

de.wedoany.com-Bericht: Microsoft hat kürzlich ein neues Framework namens SkillOpt als Open Source veröffentlicht, das darauf abzielt, die Fähigkeitsdokumentation von KI-Agenten in trainierbare Objekte zu verwandeln. Durch die Einführung von Optimierungsmethoden im Stil des Deep Learnings wird die Leistung der Agenten bei komplexen Aufgaben systematisch verbessert.

In unternehmenskritischen KI-Anwendungen liegen Agentenfähigkeiten normalerweise in Form von textbasierten Markdown-Dateien vor, die Anweisungen enthalten, um das Modell an spezifische Arbeitsabläufe anzupassen. Traditionell war die Optimierung dieser Fähigkeiten jedoch auf manuelle Bearbeitung angewiesen, ein langsamer und fehleranfälliger Prozess, bei dem Benutzer oft durch Versuch und Irrtum die richtige Kombination von Anweisungen zur Leistungssteigerung finden mussten. Die Einführung von SkillOpt löst dieses Problem. Das Framework (lizenziert unter MIT) behandelt Fähigkeitsdokumente als trainierbare Objekte, die basierend auf Leistungsfeedback iterativ angepasst werden können, und ermöglicht so eine programmatische Anpassung auf Dokumentenebene, ohne die Gewichte des zugrunde liegenden Modells zu verändern.
Yifan Yang, leitender Forschungs- und Entwicklungsingenieur bei Microsoft Research Asia, weist darauf hin, dass die manuelle Bearbeitung von Fähigkeitsdokumenten mit drei Hauptfehlermodi konfrontiert ist: fehlende Schrittweitenkontrolle führt zu Fähigkeitsdrift, fehlende Validierungsmechanismen führen dazu, dass scheinbar korrekte Änderungen Leistungseinbußen verursachen können, und das Fehlen eines negativen Feedbackgedächtnisses führt zu wiederholten gleichen Fehlern. Beispielsweise senkte eine uneingeschränkte Neuschreibung GPT-5.5 im SpreadsheetBench-Benchmark von 41,8 auf 41,1. Yang betont, dass diese Fehler in mehrstufigen Arbeitsabläufen verstärkt werden, was genau die Schwachstelle aktueller Spitzenmodelle beim Zero-Shot-Schlussfolgern darstellt.
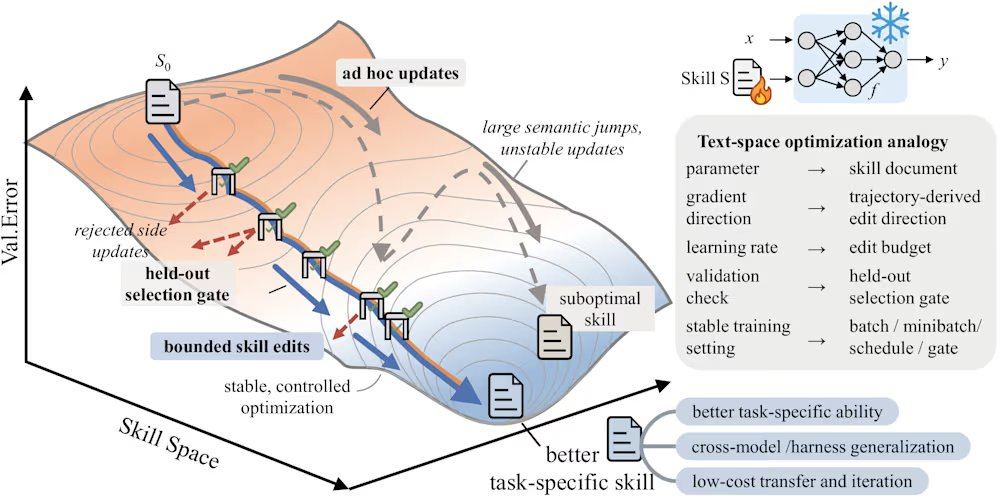
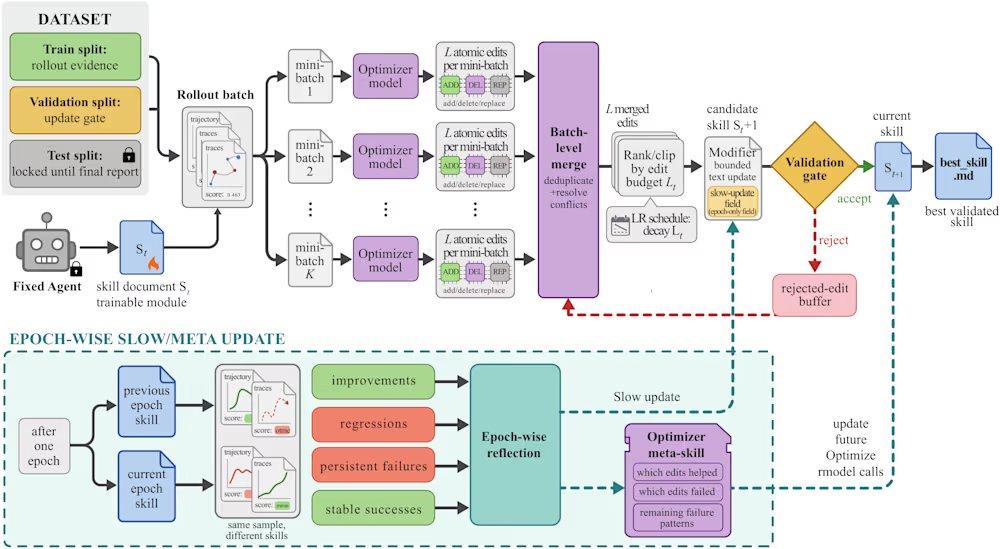
