
de.wedoany.com-Bericht: Das von der chinesischen Firma Zhipu AI entwickelte Modell GLM-5.2 hat im Bereich der KI-Programmierung beachtliche Erfolge erzielt. Im Arena-Ranking belegt es weltweit den zweiten Platz und unter den Open-Source-Modellen den ersten Platz. In der Design Arena, die speziell den Geschmack von Modellen bewertet, erreichte GLM-5.2 den ersten Platz weltweit.
Die Arena-Verantwortlichen bezeichneten die Leistung von GLM-5.2 als „einen unglaublichen Meilenstein".
In der Design Arena erzielte GLM-5.2 den ersten Platz weltweit.
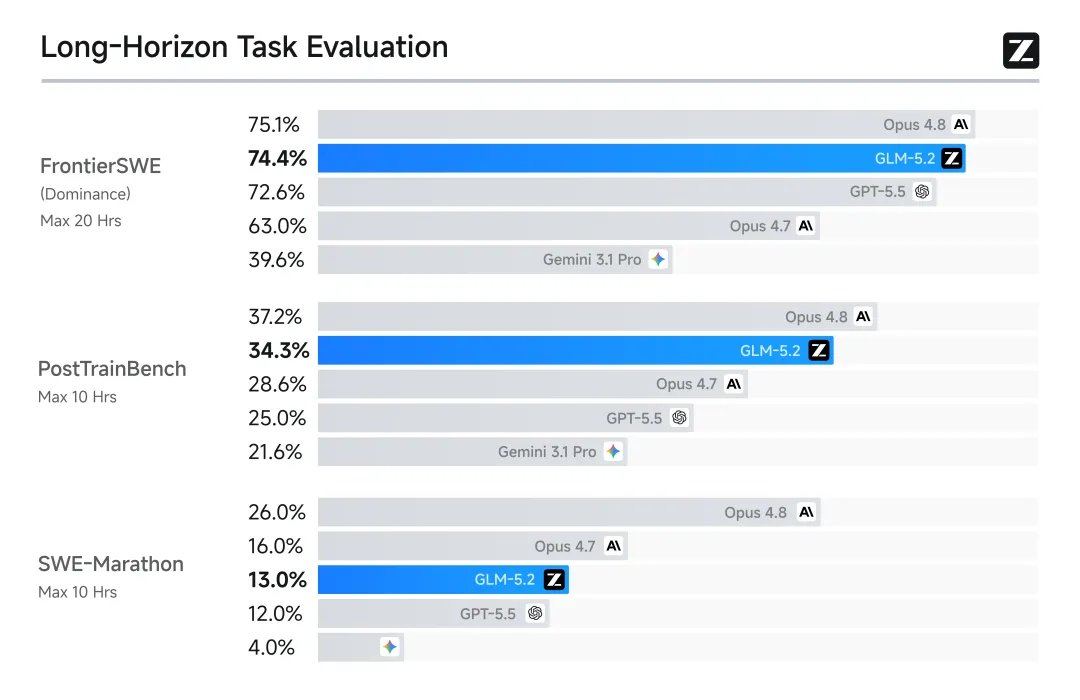
In acht maßgeblichen Benchmark-Tests zeigte GLM-5.2 herausragende Leistungen.
Den Ergebnissen zufolge hat sich ein inländisches Open-Source-Großmodell erstmals unter den weltweit drei besten im Coding-Bereich platziert und gehört damit zur ersten Liga mit Claude und OpenAI. Das zuvor viel diskutierte Google Gemini wurde in den Ranking-Fähigkeiten von GLM-5.2 abgelöst.
Ausländische Blogger führten mehrere praktische Tests durch und verglichen GLM-5.2 mit GPT-5.5 High, Opus 4.8 High und Kimi K2.7 Code.
Ein Blogger ist der Meinung, dass dieser Test die KI-Fähigkeiten gut widerspiegelt, und die Leistung von GLM-5.2 kommt bereits an Claude Opus 4.8 heran. Ein anderer Blogger äußerte nach dem Test: „This is crazy".
