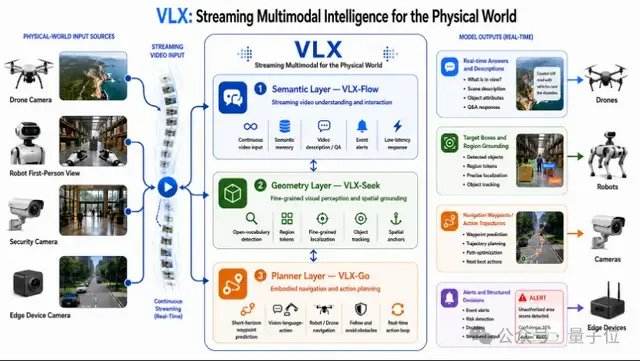
de.wedoany.com-Bericht: Das in Hangzhou ansässige KI-Unternehmen Om AI hat die weltweit erste Serie von endseitigen Streaming-Multimodalmodellen für die physische Welt, VLX, veröffentlicht. Die Serie umfasst drei Modelle, die innerhalb von drei Tagen nacheinander eingeführt werden: VLX-Flow ist für die Echtzeit-Streaming-Wahrnehmung zuständig, sodass Videos wie ein Wasserstrom kontinuierlich eingegeben werden, das Modell in Echtzeit beobachtet, denkt und den Weltzustand aktualisiert; VLX-Seek ist für die präzise Lokalisierung zuständig, vom Sehen zum Erkennen, und lokalisiert Ziele schnell; VLX-Go ist für die Aktionsentscheidung zuständig, übersetzt die Ergebnisse der Wahrnehmung und Lokalisierung in reale Aktionen und legt die Bewegungsrichtung und Operationsschritte fest.
Diese drei Modelle sind miteinander verbunden und bilden einen geschlossenen Kreislauf der Fähigkeiten des Multimodalmodells von kontinuierlicher Wahrnehmung über präzise Lokalisierung bis hin zur Aktionsentscheidung. Das native endseitige Design ermöglicht es dem Modell, tatsächlich auf Endgeräten wie Smartphones, Drohnen und Robotern zu laufen.
Om AI ist nicht zum ersten Mal im Bereich der visuellen Sprache tätig. Im letzten Jahr brachte das Unternehmen VLM-R1 heraus, das weltweit erste Open-Source-Projekt, das das DeepSeek R1 Reinforcement-Learning-Paradigma in visuelle Sprachmodelle einführte. Innerhalb von 12 Stunden nach der Veröffentlichung erhielt es über 2.000 GitHub-Sterne, erreichte innerhalb von 48 Stunden den ersten Platz der globalen GitHub-Trendliste und hat bisher über 6.000 Sterne erhalten.
Die VLX-Serie wurde um zwei Schlüsselbegriffe herum entwickelt: endseitig und Streaming-Multimodal. Streaming-Multimodal bedeutet, dass die KI in der Lage ist, die Umgebung in der physischen Welt kontinuierlich und in Echtzeit wahrzunehmen und eine vollständige Fähigkeitskette von der Wahrnehmung über die präzise Lokalisierung bis hin zur Aktion zu bilden. Dies unterscheidet sich vom Streaming-Multimodal in Sprachassistenten, das die Echtzeit-Interaktion zwischen Mensch und KI betont, während VLX sich darauf konzentriert, dass die KI in der physischen Welt kontinuierlich beobachtet, urteilt und Aktionen antreibt, um den Sprung vom Bildbetrachten zum Handeln zu vollziehen. Mit der rasanten Entwicklung in Bereichen wie verkörperter Intelligenz, räumlicher Intelligenz und Videogenerierung sind visuelle Sprachmodelle nicht mehr nur ein Fähigkeitsmodul von Sprachmodellen, sondern werden allmählich zu einer neuen Generation von Infrastruktur für räumliches Verständnis, Videoverständnis und sogar Aktionsplanung. Die diesjährigen CVPR-Daten zeigen, dass der Anteil der Arbeiten zu visuellen Sprachmodellen und Multimodalität von 4,9 % im letzten Jahr auf 10,6 % gestiegen ist, was es zu einem der am schnellsten wachsenden Forschungsrichtungen der letzten Jahre macht, wobei Echtzeit-Wahrnehmung und -Lokalisierung die beiden am meisten beachteten Schlüsselbegriffe sind.
