de.wedoany.com-Bericht: Einem Forschungsteam der Zhejiang-Universität ist es gelungen, auf einem programmierbaren supraleitenden Quantenprozessor eine schaltungsbasierte Bucket-Brigade-Architektur für einen Quanten-Random-Access-Speicher (QRAM) physikalisch zu realisieren. Diese Online-Preprint-Studie untersucht eine Hardwareschnittstelle, die darauf abzielt, den Engpass beim Laden von Daten zu überwinden, der bei der Aufbereitung klassischer Binärdatensätze für die Quantenverarbeitung auftritt. Obwohl viele Quantenalgorithmen einen schnellen, kohärenten Zugriff auf klassische Informationsarrays voraussetzen, führt die physikalische Dateneingabeschicht häufig zu erheblichen Verzögerungen und Dekohärenz. Das Forschungsteam präsentiert ein praktisches Schaltungsframework, das aktive Routingmechanismen auf einem supraleitenden Substrat nutzt, um traditionelle Binärstrukturen in Quantenüberlagerungszustände zu laden.

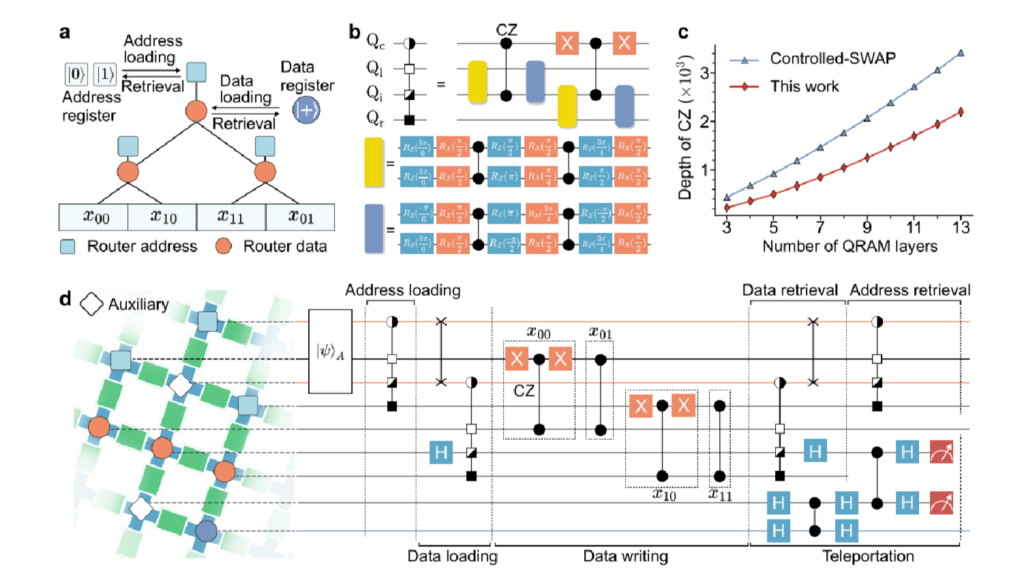
Der experimentelle Aufbau bildet den Binärbaum des Quantenrouters auf ein zweidimensionales Gitter aus supraleitenden Qubits ab, mit dem Ziel, die im Bucket-Brigade-Basismodell vorgeschlagene O(log N)-Skalierung des aktiven Schaltens zu erreichen. Um den aktuellen Einschränkungen durch kurze Kohärenzzeiten und begrenzte Schaltungstiefen der Hardware zu begegnen, führten die Forscher ein hardwareeffizientes Gatterzerlegungsschema für einzelne Quantenroutingknoten ein. Im Vergleich zur standardmäßigen Controlled-Swap-Implementierung (CSWAP) reduziert diese Technik die erforderliche Quantenschaltungstiefe um über 30 %. Auf einem Chip mit Einzel-Qubit- und Zwei-Qubit-Gattertreuen von 99,96 % bzw. 99,7 % betrieben, evaluierte das Team zwei- und dreischichtige Routingbäume. Assistenzprofessor Lu Liqiang wies darauf hin, dass der Prototyp 4-Bit- und 8-Bit-klassische Datenformate verarbeitete, wobei die gemessenen Abfragetreuen 0,800 ± 0,026 bzw. 0,604 ± 0,005 betrugen, während gleichzeitig aktive Fehlerabschwächungsprotokolle zur Stabilisierung der Routingpfade eingesetzt wurden.
Die Fähigkeit, mehrere Dateneingabestrukturen gleichzeitig zu routen, ist eine Voraussetzung für die Ausführung von Quantenalgorithmen mit großen Datenmengen, einschließlich der Extraktion molekularer Eigenschaften aus chemischen Datenbanken, der Verfolgung von Transaktionsmustern bei der Betrugserkennung und der Verwendung von Quanten-Maschinenlernmodellen mit mehreren Parametern. Die Daten offenbaren jedoch klare technische Grenzen der aktuellen Skalierbarkeit. Der starke Abfall der Abfragetreue von der 4-Bit- zur 8-Bit-Konfiguration unterstreicht die schwerwiegende Rauschakkumulation, die mehrschichtigen Quantenbäumen innewohnt. Um diese Architektur vom Proof-of-Concept im kleinen Maßstab auf die für das kommerzielle Data Mining erforderlichen Multi-Megabit-Arrays zu skalieren, sind eine höhere Gattertreue der physikalischen Qubits, ein reduziertes Übersprechen während paralleler Routingoperationen und die Integration robuster Quantenfehlerkorrektur im Speicherbus erforderlich.
Das vollständige technische Manuskript ist über das Open-Access-Repository arXiv zugänglich. Geopolitische Hintergründe und institutionelle Berichterstattung über globale Deep-Tech-Fertigungsinitiativen finden sich in einer von der Seoul Economic Daily veröffentlichten Analysezusammenfassung sowie in den wichtigsten Technologie-Tracking-Artikeln der South China Morning Post.
Dieser Artikel wurde von Wedoany übersetzt und bearbeitet. Bei jeglicher Zitierung oder Nutzung durch künstliche Intelligenz (KI) ist die Quellenangabe „Wedoany“ zwingend vorgeschrieben. Sollten Urheberrechtsverletzungen oder andere Probleme vorliegen, bitten wir Sie, uns unverzüglich zu benachrichtigen. Wir werden den entsprechenden Inhalt umgehend anpassen oder löschen.
E-Mail: news@wedoany.com