de.wedoany.com-Bericht: Das chinesische KI-Unternehmen DeepSeek hat am 27. Juni gemeinsam mit der Peking-Universität das DSpark-Inferenzbeschleunigungsframework veröffentlicht, das einen neuen Ansatz für den Engpass der Inferenzeffizienz bei Diensten mit hoher Parallelität großer Modelle bietet. Das Framework basiert auf spekulativem Decoding und verbessert durch eine semi-autoregressive Generierungsstruktur und einen konfidenzbasierten dynamischen Verifikationsmechanismus die Qualität der Draft-Token und reduziert ineffektive Verifikationsberechnungen. Im Online-Dienstsystem von DeepSeek-V4 steigert DSpark die Inferenzgeschwindigkeit im Vergleich zum Basismodell um etwa 60 % bis 85 % und reduziert den Durchsatzverlust in Szenarien mit hoher Parallelität.
Spekulatives Decoding ist einer der wichtigen Ansätze zur Beschleunigung der Inferenz großer Modelle. Bei der Textgenerierung großer Modelle müssen Token normalerweise nacheinander vorhergesagt werden; erst nach der Generierung eines Tokens kann mit der Berechnung des nächsten Tokens fortgefahren werden. Diese autoregressive Methode gewährleistet die kontextuelle Kohärenz, erschwert jedoch die vollständige Parallelisierung des Inferenzprozesses. Die Idee des spekulativen Decodings besteht darin, zunächst ein leichtgewichtiges Draft-Modell mehrere Kandidaten-Token vorab generieren zu lassen, die dann vom Zielmodell verifiziert werden. Werden die Kandidaten-Token akzeptiert, können mehrere Generierungsschritte auf einmal durchgeführt werden, was die Gesamtausgabegeschwindigkeit erhöht.
Das Problem besteht darin, dass bestehende parallele Draft-Generierungsmethoden zwar längere Token-Blöcke auf einmal erzeugen können, die Token jedoch untereinander wenig Zusammenhang aufweisen, sodass spätere Token leichter von der Verteilung des Zielmodells abweichen, was zu einer höheren Ablehnungsrate führt. Abgelehnte Draft-Token bringen nicht nur keine Beschleunigung, sondern verbrauchen auch Rechenleistung für die Verifikation, was insbesondere bei Online-Diensten mit hoher Parallelität zu zusätzlicher Rechenverschwendung führt. DSpark adressiert diesen Schmerzpunkt, indem es dem parallelen Generierungsrückgrat ein leichtgewichtiges sequenzielles Modul hinzufügt, das stärkere Abhängigkeiten zwischen den Draft-Token schafft und die akzeptable Länge der Kandidatensequenzen erhöht.
Die semi-autoregressive Struktur ist das Kerndesign von DSpark. Es kehrt nicht vollständig zur tokenweisen Autoregression zurück und generiert auch nicht einfach den gesamten Draft-Block auf einmal parallel, sondern stellt einen Kompromiss zwischen paralleler Effizienz und sequenzieller Abhängigkeit dar. Das parallele Rückgrat ist für die schnelle Generierung von Kandidatenblöcken verantwortlich, während das leichtgewichtige sequenzielle Modul die kontextuellen Beziehungen zwischen benachbarten Token ergänzt, sodass das Draft-Modell dem Generierungspfad des Zielmodells näher kommt. Dadurch kann das Zielmodell in der Verifikationsphase kontinuierliche Token leichter akzeptieren, und eine einzelne Verifikation kann eine längere Generierungsdistanz vorantreiben.
Ein weiterer Schlüsselmechanismus von DSpark ist die konfidenzbasierte dynamische Verifikation. Die Erfolgswahrscheinlichkeit von Drafts variiert je nach Anfrage, Kontext und Generierungsposition. Wenn das System eine feste Verifikationslänge verwendet, verschwendet es bei Anfragen mit niedriger Erfolgswahrscheinlichkeit Rechenleistung und nutzt bei Anfragen mit hoher Erfolgswahrscheinlichkeit möglicherweise akzeptable Drafts nicht vollständig aus. DSpark passt die Verifikationslänge basierend auf der Erfolgswahrscheinlichkeit der Anfrage und der Systemlast adaptiv an, um Situationen zu vermeiden, in denen „trotz bekanntermaßen niedriger Akzeptanzrate zu lange Drafts verifiziert werden", und kann bei hoher Last Rechenleistung sinnvoller zuweisen.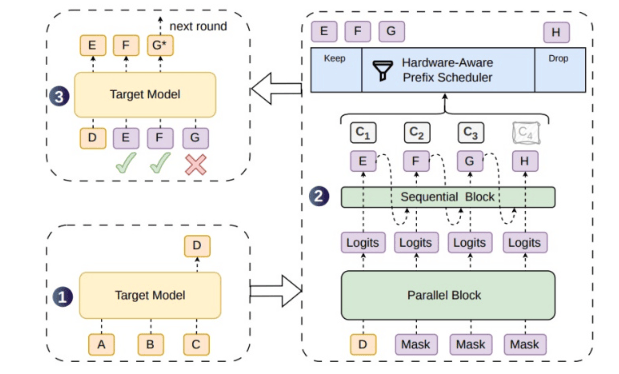
Dieser Mechanismus ist besonders wichtig für die Online-Produktionsumgebung. In Offline-Testumgebungen sind Anfragen in der Regel kontrollierbarer und der Parallelitätsdruck geringer, aber reale große Modelldienste stehen gleichzeitig einer großen Anzahl von Benutzeranfragen gegenüber, die sich in Eingabelänge, Aufgabentyp, Ausgabestil und Generierungsschwierigkeit unterscheiden. Ein Inferenzbeschleunigungsframework, das nur in Experimenten mit kleinen Stichproben effektiv ist, kann eine kommerzielle Bereitstellung kaum unterstützen. DSpark hat im Online-System von DeepSeek-V4 eine Steigerung der Inferenzgeschwindigkeit um 60 % bis 85 % erzielt, was zeigt, dass sein Design bereits für den realen Dienstleistungsdruck validiert wurde und nicht nur eine Optimierung von Laborindikatoren darstellt.