GLM-5.2 unterstützt einen wirklich nutzbaren 1M-Kontext und behält bei langlaufenden Aufgaben die Führung. Dies bedeutet, dass es projektebene Kontexte verarbeiten und über mehrere Stunden hinweg autonom voranschreiten kann.
Für den Test wurde das Appsmith-Projekt auf GitHub verwendet, eine Open-Source-Low-Code-Plattform zur Erstellung von Dashboards, Admin-Panels und anderen internen Anwendungen.
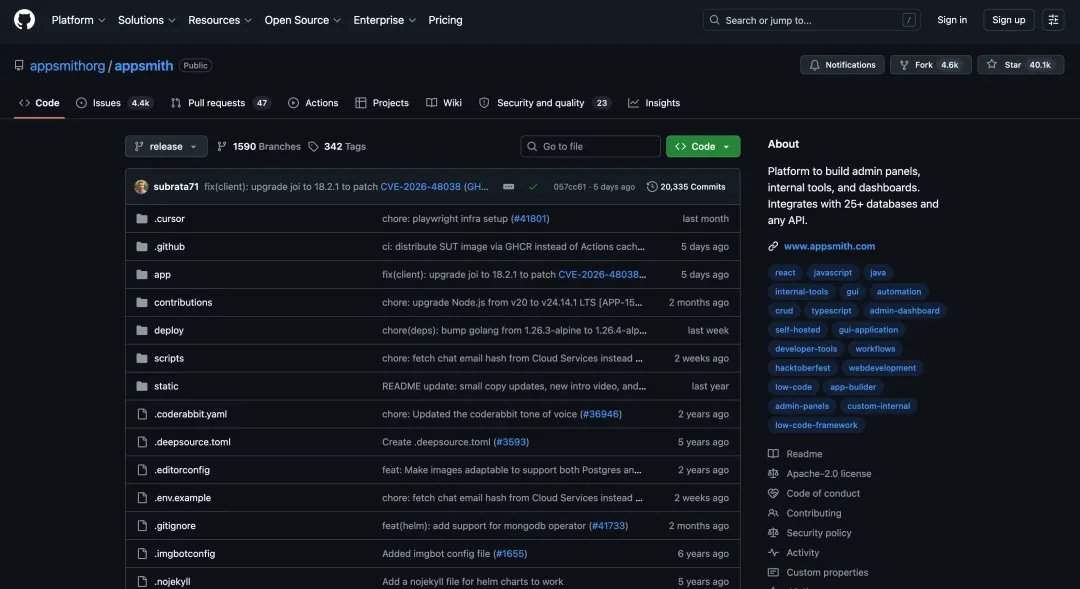
