de.wedoany.com-Bericht: Die von Liu Fangfu, Doktorand an der Tsinghua-Universität, als Erstautor gemeinsam mit mehreren Forschern verfasste Arbeit zur multimodalen räumlichen Intelligenz Spatial-TTT wurde kürzlich von der führenden Computer-Vision-Konferenz ECCV 2026 offiziell angenommen. Die Arbeit konzentriert sich auf die Lösung des Problems der fließenden räumlichen Intelligenz multimodaler großer Modelle in der realen physischen Welt, d. h. wie das Modell in einem sich ständig ändernden Videostream räumliche Erinnerungen bilden und kontinuierlich aktualisieren kann, anstatt jede Eingabe als unabhängiges Segment zu betrachten.
Reale Szenarien wie Roboternavigation, autonomes Fahren und erweiterte Realität erfordern, dass Modelle weit über die Fähigkeit zur statischen Bildverständnis hinausgehen. Herkömmliche Methoden, die lange Videostreams von mehreren zehn Minuten oder sogar Stunden verarbeiten, leiden unter fragmentiertem räumlichem Verständnis, da ihnen ein effektiver Mechanismus zur Online-Aktualisierung des Gedächtnisses fehlt. Spatial-TTT wurde entwickelt, um diese Herausforderung zu bewältigen, indem das Konzept des Test-Time Training (TTT) in den Bereich der räumlichen Intelligenz eingeführt wird, sodass das Modell während der Inferenz interne Parameter aktualisieren kann, während es das Video betrachtet.
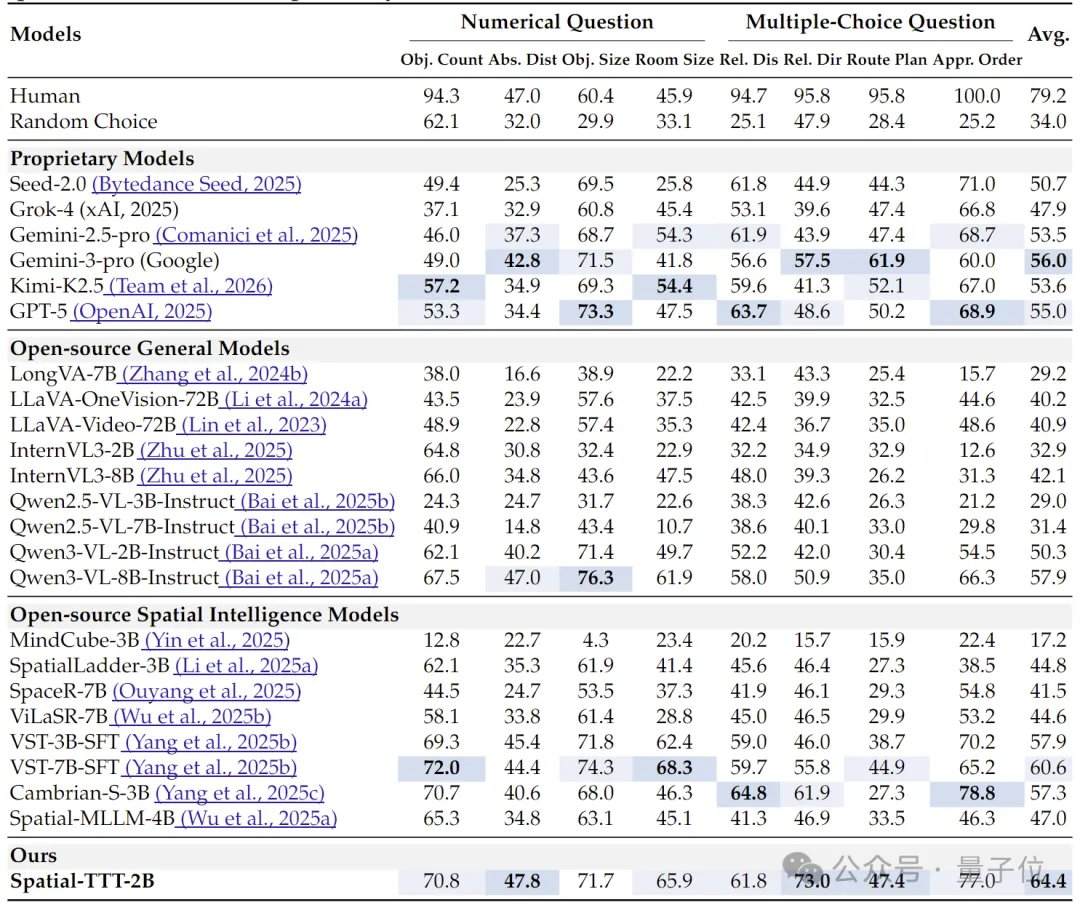
