
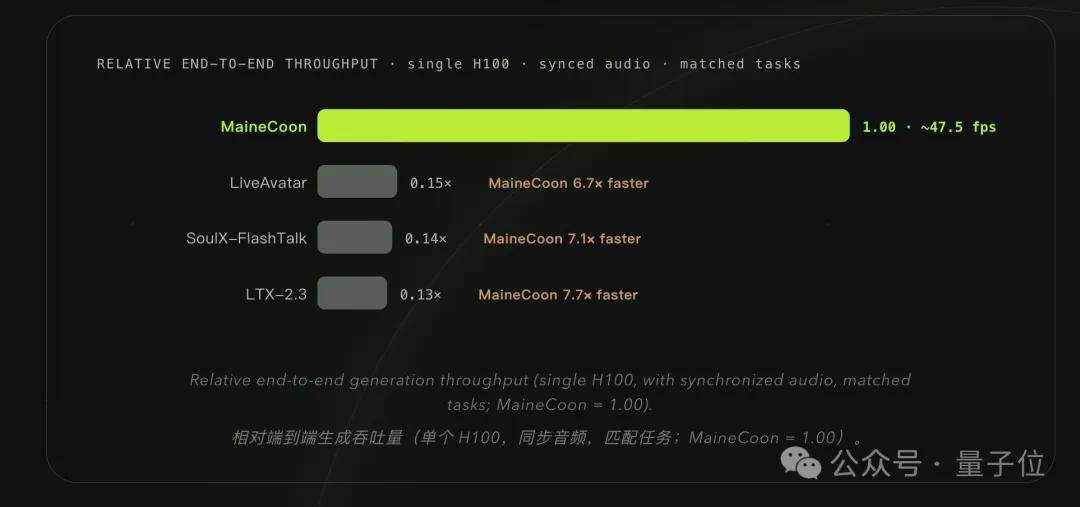
de.wedoany.com-Bericht: Das chinesische Startup-Team Catnip hat kürzlich das Streaming-Audio-Video-Modell MaineCoon vorgestellt. Dieses Modell ermöglicht eine Echtzeit-Synchronisation von Audio und Video über einen Zeitraum von bis zu 30 Minuten oder länger und erreicht auf einer einzelnen H100 GPU eine Inferenzgeschwindigkeit von 47,5 FPS, wobei die Kosten pro Sekunde unter 0,001 US-Dollar gehalten werden können.
MaineCoon wurde von dem nur zehnköpfigen Startup-Team Catnip entwickelt, dessen Hauptsitz in China liegt. Das Projekt wurde offiziell im März dieses Jahres gestartet, und drei Kernforscher haben innerhalb von zwei Monaten die gesamte Stack-Lieferung von Modelltraining, Architekturentwurf, Dateninfrastruktur und Inferenzsystem abgeschlossen.
Im Gegensatz zu herkömmlichen Audio-Video-Generierungsmodellen konzentriert sich MaineCoon erstmals auf soziale Interaktionen als Anwendungsszenario. Das Modell unterstützt die gleichzeitige Generierung und Wiedergabe von Audio und Video, wobei der erste Frame innerhalb einer Sekunde nach der Befehlsausgabe erscheint. Bei voller GPU-Auslastung können die Inferenzkosten pro Sekunde auf 0,00025 US-Dollar gesenkt werden, was 1/2000 der Kosten von Veo 3 und 1/560 der Kosten von Seedance entspricht. Das Modell hat 22 Milliarden Parameter und läuft stabil auf einer einzelnen H100, wobei es sogar auf der kostengünstigeren RTX Pro 6000 Inferenzkarte eine Echtzeit-Geschwindigkeit von über 30 FPS beibehält.