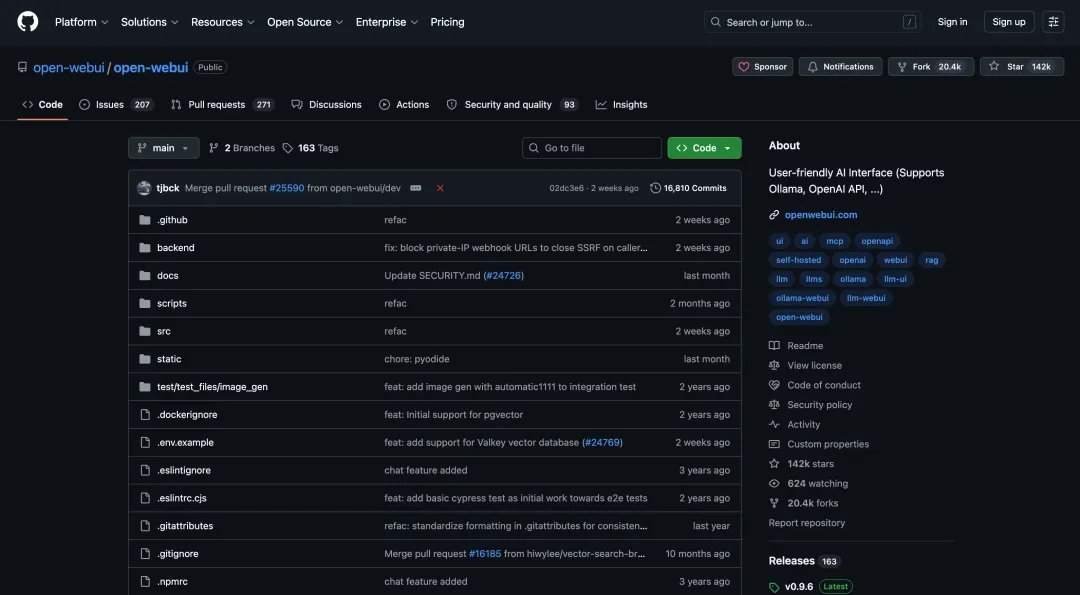
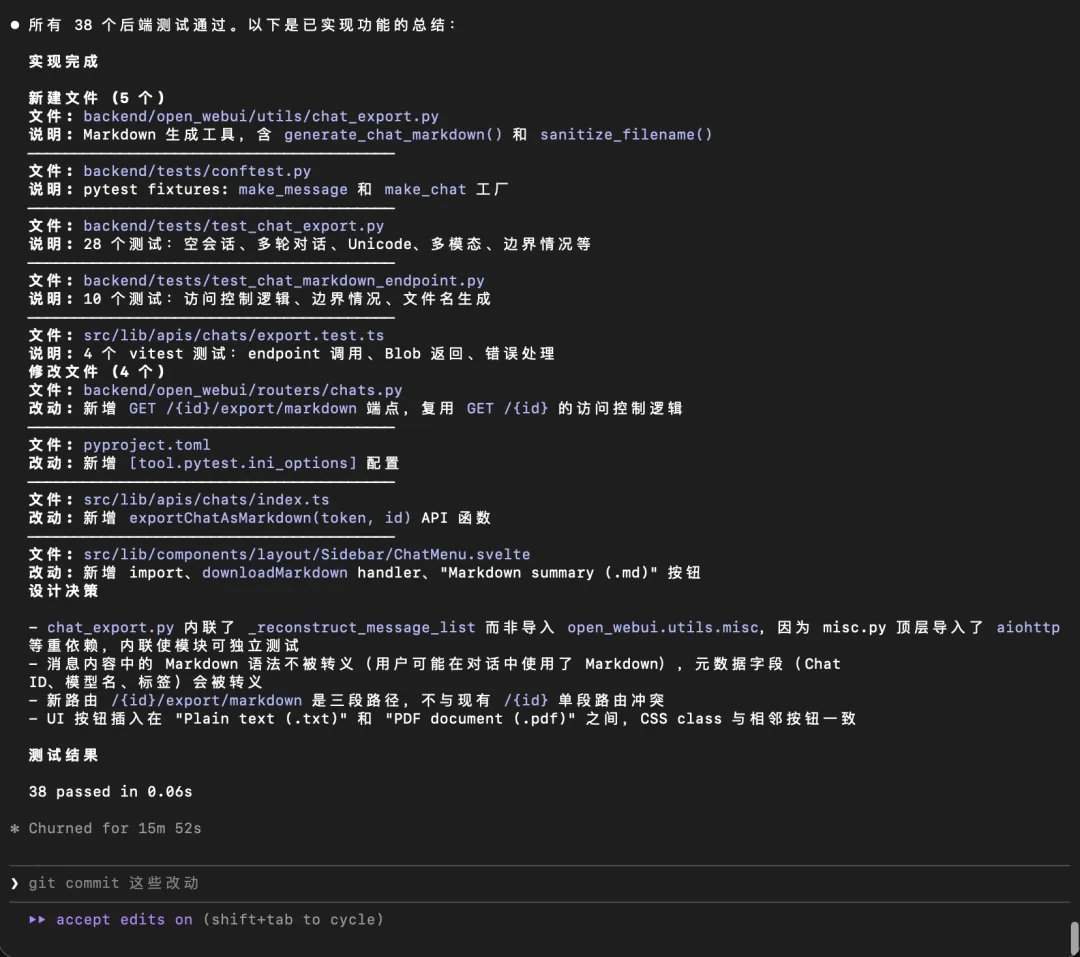
In praktischen Tests zeigte GLM-5.2 in Szenarien wie dem Verständnis des vollständigen Codebestands, der Fehlersuche über mehrere Dateien hinweg, der Implementierung neuer Funktionen und der Multitasking-Verarbeitung gute Leistungen. Im Appsmith-Projekt zerlegte es das Projekt in eine Monorepo-Struktur, lokalisierte präzise das Frontend, Backend und die