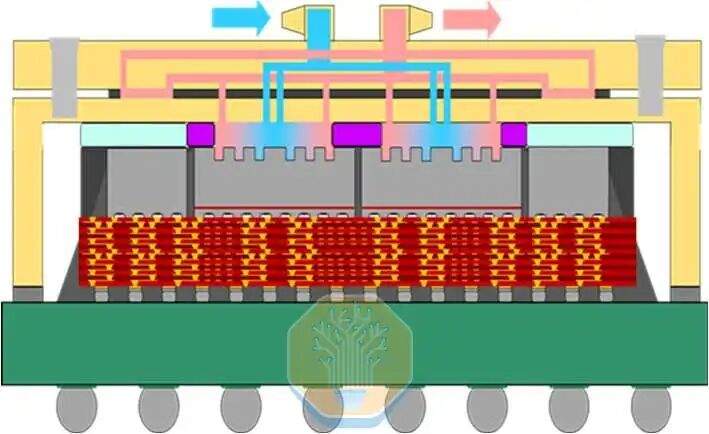
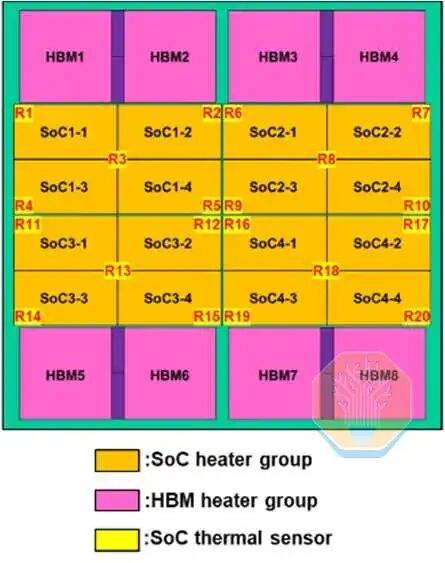
TSMC demonstrierte direkte Siliziumkühlung auf einem CoWoS-R-Chip, der in einer GPU-ähnlichen großen Testplattform verwendet wurde. CoWoS-R unterscheidet sich von CoWoS-S durch die Verwendung organischer Materialien anstelle eines Silizium-Interposers. CoWoS-R wurde aufgrund seiner besseren Verbiegungstoleranz und Prozesskompatibilität gewählt. Die Testplattform verwendet einen 3,3-fach Retikel-Interposer mit 4 SoC-Chips und 8 HBM-Stapeln. Jeder SoC-Chip besteht aus 4 Gruppen von SoC-Heizern, die zusammen etwa die Hälfte der Interposerfläche abdecken.
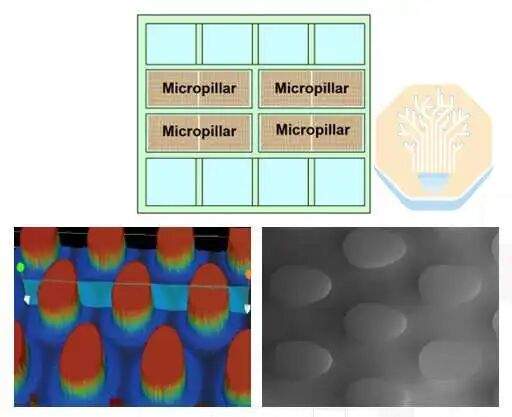
TSMC verglich drei Ansätze: ein herkömmliches Gehäuse mit Deckel und Kühlplatte, ein Gehäuse ohne Deckel mit Kühlplatte und ihr Mikrosäulen-Direktsilizium-Gehäusedesign. Die Ansätze mit und ohne Deckel verwenden weiterhin herkömmliche Kühlplatten und Wärmeleitmaterial (TIM). Der letzte Ansatz bildet Mikrosäulen direkt auf der Rückseite des SoC-Chips.