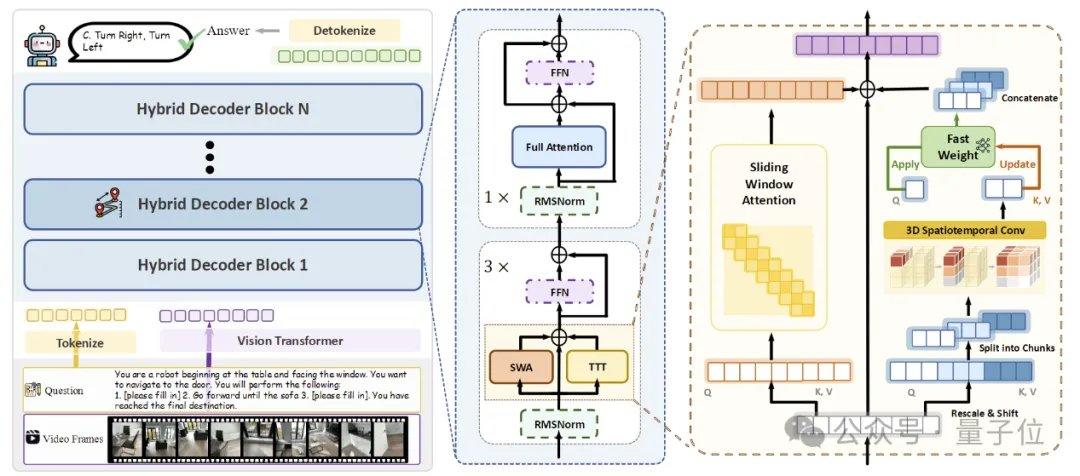
Um ein effizientes fließendes räumliches Gedächtnis zu erreichen, schlug das Forschungsteam drei Schlüsseltechnologien vor. Die erste ist eine hybride TTT-Architektur, bei der im Decoder TTT-Schichten und Standard-Selbstaufmerksamkeits-Ankerschichten im Verhältnis 3:1 verschachtelt werden. Erstere sind für das Schreiben von Langzeitinformationen in schnelle Gewichte zuständig, während Letztere die crossmodale Ausrichtung und semantische Schlussfolgerungsfähigkeit des vortrainierten Modells aufrechterhalten. Die zweite ist ein räumlicher Vorhersagemechanismus, bei dem leichte 3D-Raumzeit-Faltungen in den TTT-Zweig eingeführt werden, damit das Modell die Vorhersagebeziehungen zwischen räumlich-zeitlichen Kontexten lernt und die Stabilität der Online-Aktualisierung verbessert. Die dritte ist eine dichte Szenenbeschreibungsüberwachung, bei der das Modell durch die Konstruktion von Szenenbeschreibungsdaten, die den globalen Kontext, Objektkategorien und räumliche Beziehungen abdecken, trainiert wird, von der „lokalen Beantwortung von Fragen“ zur „Aufrechterhaltung eines globalen 3D-Gedächtnisses“ überzugehen.
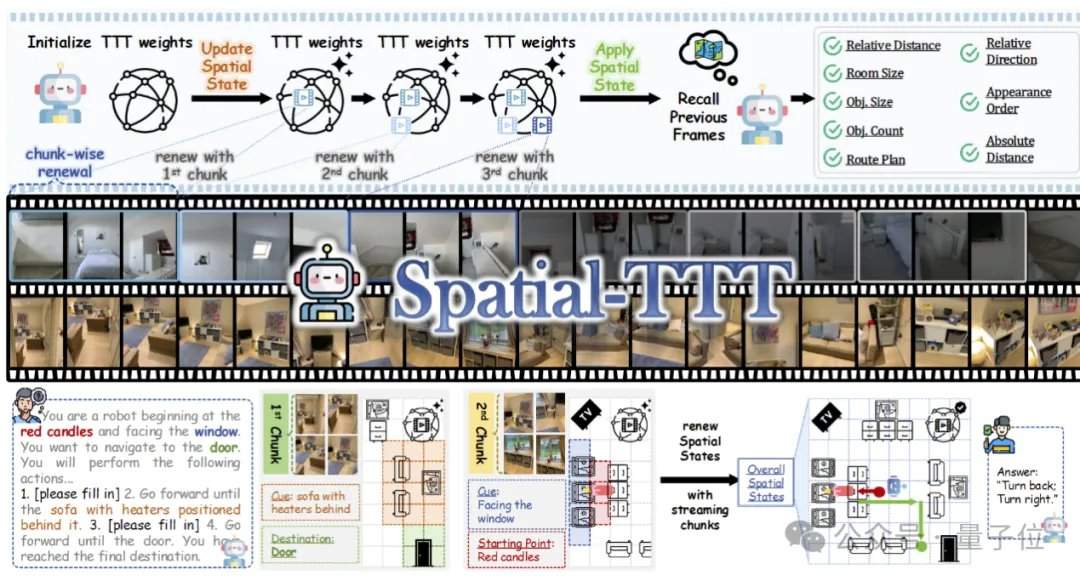
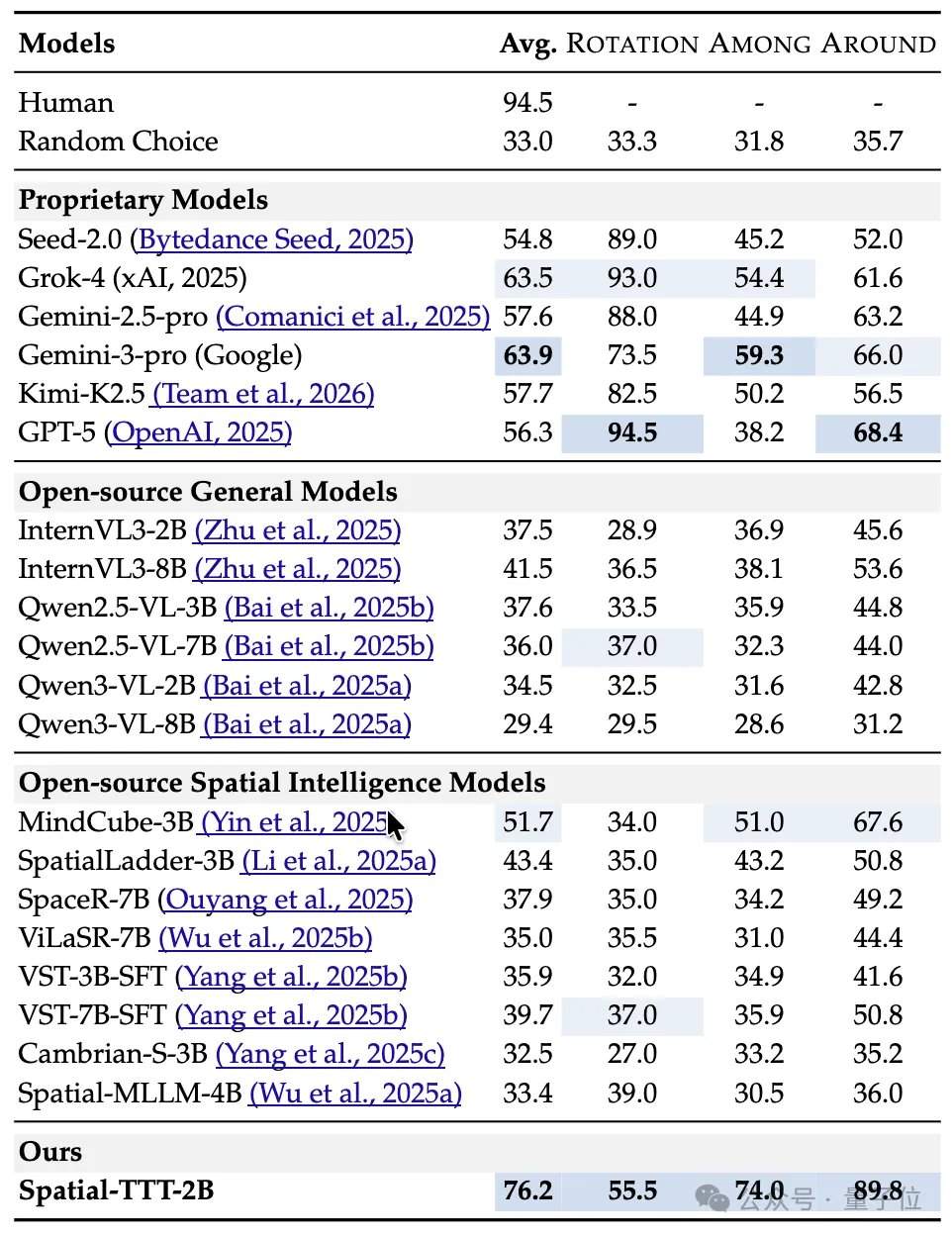
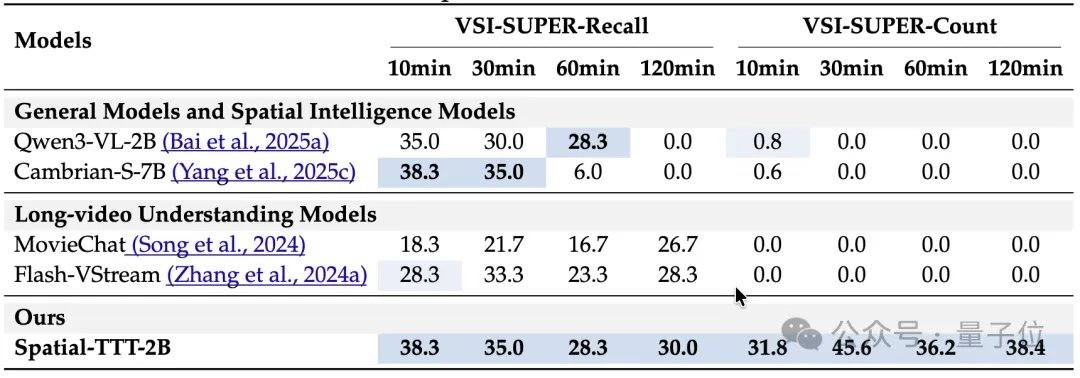
