

de.wedoany.com-Bericht: Ein Forscherteam hat ein Trainingsframework für Quanten-Neuronale Netze entwickelt, das die Kosten für die Berechnung von Gradienten während des Trainings senkt – eines der größten Hindernisse im Bereich des maschinellen Lernens mit Quantencomputern.
Laut einer auf dem Preprint-Server arXiv veröffentlichten Studie reduziert die Methode die Anzahl der benötigten Schaltkreisauswertungen pro Optimierungsschritt von einem quadratischen Wachstum mit der Anzahl der Qubits auf nur noch logarithmisches Wachstum. Die Forscher geben an, dass diese Verbesserung ein direktes gradientenbasiertes Training auf IonQs Forte Enterprise Ionenfallen-Quantencomputer ermöglicht und ihnen erlaubt, die Methode auf eine klinisch relevante Datenimputationsaufgabe anzuwenden.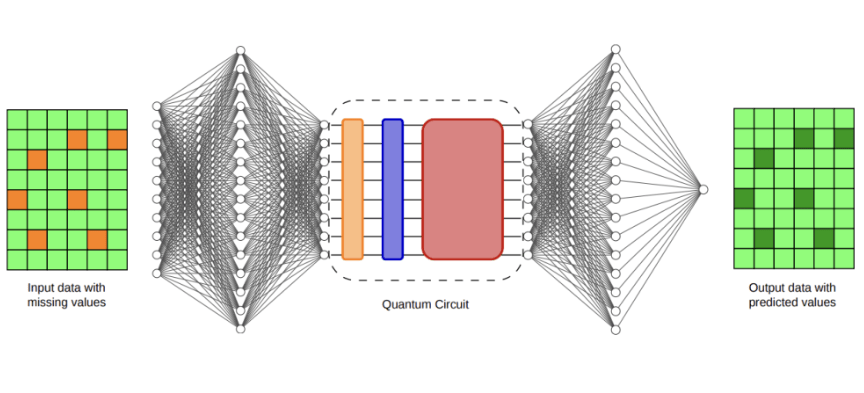
Laut dem Team, dem Wissenschaftler von IonQ, der Université Paris Cité, dem Centre national de la recherche scientifique (CNRS), QC Ware und Quantum Signals angehören, löst diese Arbeit eine seit langem bestehende Herausforderung im Quanten-Maschinenlernen. Quanten-Neuronale Netze (QNN) sind Quantenschaltkreise mit einstellbaren Parametern, die ähnlich wie klassische Neuronale Netze trainiert werden. Theoretisch könnten sie bei bestimmten Lernaufgaben Vorteile bieten, jedoch erwies sich das Training auf echter Quantenhardware als schwierig, da die Berechnung von Gradienten oft das wiederholte Ausführen einer großen Anzahl von Quantenschaltkreisen erfordert. Die Forscher berichten, dass dieser Aufwand einer der Hauptgründe dafür ist, dass viele Demonstrationen des Quanten-Maschinenlernens weiterhin auf Simulationen oder Experimente mit extrem kleiner Hardware beschränkt sind.
Das Framework kombiniert drei aufeinander abgestimmte Komponenten, darunter ein spezielles Schaltkreisdesign, eine schichtweise Trainingsstrategie und eine Technik zur parallelen Gradientenberechnung.