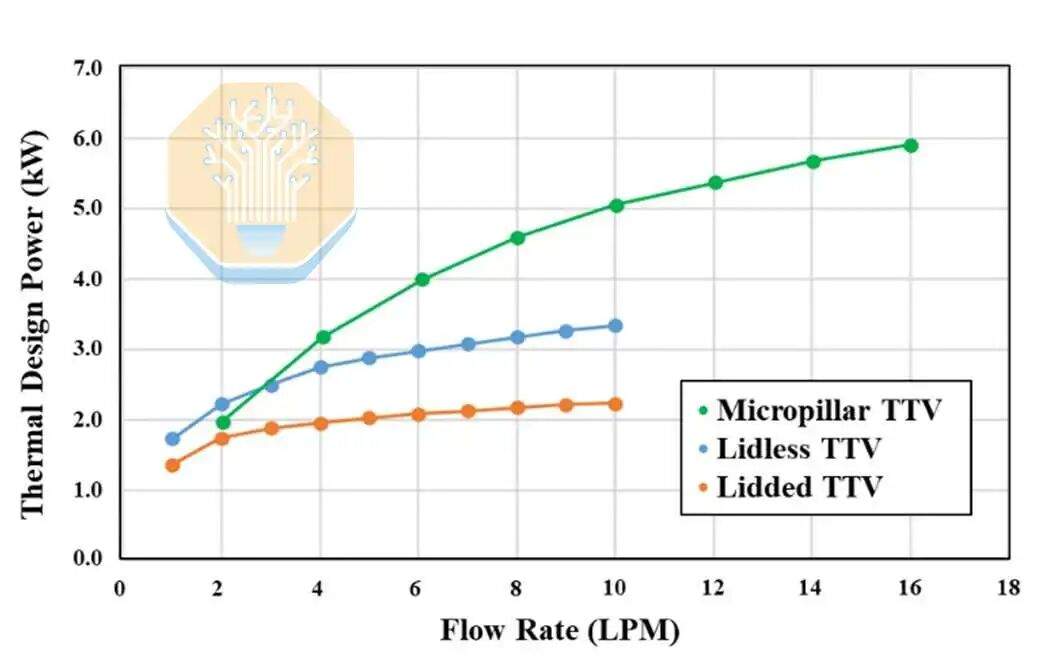
Bei herkömmlicher Kühlung und einer Durchflussrate von 1-2 Litern pro Minute (LPM) betrug die Wärmeabfuhr des Gehäuses mit Deckel 1,9-2,3 kW und die des Gehäuses ohne Deckel 2,5-3,0 kW, bei einer Kühlwassertemperatur von 40 °C entionisiertem Wasser. Beide Ansätze erreichten bei Durchflussraten über 4 LPM eine Sättigung, da das Wärmeleitmaterial (TIM) zum Engpass wurde.
Das Mikrosäulen-Testfahrzeug war bei 2 LPM mit den Ergebnissen der deckellosen Kühlplatte vergleichbar und übertraf diese bei höheren Durchflussraten, mit einer Wärmeabfuhr von 4 kW bei 4 LPM und 5,3 kW bei 8 LPM. TSMC berichtete, dass die Wärmeabfuhr über das gesamte Testfahrzeug hinweg gleichmäßig über 5 kW lag. Die Mikrosäulenstruktur bringt das flüssige Kühlmittel näher an die Wärmequelle und fördert so die Wärmeableitungsleistung.
Die Mikrosäulenstruktur ist jedoch nicht perfekt. TSMC musste die Mikrosäulen nach Abschluss des Chip-on-Wafer (CoW)-Prozesses bilden, dabei eine Beschädigung der CoWoS-R-Struktur vermeiden und neue Dichtungsmaterialien entwickeln, um die Abdichtung des Kühlmittels trotz Gehäuseverbiegung und thermischer Ausdehnungskoeffizienten-Unterschiede zu gewährleisten. Die Testmuster bestanden den Feuchtigkeitsempfindlichkeitsstufe-4 (MSL4)-Test ohne Heliumleckage oder Delamination der Dichtung.
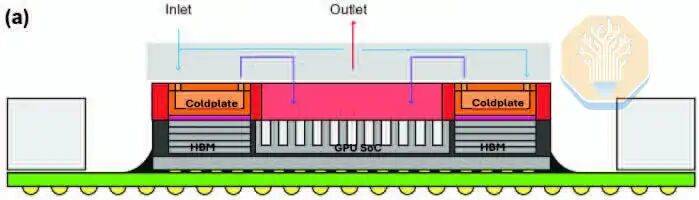
Der Kühlansatz von Microsoft unterscheidet sich von dem von TSMC in der Kühlstruktur. TSMC verwendet Silizium-Mikrosäulen, während Microsoft gerade Mikrokanäle verwendet, die in das GPU-Silizium geätzt wurden. Microsoft testete direkt auf einem Nvidia GH200 GPU, anstatt eine thermische Testplattform zu verwenden. Dies könnte es Microsoft ermöglicht haben, die realen Wärmeverteilungen und Hotspots genauer zu erfassen. Microsoft testete mehrere Arbeitslasten auf dem GPU, wie HPCG und HPL, jede mit unterschiedlichen Rechen- und Speicherdruckeigenschaften.