In Bezug auf die experimentellen Ergebnisse zeigte Spatial-TTT mit nur 2B Parametern auf mehreren speziellen räumlichen Intelligenz-Benchmarks deutliche Vorteile. Auf VSI-Bench erreichte es eine durchschnittliche Punktzahl von 64,4 und übertraf damit geschlossene Modelle wie GPT-5 und Gemini-3-pro. Auf dem MindCube-Tiny-Benchmark, der eine feinkörnigere räumliche Schlussfolgerung aus mehreren Perspektiven erfordert, erzielte Spatial-TTT eine Genauigkeit von 76,2 %, 12 Prozentpunkte mehr als Gemini-3-pro (63,9 %) und fast 25 Prozentpunkte mehr als das repräsentative Open-Source-Raummodell MindCube-3B (51,7 %). Bei den VSI-SUPER-Aufgaben, die das Langzeitgedächtnis testen, konnte das Modell stabile Videostreams von bis zu 120 Minuten verarbeiten. Bei der VSI-SUPER-Count-Aufgabe erreichte Spatial-TTT Punktzahlen von 31,8, 45,6, 36,2 bzw. 38,4 für Videos von 10, 30, 60 und 120 Minuten.
Eine Effizienzanalyse zeigt, dass der Spitzen-GPU-Speicherverbrauch von Spatial-TTT-2B bei einer Eingabe von 1024 Frames 11,9 GB beträgt und die theoretische Rechenleistung 799,4 TFLOPs beträgt, was einer Einsparung von über 40 % an Speicher- und Rechenressourcen im Vergleich zu führenden Basismodellen der Branche entspricht. Ablationsstudien bestätigten ferner, dass die Leistungssteigerung auf die synergistische Wirkung der hybriden Architektur, des räumlichen Vorhersagemechanismus und der dichten Überwachungssignale zurückzuführen ist. Konkret: Ohne den