Die traditionelle Parameter-Shift-Methode, die häufig zum Training von Quantenschaltkreisen verwendet wird, erfordert separate Schaltkreisauswertungen für einzelne Parameter. Mit zunehmender Modellgröße steigt die Anzahl der erforderlichen Auswertungen rapide an. Das neue Framework umgeht diesen Engpass durch drei Designentscheidungen. Die erste ist eine Schaltkreisarchitektur namens Butterfly-Netzwerk (Schmetterlingsnetzwerk), inspiriert von der Struktur der schnellen Fouriertransformation, die Quantenoperationen in einem bestimmten Muster anordnet, sodass Informationen im gesamten System verbreitet werden, während der Schaltkreis relativ flach bleibt. Laut der Studie reduziert dieses Design mit zunehmender Systemgröße die Anzahl der benötigten trainierbaren Parameter erheblich. Die zweite ist eine schichtweise Trainingsstrategie, bei der nicht alle Parameter des Quanten-Neuronalen Netzes gleichzeitig trainiert werden, sondern zunächst kleinere Schaltkreisblöcke trainiert und dann schrittweise neue Schichten hinzugefügt werden, wobei die zuvor trainierten Schichten beim Optimieren der neuen Schicht eingefroren werden. Die dritte ist eine parallelisierte Version der Parameter-Shift-Regel. Da die Gatter innerhalb jeder Butterfly-Schicht auf unterschiedliche Qubit-Paare wirken und miteinander kommutieren, können die Forscher die Gradienten für die gesamte Schicht mit einer konstanten Anzahl von Schaltkreisausführungen berechnen, anstatt jeden Parameter einzeln zu bewerten. Diese Techniken reduzieren gemeinsam die Anzahl der während des Trainings benötigten Quantenschaltkreisauswertungen drastisch. Die Forscher berichten anhand eines Beispiels von einem Skalierungsvorteil: Die Anwendung der traditionellen Parameter-Shift-Methode auf einen 128-Qubit-Butterfly-Schaltkreis würde 1792 Schaltkreisauswertungen zur Berechnung des Gradienten erfordern, während ihre Methode nur 28 benötigt.
Zur Bewertung des Frameworks wählten die Forscher die klinische Datenimputation, ein Problem, das über traditionelle Quantencomputing-Benchmarks hinausgeht. Datenimputation beinhaltet das Auffüllen fehlender Einträge in Datensätzen. In medizinischen Aufzeichnungen sind fehlende Informationen aufgrund inkonsistenter Messzeitpläne, Sensorausfällen oder unvollständiger Datenerfassung häufig, und eine genaue Imputation kann nachgelagerte Vorhersagemodelle, die in der medizinischen Analyse verwendet werden, erheblich beeinflussen. Das Team verwendete den MIMIC-III-Datensatz, eine umfassend erforschte Sammlung anonymisierter Intensivstationsaufzeichnungen. Sie führten fehlende Werte in den Datensatz ein und verglichen dann verschiedene Methoden zur Rekonstruktion der fehlenden Informationen. Zu den Basislinien gehörten gängige statistische Techniken wie Mittelwertimputation und Nullauffüllung sowie komplexere Methoden wie K-Nächste-Nachbarn-Imputation, Multiple Imputation by Chained Equations (MICE), MissForest und das auf neuronalen Netzen basierende Deep MICE-Modell. Die Forscher bewerteten die Imputationsqualität indirekt, indem sie die Überlebenswahrscheinlichkeit von Patienten vorhersagten, und maßen diese anhand der Fläche unter der Receiver-Operating-Characteristic-Kurve (AUC). Unter den klassischen Methoden erzielte Deep MICE die stärkste durchschnittliche Leistung mit einer AUC von 0,7176. Ein auf 16 Qubits trainiertes hybrides Quanten-Klassik-Modell erreichte eine AUC von 0,7147, während ein 32-Qubit-Hybridmodell eine AUC von 0,7132 erreichte – beide lagen weniger als einige Tausendstel von den führenden klassischen Ergebnissen entfernt. Obwohl die Quantenmodelle die beste klassische Basislinie nicht übertrafen, wiesen sie eine enge Leistungsspanne und eine geringere Variabilität über mehrere Durchläufe auf. Die Forscher geben an, dass diese Stabilität auf einen vorteilhaften induktiven Bias hindeuten könnte, der durch die strukturierte Butterfly-Architektur und das Trainingsprotokoll verursacht wird.