Aufteilungsverzeichnisse und identifizierte mehrere kritische Kopplungspunkte. Im OpenWebUI-Projekt gelang es ihm, das Grenzproblem des DirectConnection-Streaming-Rückflusses zu lokalisieren und eine Reparaturlösung vorzuschlagen. Im Test neuer Funktionen zerlegte es die Funktion „Markdown-Export" in fünf Ebenen: Backend-Tool, Routing, Frontend-API, UI-Einstieg und Tests, und bestand 38 Backend-Tests. Im Multitasking-Test generierte es auf einmal einen vollständigen Satz von Analyseberichten, Tabellen, Diagrammen und Skripten.




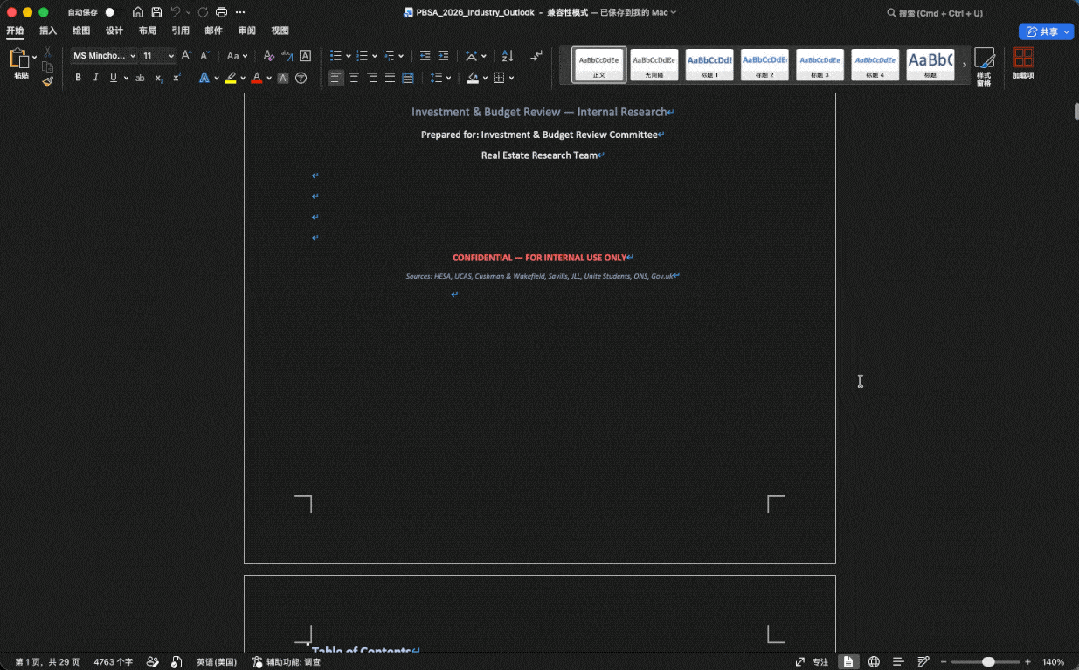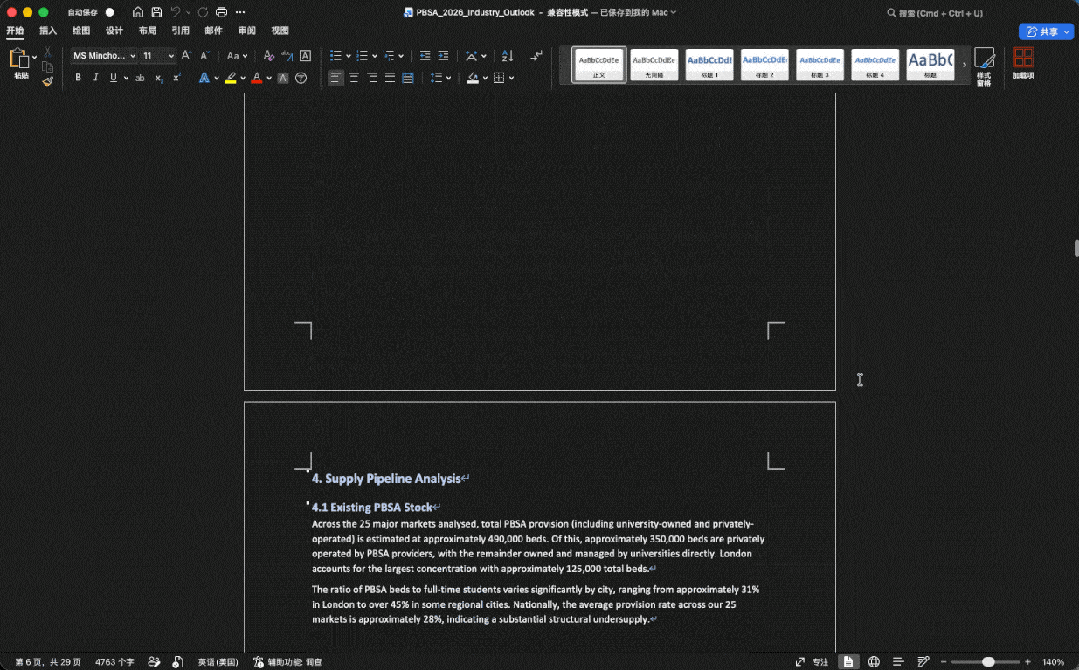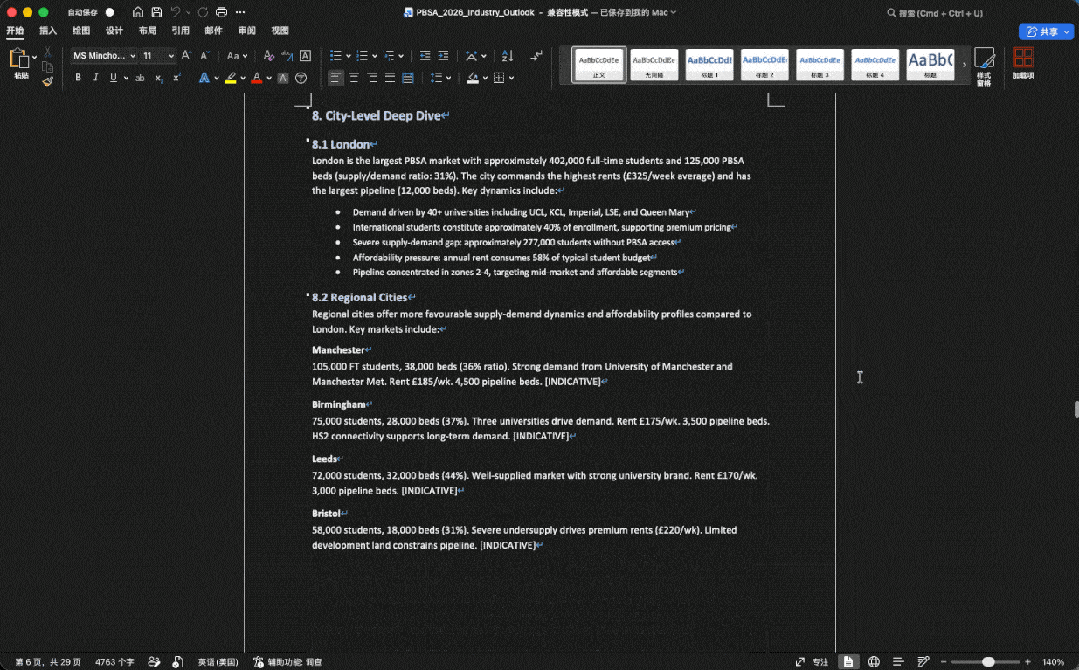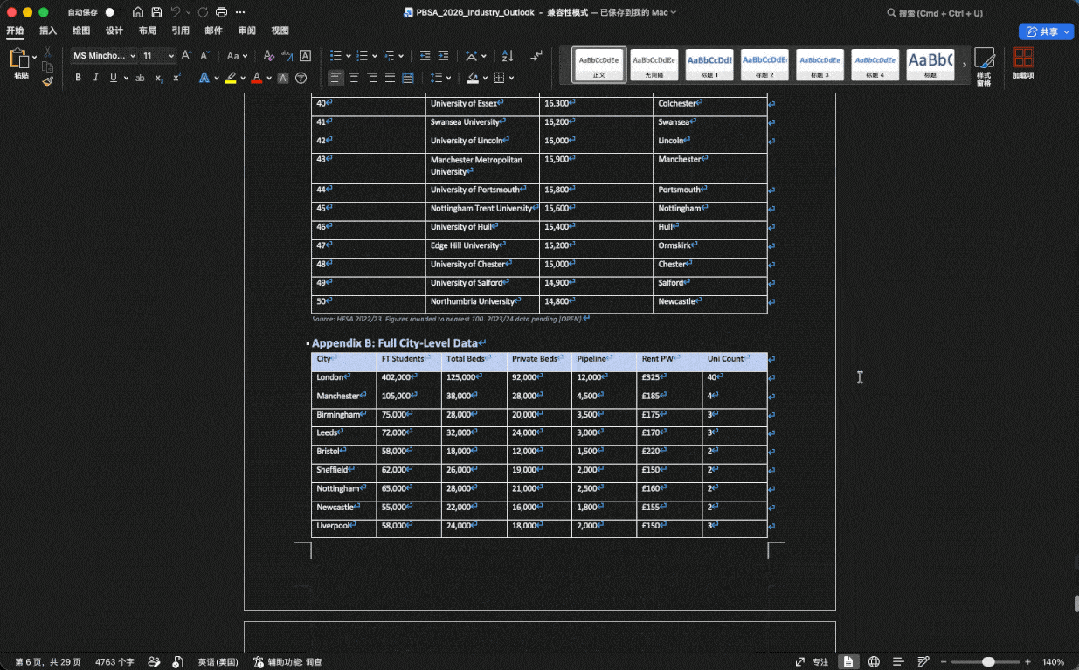
Experten weisen darauf hin, dass der Wettbewerb im KI-Programmierbereich in die Phase der langfristigen Arbeitsfähigkeit eintritt. Derzeit beginnen Entwickler, Modelle in reale Engineering-Workflows zu integrieren. Das Modell muss das gesamte Projekt lesen, die Architektur verstehen, Aufrufketten verfolgen, Anforderungsbeschränkungen einhalten, mehrere Dateien ändern, Tests ergänzen und Dokumentationen generieren. In diesem Zusammenhang bildet der von GLM-5.2 repräsentierte Weg einer offenen, langen Kontext- und auf reale Engineering-Aufgaben ausgerichteten Coding-Agent-Basis die dritte Option neben Claude Code und OpenAI CodeX.
