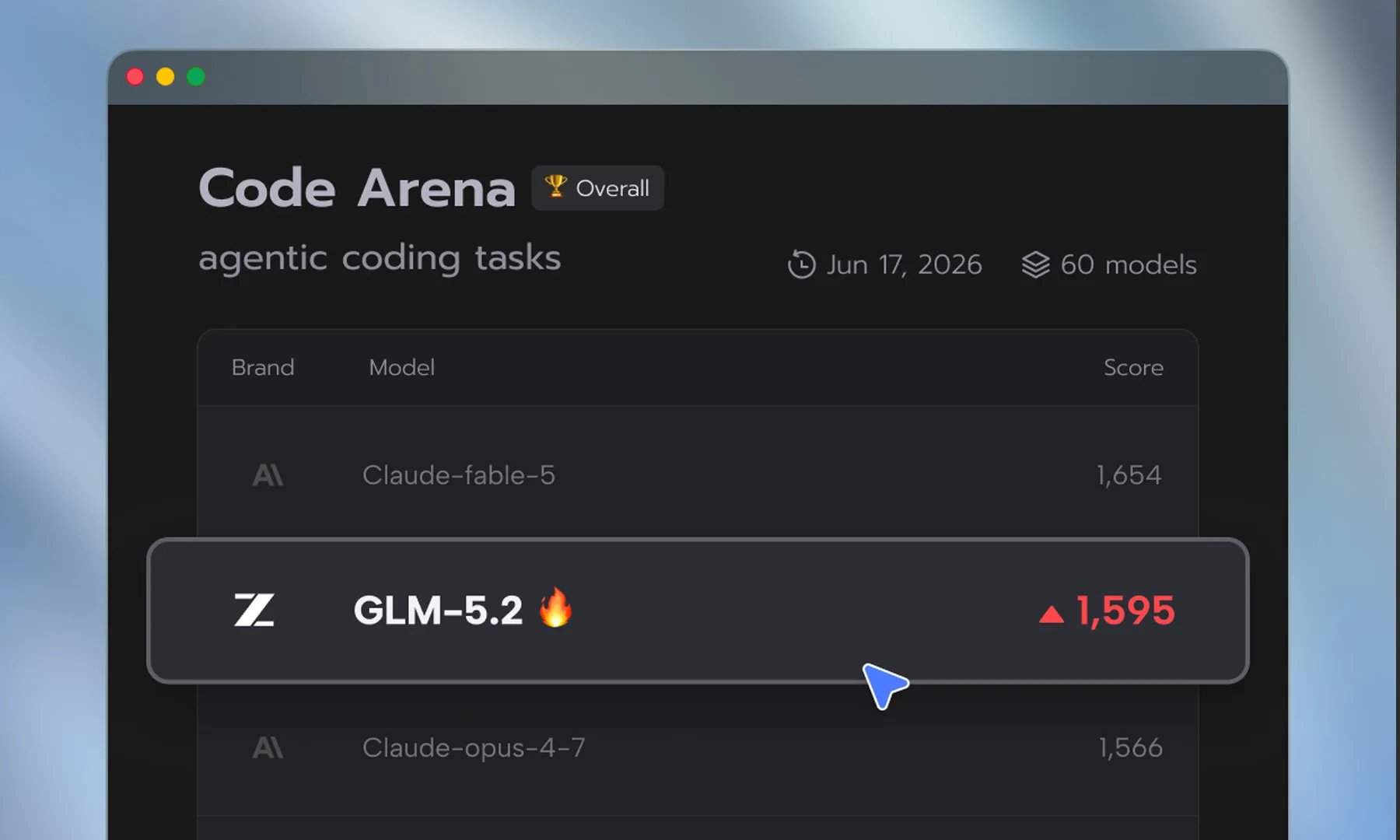
de.wedoany.com-Bericht: Das von dem chinesischen KI-Unternehmen Z.ai entwickelte Modell GLM-5.2 hat bei der Erkennung von Softwaresicherheitslücken eine Leistung erreicht, die mit dem Flaggschiffmodell Mythos von Anthropic vergleichbar ist.