Die Studie liefert eine wichtige Demonstration des direkten Trainings auf einem kommerziellen Quantencomputer. Die Forscher trainierten die letzte Schicht eines 16-Qubit-Butterfly-Quanten-Neuronalen Netzes auf IonQs Forte Enterprise Ionenfallen-System. Die frühen Phasen des Modells wurden in der Simulation trainiert und dann in das auf der Hardware trainierte Netzwerk integriert. Sie verglichen drei Szenarien: ideale Simulation, verrauschte Simulation und direkte Hardwareausführung. Den Ergebnissen zufolge waren die Leistungsunterschiede zwischen den drei Trainingsmethoden statistisch nicht signifikant; das auf der Hardware trainierte Modell erzielte mit den Simulationsmodellen vergleichbare Ergebnisse bei gleichbleibender Vorhersageleistung. Die Forscher berichten, dass dies beweise, dass das logarithmisch skalierende Trainingsframework robust genug sei, um unter dem aktuellen Hardware-Rauschniveau zu funktionieren. Diese Erkenntnis ist wichtig, da viele frühere Demonstrationen des Quanten-Maschinenlernens stark auf Simulationen anstatt auf echte Quantenprozessoren angewiesen waren; Hardware-Rauschen und lange Trainingszeiten machten eine direkte Optimierung oft unpraktisch. Die von IonQ verwendete Ionenfallen-Architektur könnte hilfreich sein, da das System vollständig verbundene Qubit-Verbindungen bietet, was die Implementierung von Butterfly-Schaltkreisen ohne großen Kompilierungsaufwand ermöglicht.
Die Studie untersuchte auch größere Systemgrößen. Da ein direktes 32-Qubit-Training weiterhin rechenintensiv ist, verwendeten die Forscher Matrix-Produkt-Zustands-Tensornetzwerk-Simulationen, um größere Quantenschichten zu trainieren, während die Inferenz auf der IonQ-Hardware durchgeführt wurde. Die Leistung des resultierenden 32-Qubit-Hybridmodells war vergleichbar mit der eines klassischen neuronalen Netzes mit äquivalenter versteckter Schichtbreite. Die Forscher interpretieren dies als Beleg dafür, dass die durch das schichtweise Framework erzeugten größeren Quantenschaltkreise weiterhin mit echter Hardware kompatibel sind und ohne messbare Verschlechterung betrieben werden können.
Die Arbeit weist mehrere wichtige Einschränkungen auf. Die Studie konzentrierte sich auf eine kontrollierte Proof-of-Concept-Imputationsaufgabe und nicht auf einen produktionsreifen medizinischen Workflow; nur eine Merkmalsspalte wurde mit dem Quantenmodell imputiert, die restlichen fehlenden Werte wurden mit klassischen Methoden behandelt. Das Fehlendatenmuster wurde auch unter Verwendung eines vollständig zufälligen Fehlendatenmodells generiert, während reale klinische Daten typischerweise komplexere Fehlmuster aufweisen. Schließlich erreichte das Hybridmodell die stärkste klassische Basislinie, übertraf sie jedoch nicht; die Ergebnisse zeigen Machbarkeit und Wettbewerbsfähigkeit, aber keinen eindeutigen Quantenvorteil. Die Forscher weisen auch darauf hin, dass möglicherweise größere Systeme erforderlich sind, bevor potenzielle Leistungsvorteile deutlich werden. Basierend auf Vergleichen mit klassischen neuronalen Netzarchitekturen schätzen sie, dass etwa 128 Qubits benötigt werden, um die Repräsentationsfähigkeit des in der Studie verwendeten stärksten klassischen Modells zu erreichen. Dennoch, so die Forscher, liege die Bedeutung des Frameworks nicht in den aktuellen Leistungszahlen, sondern in der Ermöglichung eines skalierbaren Trainings auf Hardware.
Zum Forschungsteam gehören Natansh Mathur vom Institut de Recherche en Informatique Fondamentale (IRIF), einem gemeinsamen Forschungslabor des CNRS und der Université Paris Cité, sowie QC Ware France. Die Co-Autoren Panagiotis Kl. Barkoutsos, Masako Yamada und Martin Roetteler sind bei IonQ tätig. Die Forschung umfasst auch Iordanis Kerenidis, der dem IRIF, dem CNRS, der Université Paris Cité und Quantum Signals angehört.
Dieser Artikel wurde von Wedoany übersetzt und bearbeitet. Bei jeglicher Zitierung oder Nutzung durch künstliche Intelligenz (KI) ist die Quellenangabe „Wedoany“ zwingend vorgeschrieben. Sollten Urheberrechtsverletzungen oder andere Probleme vorliegen, bitten wir Sie, uns unverzüglich zu benachrichtigen. Wir werden den entsprechenden Inhalt umgehend anpassen oder löschen.
E-Mail: news@wedoany.com