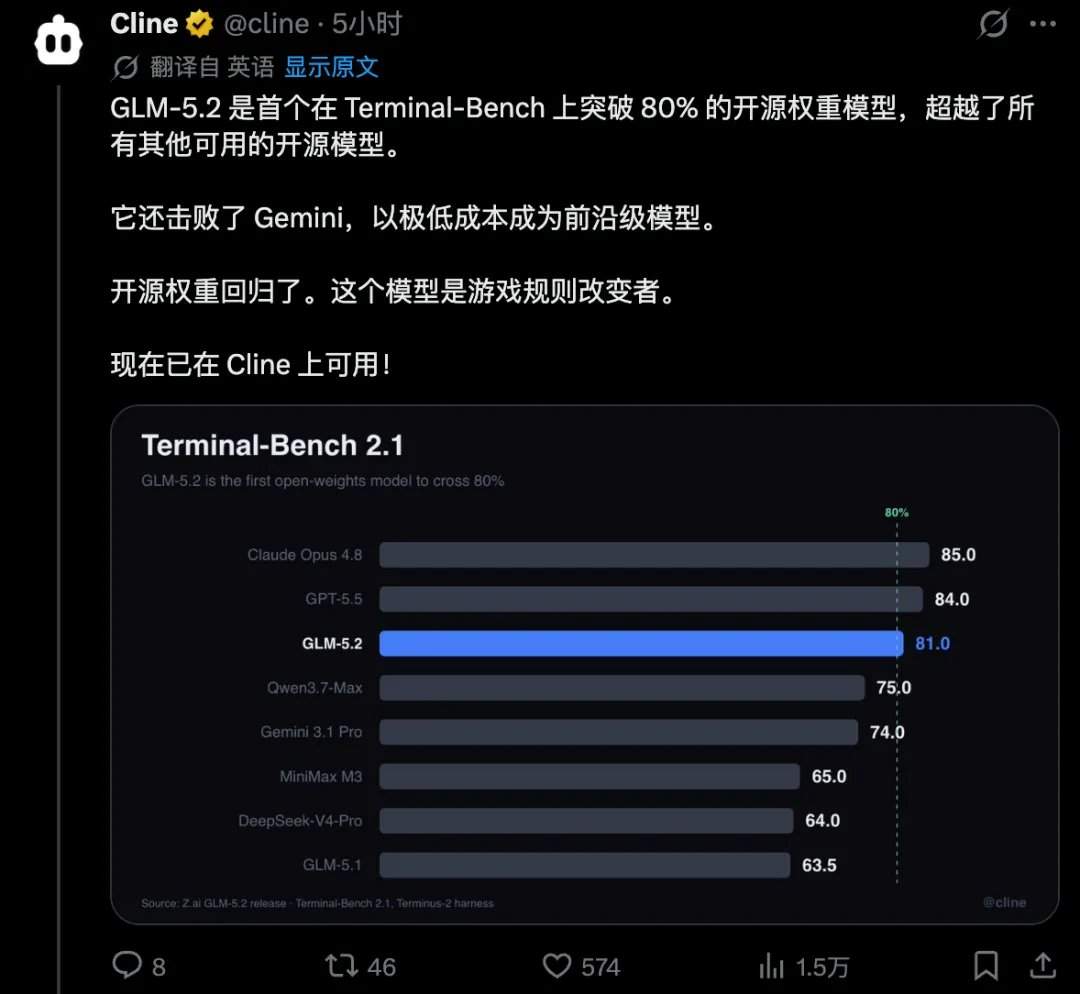
Dieser Artikel wurde von Wedoany übersetzt und bearbeitet. Bei jeglicher Zitierung oder Nutzung durch künstliche Intelligenz (KI) ist die Quellenangabe „Wedoany“ zwingend vorgeschrieben. Sollten Urheberrechtsverletzungen oder andere Probleme vorliegen, bitten wir Sie, uns unverzüglich zu benachrichtigen. Wir werden den entsprechenden Inhalt umgehend anpassen oder löschen.
E-Mail: news@wedoany.com