Laut einem Bericht des Wall Street Journal haben Sicherheitsforscher festgestellt, dass GLM-5.2 bei der Identifizierung von Softwarelücken eine mit Mythos vergleichbare Leistung zeigt. Diese Fähigkeit ist in dem Wettlauf der Unternehmen, Schwachstellen zu beheben, bevor Hacker sie ausnutzen können, von entscheidender Bedeutung. Der Bericht weist auch darauf hin, dass GLM-5.2 bei allgemeineren Denkaufgaben immer noch hinter den Modellen von Anthropic und OpenAI zurückbleibt, der Abstand im Bereich der Cybersicherheit jedoch drastisch geschrumpft ist. Laut den zitierten Benchmark-Daten hat GLM-5.2 in einigen Sicherheitsbewertungen bereits Claude Opus 4.8 übertroffen.
Der Open-Source-Status von GLM-5.2 ist ein entscheidender Unterschied. Jeder Benutzer kann das Modell herunterladen, modifizieren und auf eigener Hardware ausführen, ohne auf Cloud-Dienstanbieter angewiesen zu sein. Diese Flexibilität ist für Unternehmen attraktiv, wirft jedoch auch Bedenken auf, dass Cyberkriminelle es für Angriffszwecke nutzen könnten.
Diese Entwicklung fällt in eine entscheidende Phase der US-KI-Branche. Während Unternehmen wie Anthropic und OpenAI den Zugang zu den fortschrittlichsten Grenzmodellen aus Gründen der nationalen Sicherheit einschränken, veröffentlichen chinesische KI-Labore zunehmend leistungsstarke Open-Weight-Modelle. Die Debatte über die Geschwindigkeit des chinesischen Aufholprozesses ist öffentlich geworden. Elon Musk hatte zuvor vorhergesagt, dass chinesische KI-Labore bis zum ersten Quartal 2027 zumindest in der Benchmark-Leistung mit Anthropics Flaggschiffmodell Fable 5 gleichziehen würden. Tang Jie, der Gründer von Z.ai, antwortete daraufhin: „So lange wird es nicht dauern.“ Musk stellte später klar, dass China zwar die Benchmark-Leistung erreichen könnte, das Erreichen eines Niveaus „echter Praxistauglichkeit“ jedoch eine schwieriger zu erreichende Leistung sei.
Der Bericht des Wall Street Journal verleiht Tangs Optimismus Gewicht. Der Bericht zeigt, dass GLM-5.2 bei der Erkennung von Sicherheitslücken bereits mit Mythos mithalten kann – eine der wertvollsten realen Anwendungen von KI derzeit. Das Open-Source-Modell GLM-5.2 ermöglicht es Forschern zudem, zusätzliche Prompt-Techniken einzusetzen, um eine mit Mythos vergleichbare Leistung zu erzielen, was darauf hindeutet, dass mit geeigneten Methoden ein an sich „schwächeres“ Modell für bestimmte kritische Aufgaben optimiert werden kann.
Diese Entwicklung hat enorme Auswirkungen auf die Cybersicherheitsbranche. Da Open-Source-KI-Modelle bei der Erkennung von Schwachstellen mit proprietären Modellen gleichziehen, könnte sich die Cyberabwehrlandschaft grundlegend verändern. Während Unternehmen mehr Werkzeuge zur Auswahl haben, sind sie auch größeren Risiken ausgesetzt, da dieselben Werkzeuge von Gegnern genutzt werden könnten. Der Bericht unterstreicht, dass sich der Fokus des KI-Wettbewerbs verschiebt – es geht nicht mehr nur darum, wer das Modell mit der höchsten Benchmark-Leistung hat, sondern darum, wer KI-Fähigkeiten in praktische und hochwertige Lösungen in der realen Welt umsetzen kann. Im Bereich der Cybersicherheit hat China bereits gezeigt, dass es den Abstand schnell verringern kann.
Dieser Artikel wurde von Wedoany übersetzt und bearbeitet. Bei jeglicher Zitierung oder Nutzung durch künstliche Intelligenz (KI) ist die Quellenangabe „Wedoany“ zwingend vorgeschrieben. Sollten Urheberrechtsverletzungen oder andere Probleme vorliegen, bitten wir Sie, uns unverzüglich zu benachrichtigen. Wir werden den entsprechenden Inhalt umgehend anpassen oder löschen.
E-Mail: news@wedoany.com