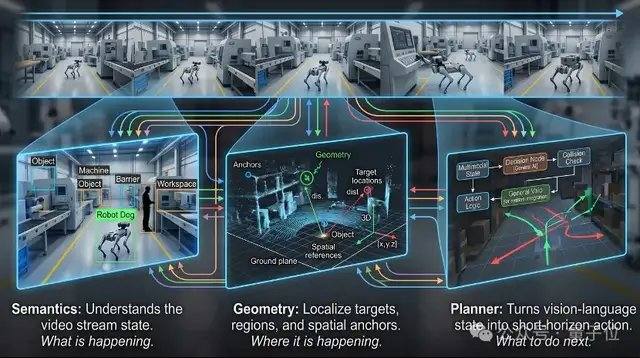
VLX-Flow ist für die kontinuierliche Wahrnehmung zuständig. In der realen Welt befinden sich Objekte ständig in Bewegung, die Umgebung ändert sich ständig, die Perspektiven wechseln häufig, und eine einmalige Beobachtung kann mit einer dynamischen, offenen und sich ständig ändernden Umgebung kaum umgehen. Herkömmliche Videomodelle schneiden oft das gesamte Video in Frames, die dann auf einmal zur Offline-Analyse in das Modell eingespeist werden. Bei langen Videos steigen die Rechenkosten drastisch, und es gehen leicht frühere Informationen verloren. Flow verwendet eine Streaming-Verarbeitung, bei der die Bilder wie ein Wasserstrom kontinuierlich einströmen. Durch inkrementelle Kodierung und Caching-Mechanismen wird der visuelle Zustand ständig aktualisiert, ohne dass die Historie wiederholt neu berechnet werden muss oder das Modell bei längeren Videos sein Gedächtnis verliert. Auf technischer Ebene verwendet Flow Linear Attention anstelle der Standard-Attention und kombiniert dies mit einem zweischichtigen Gedächtnismechanismus, sodass der Videostream kontinuierlich in das Modell eingespeist werden kann, ohne dass der Speicher durch wachsenden Kontext explodiert.

VLX-Seek ist für die feinkörnige Wahrnehmung zuständig. Viele universelle visuelle Sprachmodelle sind zwar gut im Verständnis auf hoher semantischer Ebene, aber bei Aufgaben wie präziser Lokalisierung, Open-Vocabulary-Erkennung und feinkörniger Lokalisierung (Grounding) nur begrenzt leistungsfähig. Herkömmliche Methoden verwenden einen autoregressiven Ansatz, bei dem die Zielposition Koordinate für Koordinate vorhergesagt wird, was langsam und anfällig für Abweichungen ist. Seek ändert diesen Ansatz: Es rät nicht mehr die Koordinaten, sondern generiert zunächst Kandidatenregionen und führt dann eine Suche und einen Abgleich durch, wodurch der Lokalisierungsprozess zu einer Regionsauswahl wird. Konkret verwendet Seek Region Token anstelle der herkömmlichen Koordinatengenerierung, wodurch die Modellgröße und die Kosten für die endseitige Bereitstellung bei gleichbleibender Erkennungsfähigkeit erheblich reduziert werden. Diese Methode entspricht eher der Natur visueller Wahrnehmungsaufgaben, sodass das Modell auch bei kleinerer Größe eine stabile Leistung bei Aufgaben wie Open-Vocabulary-Erkennung, feinkörniger Lokalisierung und Echtzeit-Tracking beibehalten kann.

VLX-Go ist für die Aktion zuständig. Selbst wenn herkömmliche visuelle Sprachmodelle wissen, dass sich das Ziel vorne links befindet, bleiben sie meist im Stadium der Textantwort stecken. Das tatsächliche Hinbewegen, das Umgehen von Hindernissen und das kontinuierliche Verfolgen des Ziels erfordern immer noch ein zusätzliches Steuerungssystem. Go verarbeitet monokulare Videos, historische visuelle Erinnerungen und natürliche Sprachbefehle als Eingabe und wandelt sie direkt in kurzzeitige Wegpunkte um, die von Robotern ausgeführt werden können. Es sagt voraus, wie sich das System in der nahen Zukunft bewegen sollte, anstatt nur Textvorschläge auszugeben. Go kombiniert Offline-Trajektorienlernen und Online-Reinforcement-Learning, um die Bewegungsstrategie in einer simulierten geschlossenen Schleife kontinuierlich zu korrigieren, sodass der Roboter seine Trajektorie basierend auf Echtzeit-Visual-Feedback ständig anpassen und bei Aufgaben wie Zielverfolgung, Navigation und dynamischer Hindernisvermeidung eine stabile Leistung beibehalten kann. Um den Anforderungen der endseitigen Echtzeitsteuerung gerecht zu werden, verwendet Go ein leichtgewichtiges Kurzzeit-Wegpunkt-Vorhersageschema, das mit nur 0,6B Parametern eine Echtzeit-Bewegungsplanung durchführen kann.
