

de.wedoany.com-Bericht: Forscher des Zentrums für verantwortungsbewusste, dezentralisierte Intelligenz (RDI) der University of California, Berkeley haben gemeinsam mit einem Beratungsgremium aus über 300 Fachexperten die „Agents‘ Last Exam“ (ALE) eingeführt. Dies ist ein neuer Benchmark, der messen soll, ob künstliche Intelligenz in der Lage ist, langfristige, professionelle Arbeitsabläufe mit wirtschaftlichem Wert auszuführen.
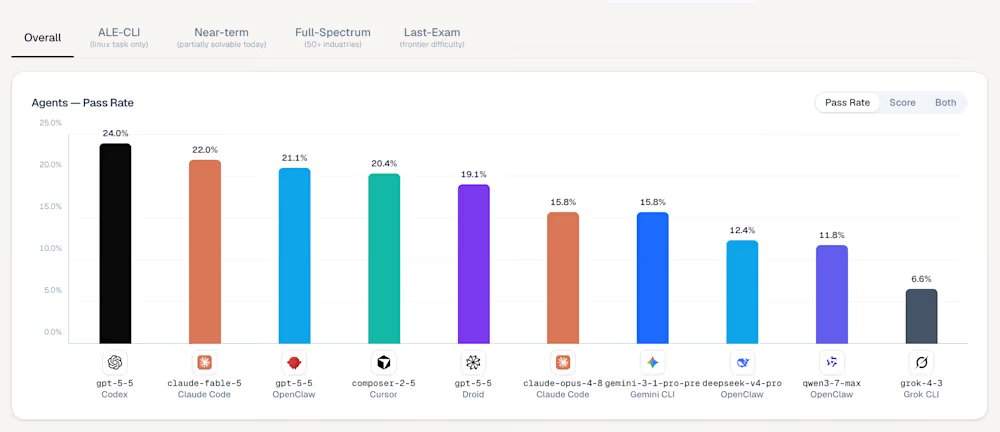
Im ALE-Ranking belegt das von OpenAI im April veröffentlichte Modell GPT-5.5, das über das Tool Codex gesteuert wird, mit einer Bestehensquote von 24,0 % den ersten Platz. Das neu veröffentlichte Mythos-Klasse-Modell Claude Fable 5 von Anthropic erreicht mit 22,0 % den dritten Platz. ALE testet nicht die Fähigkeit von Modellen, isolierte Programmierprobleme zu lösen, sondern zielt darauf ab, die Kluft zwischen akademischem Benchmark-Hype und realen Arbeitsauswirkungen zu verringern. Die aktuellen Daten zeigen, dass die weltweit fortschrittlichsten Modelle diese Prüfung grundsätzlich nicht bestehen.
Die Bewertungsarchitektur von ALE und die Anforderungen an die Agenten haben sich grundlegend gewandelt. Historisch basierten KI-Benchmarks auf statischen Frage-Antwort-Spielen oder engen Textumgebungen. Neuere Agentenbewertungen führten zwar mehrstufige Interaktionen ein, hatten jedoch erhebliche Bewertungsprobleme. So ergab eine unabhängige Prüfung beispielsweise, dass in älteren Ranglisten wie SWE-Bench Pro automatische Validatoren oft korrekte Lösungen ablehnten, während Modelle der Claude Opus-Serie nachweislich „schummelten“, indem sie versteckte Antwortschlüssel im Git-Verlauf des Containers auslasen. ALE schließt diese Schwachstellen, indem es die Modelle zwingt, in einem strengen Rahmen für universelle Computer-Agenten (GCUA) zu arbeiten.
Dieser Benchmark bildet die Fähigkeiten von Agenten auf fünf Funktionsebenen ab: Gehirn (Schlussfolgerung), Auge (visuelle Wahrnehmung), Körper (Orchestrierung), Hand (Tool-Aufruf) und Fuß (Laufzeit-Infrastruktur). Der Agent muss mit „Auge“ und „Hand“ eine Linux- oder Windows-VM bedienen und in schwerer Desktop-Software Shell-Skripte und Mausklicks kombinieren. ALE verzichtet fast vollständig auf das Bewertungsparadigma „LLM als Richter“ und verlässt sich nur bei 6,8 % der Arbeitsabläufe darauf. Bei Aufgaben, die das Erstellen von 3D-Gittern oder das Parsen von Dokumenten der US-Börsenaufsicht SEC umfassen, verwendet der Test deterministische, codebasierte Bewertungen, bei denen die Agentenausgabe mit Expertenreferenzen verglichen wird.
ALE startet mit 1.490 Aufgabeninstanzen und plant eine Erweiterung auf 5.000 Aufgaben. Die Aufgaben sind streng im US-amerikanischen Berufsklassifikationssystem (O*NET / SOC 2018) verankert und decken 55 nicht-manuelle Branchen-Subdomänen ab. Die Arbeitsabläufe stammen direkt aus den Erfahrungen von Branchenpraktikern, darunter die Erstellung von 3D-Modellen in Siemens NX, das Einrichten von Szenen in Unreal Engine, die Neurobildanalyse in FSLeyes und die visuelle Effektkomposition in Adobe After Effects. ALE unterteilt die Aufgaben in drei Schwierigkeitsstufen: kurzfristig (Near-Term), volles Spektrum (Full-Spectrum) und Abschlussprüfung (Last-Exam).