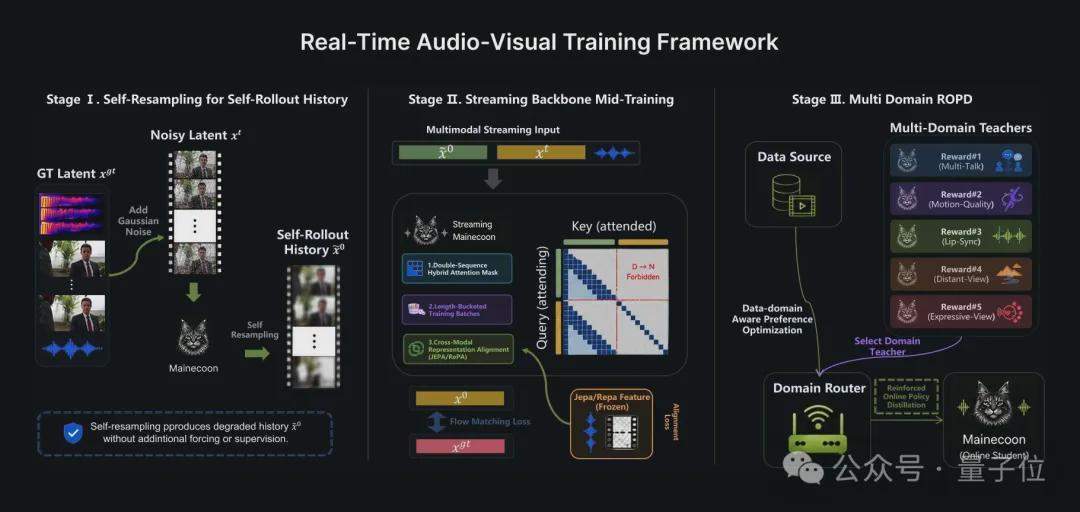
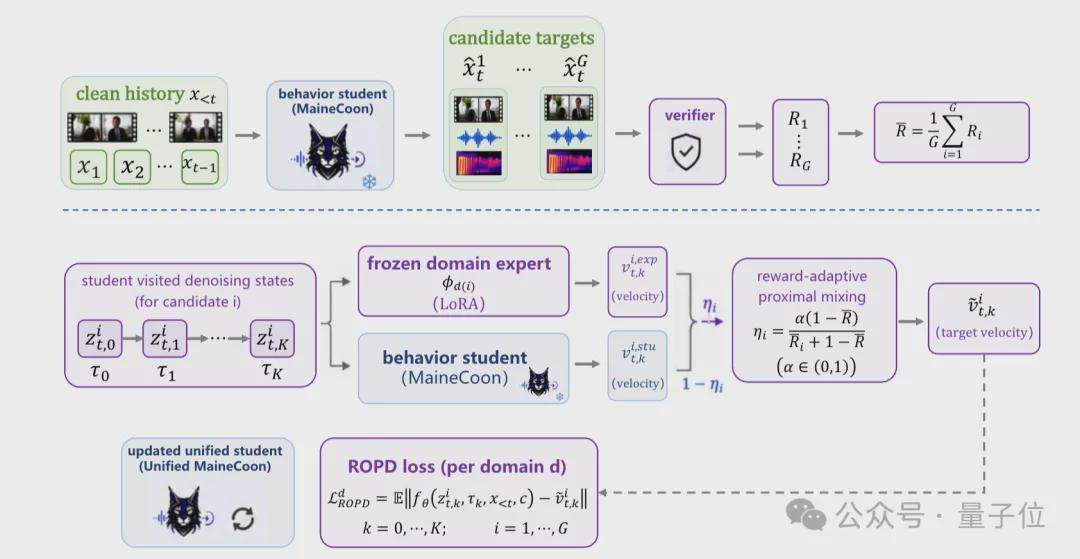
Das Catnip-Team hat im technischen Bericht detailliert die Trainings- und Inferenzarchitektur von MaineCoon vorgestellt. Das Trainingsframework besteht aus drei Phasen: Self-Resampling überbrückt die Lücke zwischen Training und Inferenz; Representation Alignment beschleunigt die Konvergenz des gemeinsamen Audio-Video-Trainings durch Einfrieren des vortrainierten visuellen Encoders V-JEPA 2; Domain-Aware Preference Optimization (DPO) in Kombination mit Reinforcement Online Policy Distillation (ROPD) trainiert spezialisierte Präferenz-Expertenmodelle für verschiedene soziale Szenarien. Das gesamte Modell wurde auf 64 H100 GPUs mit weniger als einer Million Datenpunkten und einem Aufwand von 10.000 GPU-Stunden trainiert.