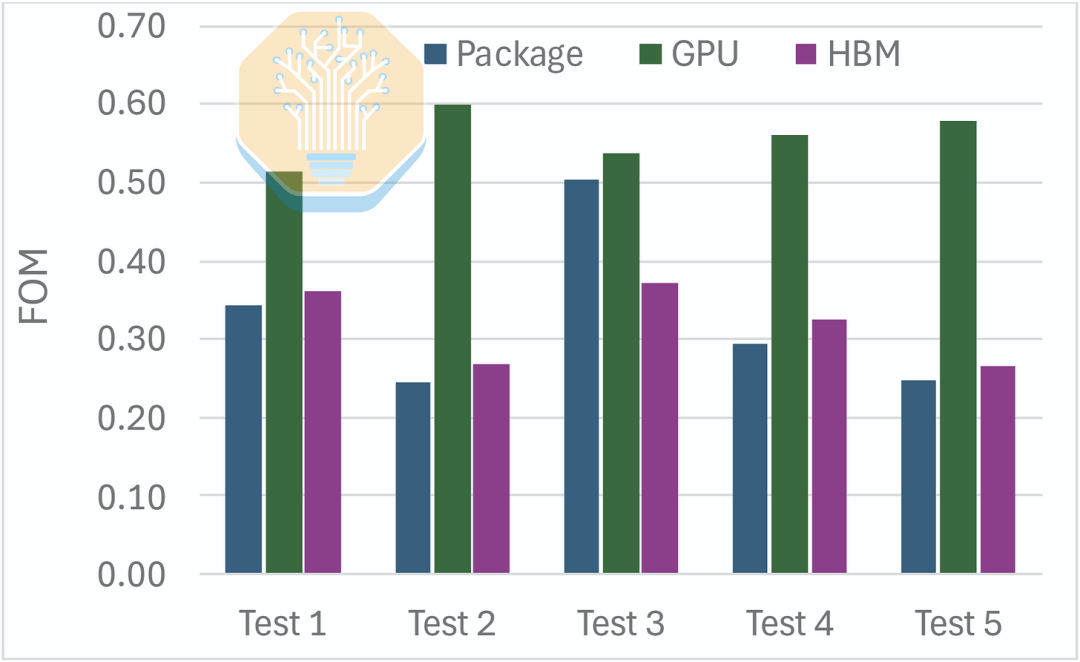
Unter diesen Arbeitslasten berichtete Microsoft von einer Reduzierung des GPU-Sperrschicht-zu-Eintritt-Wärmewiderstands um 51-60 % bei einer Durchflussrate von 1 LPM. Die Verbesserung bei HBM war mit 27-37 % geringer, da es weiterhin über Kühlplatte und Wärmeleitmaterial gekühlt wird. Insgesamt führte dies zu einer Reduzierung des Gehäuse-Wärmewiderstands um 50 %.
Microsoft zeigte auch einige vorläufige Zuverlässigkeitsdaten. Obwohl die Wärmeableitungsleistung wichtig ist, erfordert der Einsatz in Rechenzentren auch hohe Zuverlässigkeit und geringe Ausfallzeiten. Über einen Zeitraum von 6 Monaten verzeichnete Microsoft nur 9 potenzielle Verstopfungsereignisse bei etwa 4370 Beobachtungen. Die Verstopfungsrate nahm im Laufe der Zeit ab, was auf anfängliche Instabilität nach der Installation hindeutet, gefolgt von einer stabileren Betriebsphase. Selbst nach 6 Monaten war keine messbare Siliziumkorrosion in den Mikrokanälen feststellbar. Auf Knotenebene absolvierte der GH200 erfolgreich einen 3-wöchigen wiederholten Benchmark-Test, gefolgt von einem einwöchigen Dauerbetrieb bei stabiler Gehäuseleistung. Microsoft testet weiterhin die mittlere Betriebsdauer zwischen Ausfällen (MTBF) und Verfügbarkeit auf Clusterebene.