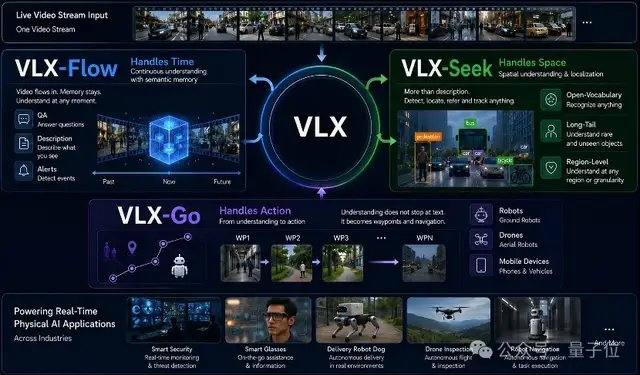
Die drei Modelle Flow, Seek und Go sind nicht unabhängig voneinander, sondern teilen sich dieselbe Basis und arbeiten Ende-zu-Ende an demselben Videostream zusammen. Von der kontinuierlichen Wahrnehmung über die präzise Lokalisierung bis hin zur Aktionsentscheidung bilden sie gemeinsam eine vollständige Fähigkeitskette von VLX für die physische Welt.
Für Geräte der physischen Welt wie Roboter, Drohnen und Kameras ist die endseitige Bereitstellung eine Voraussetzung für die tatsächliche Umsetzung des Modells. Viele Cloud-basierte Multimodelle sind zwar bereits leistungsstark genug, aber nicht von Natur aus für Roboter- und verkörperte Szenarien geeignet, da die reale Welt kontinuierlich, dynamisch und ressourcenbeschränkt ist. Ein gängiger Ansatz in der Branche besteht darin, zunächst ein möglichst großes Modell zu trainieren und es dann durch Quantisierung, Destillation usw. für den endseitigen Betrieb zu komprimieren. VLX hat einen anderen Weg gewählt: Das gesamte System wurde von Anfang an unter Berücksichtigung der Rechenleistungsbeschränkungen des Endgeräts neu entworfen. Die Modellarchitektur, die Inferenzmethode und die Bereitstellungskette sind alle auf Echtzeit-Videostreams und Endgeräte ausgelegt.
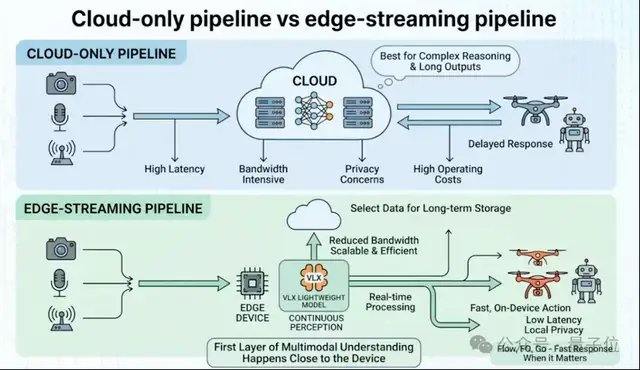
Daten zeigen, dass VLX-Flow die Verarbeitung eines einzelnen Videostreams in nur 0,06 Sekunden benötigt und gleichzeitig mehrere Videostreams stabil verarbeiten kann; VLX-Go erzielt mit etwa einem Zehntel der Parameteranzahl eine bessere Navigationsleistung als größere Modelle; VLX-Seek erreicht oder übertrifft mit einem 3B-Modell bei Aufgaben wie der Objekterkennung die Ergebnisse größerer, universeller Modelle.

Om AI ist ein KI-Unternehmen aus Hangzhou. Der Gründer und CEO Zhao Tiancheng hat einen Doktortitel in Informatik von der CMU und ist Preisträger des Wu-Wenjun-Preises für den Fortschritt in der KI-Technologie. Die Teammitglieder kommen von Institutionen wie CMU, der Tsinghua-Universität, der Zhejiang-Universität, Microsoft und Alibaba Cloud und verfügen über mehr als 50 Top-Konferenzpapiere und über 50 Erfindungspatente. Im Jahr 2022 erhielt Om AI die erste Zertifizierung für Multimodelle vom chinesischen Ministerium für Industrie und Informationstechnologie. Das heute veröffentlichte VLX ist das neueste Ergebnis des Unternehmens mit dem Ziel der kontinuierlichen Wahrnehmung, präzisen Lokalisierung und realen Aktion.

Dieser Artikel wurde von Wedoany übersetzt und bearbeitet. Bei jeglicher Zitierung oder Nutzung durch künstliche Intelligenz (KI) ist die Quellenangabe „Wedoany“ zwingend vorgeschrieben. Sollten Urheberrechtsverletzungen oder andere Probleme vorliegen, bitten wir Sie, uns unverzüglich zu benachrichtigen. Wir werden den entsprechenden Inhalt umgehend anpassen oder löschen.
E-Mail: news@wedoany.com