DSpark verbessert auch den Durchsatz bei hoher Parallelität durch die Erhöhung der akzeptablen Generierungslänge. Die Kosten großer Modelldienste resultieren nicht nur aus der Latenz einzelner Anfragen, sondern auch aus der Gesamtdurchsatzkapazität des GPU-Clusters unter hoher Last. Je höher die Qualität der Drafts, desto mehr Token werden bei einer einzelnen Verifikation durch das Zielmodell akzeptiert, und desto höher ist die effektive Ausgabe pro Recheneinheit. Für API-Dienste, Agentensysteme, Codegenerierung, Such-Q&A und unternehmensorientierte KI-Anwendungen bedeutet eine Senkung der Inferenzkosten, dass mit der gleichen Rechenleistung mehr Anfragen bedient werden können oder unter gleichen Kosten schnellere Antwortzeiten erzielt werden.
DeepSeek hat gleichzeitig die Modell-Checkpoints und das Trainingsframework DeepSpec als Open Source veröffentlicht, um der Community eine vollständige Toolchain für die weitere Erforschung spekulativer Decodierungsalgorithmen zu bieten. DeepSpec umfasst das Training von Draft-Modellen, Datenvorbereitung, Evaluierungsskripte und mehrere Algorithmusimplementierungen und unterstützt das Training und den Vergleich von Draft-Modellen wie DSpark, DFlash und Eagle3. Die Bedeutung eines Open-Source-Frameworks liegt darin, dass externe Entwickler und Forschungseinrichtungen es für verschiedene Zielmodelle, verschiedene Aufgabendaten und verschiedene Dienstszenarien reproduzieren, feinabstimmen und evaluieren können, wodurch spekulatives Decoding von einem punktuellen Algorithmus zu einem ingenieurtechnischen Werkzeug wird.
Dieses Ergebnis spiegelt auch wider, dass sich der Wettbewerb bei großen Modellen von der Modellparametergröße auf die Effizienz der Inferenztechnik ausweitet. Die Modellfähigkeit bestimmt die Obergrenze des Dienstes, während die Inferenzgeschwindigkeit und die Stückkosten die Geschwindigkeit der kommerziellen Umsetzung bestimmen. Mit dem zunehmenden Einsatz von Unternehmensanwendungen, Agenten, Programmierassistenten und multimodalen Systemen in der Hochfrequenznutzung verlangen die Benutzer nicht nur, dass das Modell „gut antwortet", sondern auch, dass es „schnell, kostengünstig und stabil bei Parallelität antwortet". DSpark adressiert genau das grundlegende Effizienzproblem, das beim Übergang großer Modelle zu groß angelegten Online-Diensten auftritt.
Die weiteren Schwerpunkte liegen in drei Bereichen: Erstens, ob DSpark eine stabile Beschleunigung bei mehr Modellarchitekturen und mehr Aufgabentypen aufrechterhalten kann; zweitens, ob der dynamische Verifikationsmechanismus in Umgebungen mit extrem hoher Parallelität ineffektive Berechnungen weiter reduzieren kann; drittens, ob die Community nach der Veröffentlichung von DeepSpec als Open Source auf Basis von DSpark mehr spezialisierte Draft-Modelle für Code, Mathematik, Langtexte und Agentenaufgaben entwickeln wird. Da die Inferenzkosten zu einem zentralen variablen Faktor für die Kommerzialisierung großer Modelle werden, werden Inferenzbeschleunigungsframeworks wie DSpark zu einem wichtigen Bestandteil des Wettbewerbs um die KI-Infrastruktur.
Dieser Artikel wurde von Wedoany übersetzt und bearbeitet. Bei jeglicher Zitierung oder Nutzung durch künstliche Intelligenz (KI) ist die Quellenangabe „Wedoany“ zwingend vorgeschrieben. Sollten Urheberrechtsverletzungen oder andere Probleme vorliegen, bitten wir Sie, uns unverzüglich zu benachrichtigen. Wir werden den entsprechenden Inhalt umgehend anpassen oder löschen.
E-Mail: news@wedoany.com