SkillOpt löst diese Probleme durch einen iterativen Vorschlag-Test-Zyklus. Der Prozess beginnt damit, dass ein eingefrorenes Zielmodell eine Reihe von Aufgaben ausführt und Ausführungsspuren als Nachweis des aktuellen Zustands generiert. Anschließend analysiert ein Offline-Optimierer diese Spuren, identifiziert systematische programmatische Fehler und schlägt strukturelle Bearbeitungen der Fähigkeitsdokumente vor. Diese Bearbeitungen werden vor ihrer Anwendung geprüft und priorisiert, und das maximale Bearbeitungsbudget pro Schritt wird begrenzt (ähnlich der Lernrate im Deep Learning), um starke Drift der Fähigkeitsversionen zu verhindern. Kandidatenfähigkeiten werden an einem zurückgehaltenen Validierungssatz bewertet; bei Verbesserung der Validierungspunktzahl werden sie akzeptiert, bei Misserfolg abgelehnt und in einen Puffer für abgelehnte Bearbeitungen aufgenommen, der dem Optimierer negatives Feedback liefert. Darüber hinaus führt das Framework eine langsame Aktualisierung durch, indem es die Aufgabenleistung unter den Fähigkeiten aufeinanderfolgender Runden vergleicht, ähnlich einem Momentum-Term, um dauerhafte programmatische Erfahrungen zu vermitteln.
In praktischen Evaluierungen testete das Forschungsteam SkillOpt auf verschiedenen Modellen wie GPT-5.5, GPT-5.4-mini und Qwen3.5-4B, die Benchmarks für einstufige Frage-Antwort-Aufgaben, mehrstufige Codegenerierung und multimodale Dokumenteninferenz abdeckten. Die Ergebnisse zeigen, dass SkillOpt in allen 52 Evaluierungskombinationen besser abschnitt als verschiedene Basislinienmethoden, darunter TextGrad, GEPA und EvoSkill. Beim Spitzenmodell GPT-5.5 wurde eine durchschnittliche absolute Genauigkeitssteigerung von 23,5 Prozentpunkten im Vergleich zur Basislinie ohne Fähigkeiten erzielt. Bei kleineren Modellen wie GPT-5.4-nano verdoppelten oder verdreifachten sich die Punktzahlen nahezu. Diese Leistungssteigerungen lassen sich direkt auf kritische Unternehmensanforderungen abbilden, wie die präzise Extraktion von Zahlen aus Verträgen, Rechnungen und Tabellen sowie operative Prozesse wie AP-Automatisierung, Schadensbearbeitung und Compliance. Yang erklärt, dass die Verbesserung in der Zuverlässigkeit liegt, einschließlich präziser Formatierung, Selbstvalidierung und prüfbarer Ausgaben – diese Gewinne resultieren aus dem Lernen von Verfahren, nicht dem Auswendiglernen von Antworten.