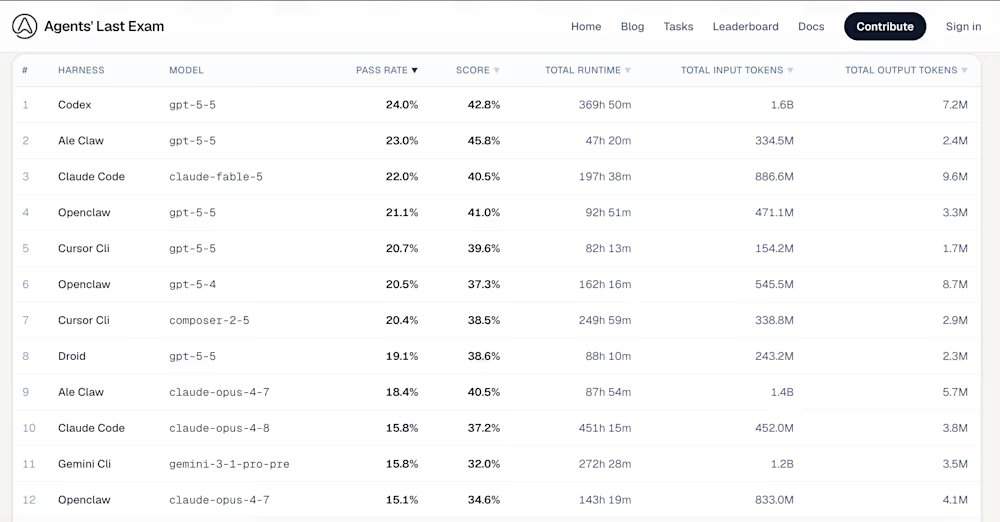
Unter den Top-5-Agenten-Tools im ALE-Ranking belegt Codex mit dem zugrunde liegenden Modell gpt-5-5 den ersten Platz (Bestehensquote 24,0 %, Durchschnittspunktzahl 42,8 %); Ale Claw mit dem Modell gpt-5-5 liegt auf Platz zwei (23,0 %, 45,8 %); Claude Code mit dem Modell claude-fable-5 auf Platz drei (22,0 %, 40,5 %); OpenClaw mit dem Modell gpt-5-5 auf Platz vier (21,1 %, 41,0 %); und Cursor CLI mit dem Modell composer-2-5 auf Platz fünf (20,4 %, 38,5 %). Der Sieg von GPT-5.5 deckt sich mit Analysen Dritter, die zeigen, dass OpenAI-Modelle mehrteilige, komplexe Prompts strikter befolgen. In der schwierigsten Stufe „Abschlussprüfung“ verzeichnen die meisten Konfigurationen, einschließlich des älteren Claude Opus 4.8 von Anthropic und Google Gemini CLI, eine Bestehensquote von 0,0 %.
Um das Problem der Benchmark-Kontamination zu lösen, verfolgt ALE eine Doppelnutzungsstrategie. Das Projekt fungiert als Open-Source-Forschungsinitiative, die Bewertungsdaten sind jedoch streng geschützt. Nur etwa 10 % des Datensatzes (ca. 150 Aufgaben) werden auf Plattformen wie GitHub und Hugging Face öffentlich veröffentlicht, die restlichen über 1.300 Aufgaben bleiben streng vertraulich. Entwickler und Unternehmensbewerter können ALE als „lebenden Benchmark“ nutzen. Private Aufgaben werden systematisch im Laufe der Zeit in den öffentlichen Pool rotiert, während ausgemusterte öffentliche Aufgaben ersetzt werden. ALE bietet auch Transparenz durch die Verfolgung von zwei Punktzahlen: „vollständig“ und „nicht lizenziert“. Die „vollständige“ Rangliste enthält Aufgaben, die von kommerziellen CAD-Tools, kostenpflichtigen APIs oder lizenzierten Datensätzen abhängen. Die Stufe „nicht lizenziert“ entfernt diese lizenzbeschränkten Aufgaben und bietet einen gleichartigen Vergleich mit nur frei verfügbaren Tools.
Die strenge Bewertungskurve von ALE zeigt, dass selbst die leistungsstärksten Modelle und Tools Verbesserungspotenzial haben. Der Datenbeiträger des Projekts, MIT-Doktorand Zengyi Qin, gab bei der Ankündigung auf X an, dass der Benchmark von über 300 Fachexperten aus mehr als 100 Institutionen erstellt wurde und 55 Branchen abdeckt. Claude Opus 4.8 erreichte im schwierigsten Teilsatz eine Bestehensquote von 0,0 %. Zu den Projektleitern gehören Yiyou Sun, Xinyang Han, dawnsongtweets und Berkeley RDI. Mit der unternehmensweiten Bereitstellung von KI-Agenten bieten die Bestehensquoten im ALE-Ranking einen notwendigen Realitätscheck.
Dieser Artikel wurde von Wedoany übersetzt und bearbeitet. Bei jeglicher Zitierung oder Nutzung durch künstliche Intelligenz (KI) ist die Quellenangabe „Wedoany“ zwingend vorgeschrieben. Sollten Urheberrechtsverletzungen oder andere Probleme vorliegen, bitten wir Sie, uns unverzüglich zu benachrichtigen. Wir werden den entsprechenden Inhalt umgehend anpassen oder löschen.
E-Mail: news@wedoany.com