räumlichen Vorhersagemechanismus fiel die durchschnittliche Punktzahl auf VSI-Bench von 64,4 auf 62,1; ohne die dichte Szenenbeschreibungsüberwachung auf 61,3; und wenn die hybride Architektur vollständig entfernt und nur eine reine TTT-Struktur verwendet wurde, fiel die durchschnittliche Punktzahl direkt auf 53,9.
Diese in ECCV 2026 aufgenommene Forschung bietet einen neuen technischen Weg für physische Künstliche Intelligenz-Systeme, die einen langfristigen, kontinuierlichen Betrieb erfordern. Indem das Modell räumliche Informationen kontinuierlich sammelt, korrigiert und abruft, werden zukünftige intelligente Agenten nicht mehr mit fragmentierten Einzelbildern konfrontiert sein, sondern in der Lage sein, ein internes Weltmodell aufzubauen, das kontinuierlich ist, verstanden werden kann und in dem sie agieren können.
Paper-Link: https://arxiv.org/pdf/2603.12255
Projektseite: https://liuff19.github.io/Spatial-TTT/
GitHub: https://github.com/THU-SI/Spatial-TTT/
Dieser Artikel wurde von Wedoany übersetzt und bearbeitet. Bei jeglicher Zitierung oder Nutzung durch künstliche Intelligenz (KI) ist die Quellenangabe „Wedoany“ zwingend vorgeschrieben. Sollten Urheberrechtsverletzungen oder andere Probleme vorliegen, bitten wir Sie, uns unverzüglich zu benachrichtigen. Wir werden den entsprechenden Inhalt umgehend anpassen oder löschen.
E-Mail: news@wedoany.com