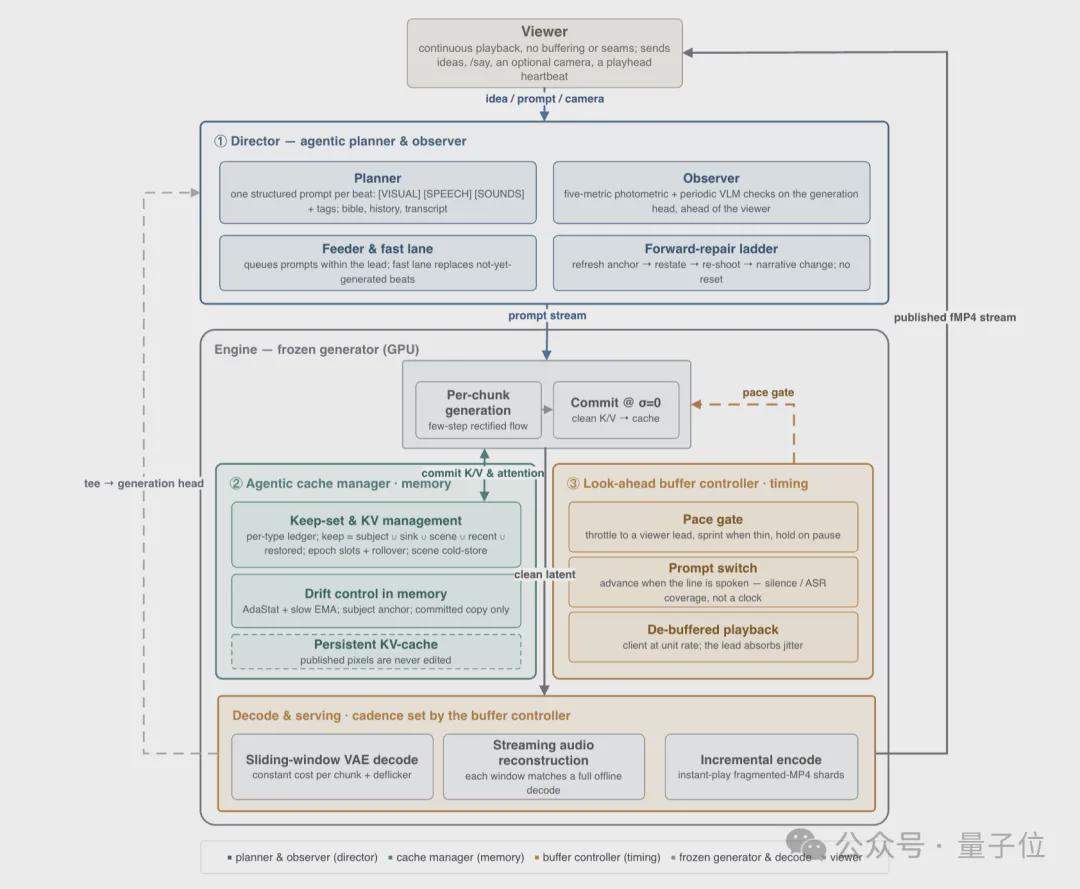
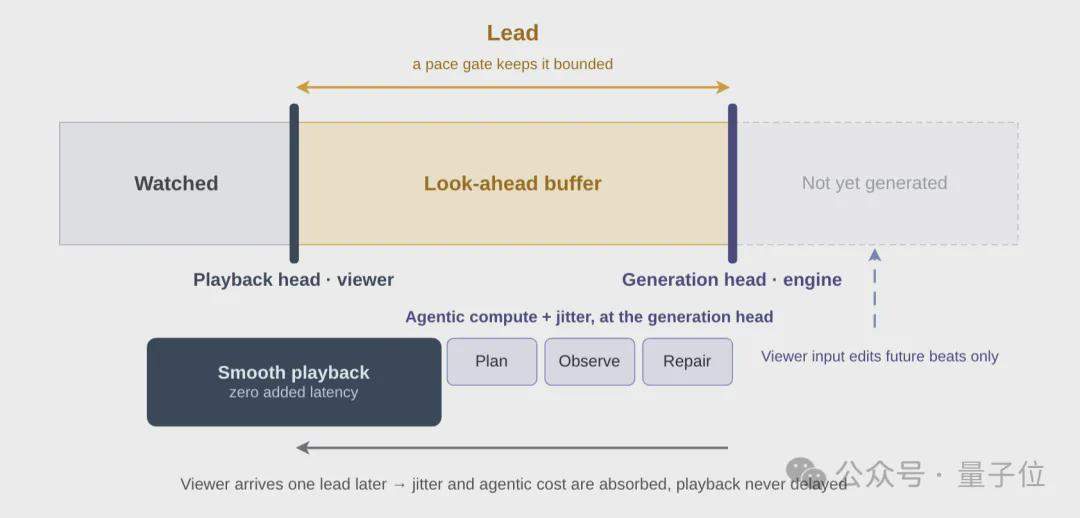
Auf der Inferenzseite wird ein agentisches Inferenzframework verwendet, das aus drei unabhängigen intelligenten Controllern besteht: Der Director ist für die Narration und Fehlerkorrektur zuständig, generiert taktweise strukturierte Prompt-Wörter über einen Planer und überwacht die Generierungsqualität über einen Observer; der Cache Manager verwaltet die Beibehaltungs- und Löschstrategien des KV-Cache und behandelt Charakterdarstellungen, Szenenaufbauframes usw. als Langzeitgedächtnisanker; der Buffer Controller steuert den Vorauspuffer und schafft ein Gleichgewicht zwischen Echtzeitfähigkeit und Interaktionsreaktionsfähigkeit.