Das SkillOpt-Framework zeigt gute Portabilität und Kompatibilität. Experimente bestätigen, dass das Framework ausführungsunabhängig ist und in von Tools wie Codex CLI und Claude Code unterstützten Ausführungsumgebungen signifikante Verbesserungen erzielt. Beispielsweise kann eine vollständig innerhalb der Codex-Schleife trainierte Tabellenkalkulationsfähigkeit ohne Änderungen direkt auf Claude Code übertragen werden und treibt dort eine Leistungssteigerung von bis zu 59,7 Prozentpunkten im Vergleich zur nativen Claude-Code-Basislinie an. Darüber hinaus können Fähigkeitsartefakte zwischen verschiedenen Modellgrößen migriert werden; für GPT-5.4 optimierte Fähigkeiten, die auf kleinere Modelle wie GPT-5.4-mini und GPT-5.4-nano übertragen werden, erzielen weiterhin positive Ergebnisse. Die endgültig bereitgestellten Fähigkeitsdokumente überschreiten nie 2000 Token, mit einer mittleren Länge von etwa 920 Token, und sind hochgradig lesbar und prüfbar.
In Bezug auf die Kosten ist die tatsächliche Belastung durch SkillOpt für alltägliche Unternehmensanwendungsfälle gering. Yang erwähnt, dass in Community-Frameworks wie GBrain die SkillOpt-Aktualisierung auf Claude Sonnet läuft und die durchschnittlichen Kosten für das Training einer Fähigkeit für eine einzelne Aufgabe zwischen 1 und 5 US-Dollar liegen, wobei diese Optimierungskosten einmalig anfallen. Für einen effektiven Betrieb des Frameworks sind jedoch zwei Bedingungen erforderlich: Dutzende repräsentativer Beispiele und ein bewertbares Feedbacksignal. Teams sollten die Anwendung auf offene oder subjektive Aufgaben vermeiden. Gleichzeitig kann SkillOpt mit bestehenden Orchestrierungs-Stacks (wie DSPy) zusammenarbeiten; beide ergänzen sich, anstatt sich gegenseitig zu ersetzen. Mit Blick auf die Zukunft hat die Open-Source-Community bereits damit begonnen, regelmäßige SkillOpt-Läufe auf vergangenen Agentenspuren zu deployen, um ein Ökosystem selbstoptimierender Code-Agenten-Plugins aufzubauen. Yang ist der Ansicht, dass Fähigkeiten der schnellste, günstigste und am besten umkehrbare erste Schritt für KI sind, um autonom Wissen zu entdecken und ihr eigenes Verhalten zu verbessern – dieselbe Denkweise führt dazu, dass Agenten sich letztendlich selbst optimieren, bis hin zu ihren eigenen Gewichten.
Dieser Artikel wurde von Wedoany übersetzt und bearbeitet. Bei jeglicher Zitierung oder Nutzung durch künstliche Intelligenz (KI) ist die Quellenangabe „Wedoany“ zwingend vorgeschrieben. Sollten Urheberrechtsverletzungen oder andere Probleme vorliegen, bitten wir Sie, uns unverzüglich zu benachrichtigen. Wir werden den entsprechenden Inhalt umgehend anpassen oder löschen.
E-Mail: news@wedoany.com