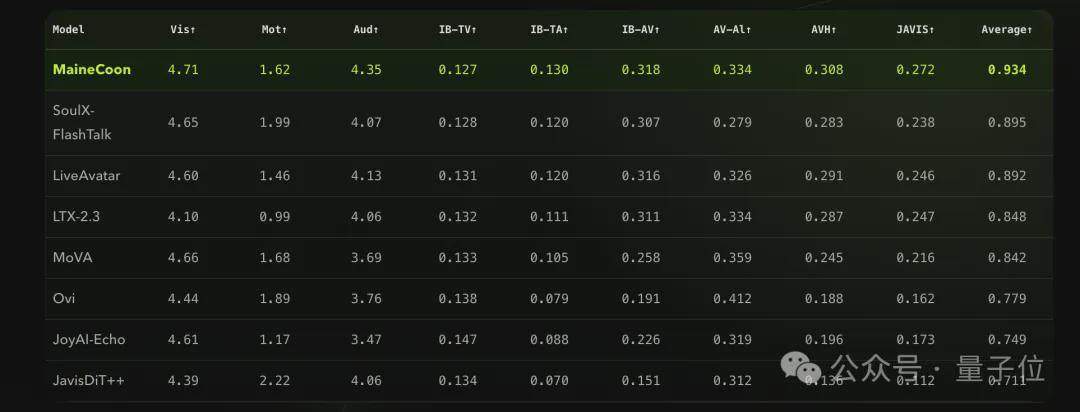
Das Catnip-Team hat außerdem den ersten speziellen Benchmark für soziale Kurzvideos, SocialVideo Bench, erstellt, der sieben Szenarien abdeckt: dichte Reden, Zwei-Personen-Interaktionen, Musikgesang, emotionale Darbietungen, Tanz, kreative Herausforderungen und soziale Memes. Die Bewertung zeigt, dass MaineCoon eine Gesamtpunktzahl von 0,934 erreicht und damit sieben gängige Audio-Video-Generierungsmodelle wie SoulX-FlashTalk (0,895) übertrifft.
Das Catnip-Team hat erstmals das Konzept eines „sozialen Weltmodells" vorgeschlagen, das drei Ebenen umfasst: die Wahrnehmungsebene (Lesen der Emotionen des Benutzers), die Simulationsebene (Vorhersage sozialer Verhaltensweisen) und die Rendering-Ebene (Echtzeit-Generierung von Audio und Video). MaineCoon wird als Durchbruch auf der Rendering-Ebene angesehen. Das Team plant, als nächsten Schritt das Halbduplex-Interaktionsmodus traditioneller KI-Dialoge zu überwinden, um eine menschliche, kontinuierliche, verschränkte, multimodale Echtzeit-Zwei-Wege-Interaktion zu erreichen und das Modell in eine interaktive Content-Plattform zu überführen.
Die Gründerin des Teams, Yang Shurui, war zuvor bei TikTok und PixVerse tätig und für die Produkteinführung von viralen Vorlagen-Effekten verantwortlich; sie hat auch Erfahrung als Seriengründerin. Der Chefwissenschaftler Xie Zeke ist Assistenzprofessor an der Hong Kong University of Science and Technology (Guangzhou) und hat einen Bachelor-Abschluss von der University of Science and Technology of China sowie einen Doktortitel von der University of Tokyo. Er war zuvor am Baidu Research Institute an der Spitzenforschung zu großen Modellen beteiligt und ist seit langem Bereichsvorsitzender für führende KI-Konferenzen wie NeurIPS, ICLR und ICML. Die anderen Teammitglieder sind hauptsächlich Hochschulabsolventen.
Das Catnip-Team hatte zuvor den technischen Bericht auf der Social-Media-Plattform X veröffentlicht, was sofort breite Aufmerksamkeit erregte, und auch das LTX-Team suchte aktiv nach einer Zusammenarbeit. Das Team gab bekannt, dass es bereits zu Beginn des Jahres in Folge Seed-Finanzierungsrunden von Investmentinstitutionen wie Sequoia und Mingshi erhalten hat.

Dieser Artikel wurde von Wedoany übersetzt und bearbeitet. Bei jeglicher Zitierung oder Nutzung durch künstliche Intelligenz (KI) ist die Quellenangabe „Wedoany“ zwingend vorgeschrieben. Sollten Urheberrechtsverletzungen oder andere Probleme vorliegen, bitten wir Sie, uns unverzüglich zu benachrichtigen. Wir werden den entsprechenden Inhalt umgehend anpassen oder löschen.
E-Mail: news@wedoany.com










