
de.wedoany.com-Bericht: Das Hochgeschwindigkeits-Audiomodell AudioX-Turbo wurde veröffentlicht: In 4 Schritten und 0,24 Sekunden werden 10 Sekunden Audio generiert. Entwickelt von Noiz AI in Zusammenarbeit mit der Hong Kong University of Science and Technology und der Tsinghua-Universität unterstützt das Modell multimodale Eingaben wie Text, Video und Bilder. Durch Distribution Matching Distillation und Adversarial Distillation wird der Generierungsprozess herkömmlicher Diffusionsmodelle von 50 bis 200 Schritten auf 4 Schritte komprimiert, wodurch die Anzahl der Vorwärtsdurchläufe um etwa das 25-fache reduziert wird. Auf einer einzelnen RTX 4090-Grafikkarte dauert die Generierung von 10 Sekunden Audio nur 0,24 Sekunden, der Echtzeitfaktor beträgt lediglich 0,02, was neue Möglichkeiten für Echtzeit-Audiointeraktionen eröffnet.
Aktuelle gängige Audiomodelle wie MMAudio und Stable Audio Open basieren auf Diffusions- oder Flow-Matching-Techniken und benötigen in der Regel Dutzende bis Hunderte von Iterationen. AudioX-Turbo verwendet den nativ multimodalen Multimodal Diffusion Transformer (MMDiT) als Grundgerüst und trainiert in Kombination mit dem MAF-Modul von Grund auf 2,7 Milliarden Parameter. Im Flow-Matching-Framework führten die Forscher Distribution Matching Distillation (DMD) und Adversarial Distillation ein, um das Modell auf 4 Schritte zu komprimieren, während durch CFG-Destillation zusätzliche NFE-Kosten vermieden wurden. Dank des Diffusionsdiskriminators übertrifft das Studentenmodell in einigen Leistungsindikatoren sogar das 100-Schritte-Lehrermodell.
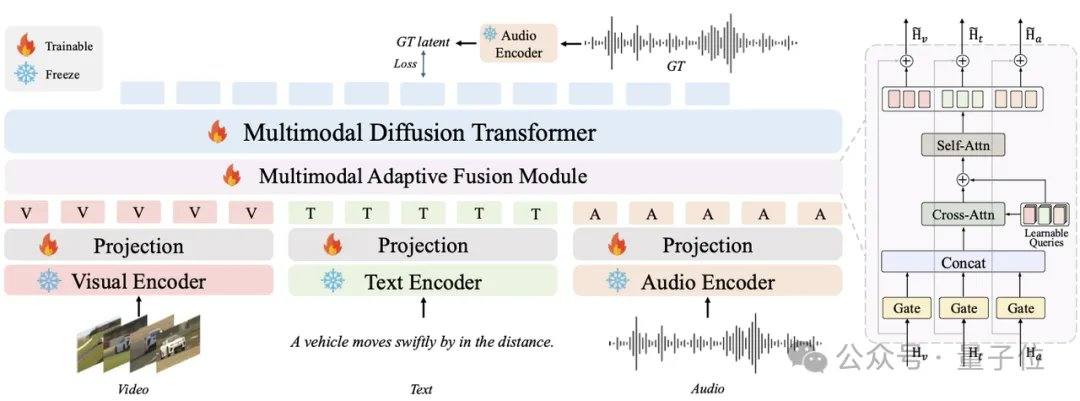
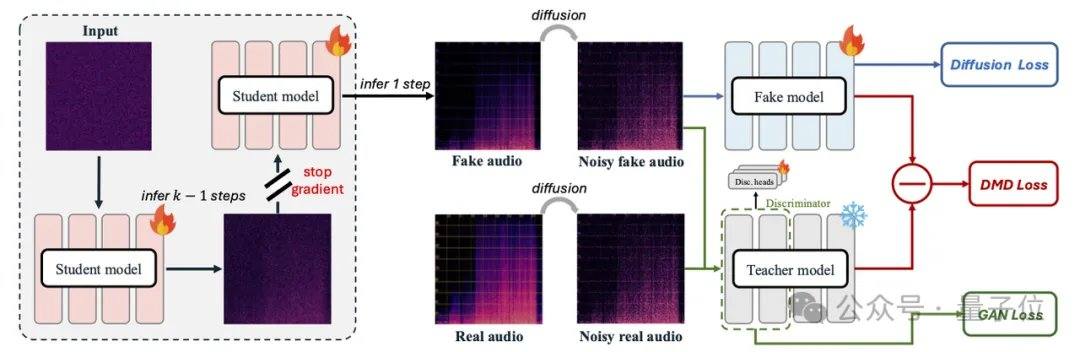
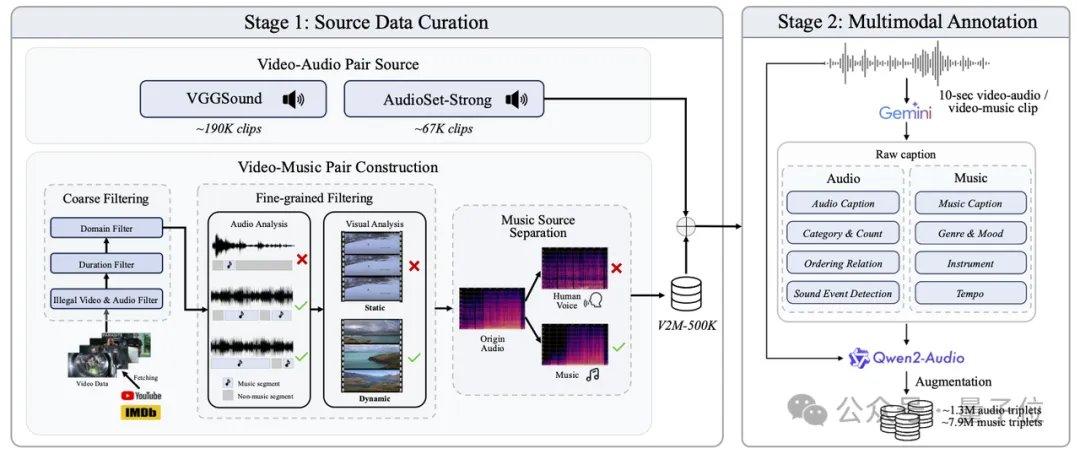
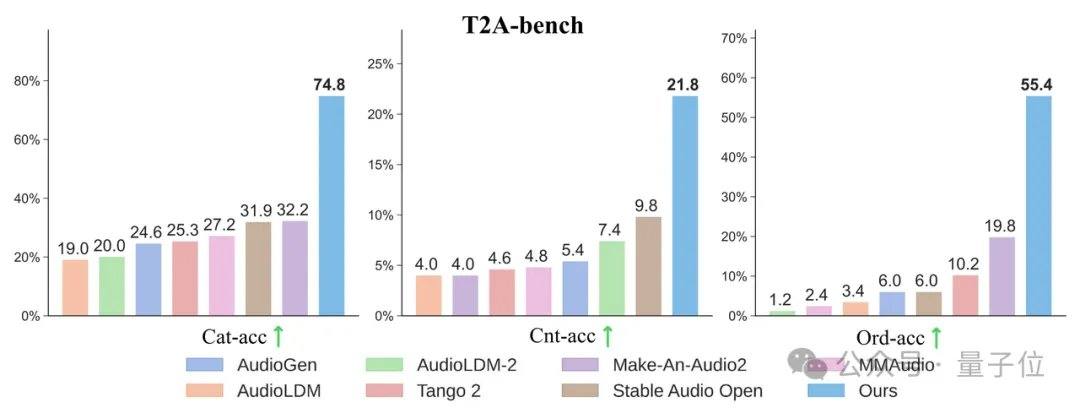
AudioX-Turbo löst auch das Problem der präzisen Steuerung von Audiomodellen. Die Forscher wiesen darauf hin, dass viele frühere Modelle keine genauen Zeitstempel steuern konnten, da die Textbeschriftungen in den Trainingsdaten zu vage waren. Aus diesem Grund haben Noiz AI und das Team der HKUST speziell den groß angelegten multimodalen Audiodatensatz IF-caps-Pro mit insgesamt etwa 9,2 Millionen Einträgen erstellt. Das Team verwendete ein „kaskadiertes Large-Model-Annotationsschema": Zunächst wurden massenhaft hochwertige Video-Audio-Paare erstellt, dann mit dem Gemini 2.5 Pro-Modell strukturierte Vorlagen mit Zeitstempeln, Instrumenten und Ereignisanzahlen generiert und schließlich mit Qwen2-Audio in großem Maßstab erweitert, wodurch die Daten von „vagen Zusammenfassungen" zu „Drehbüchern mit präzisen Zeitachsen" wurden.
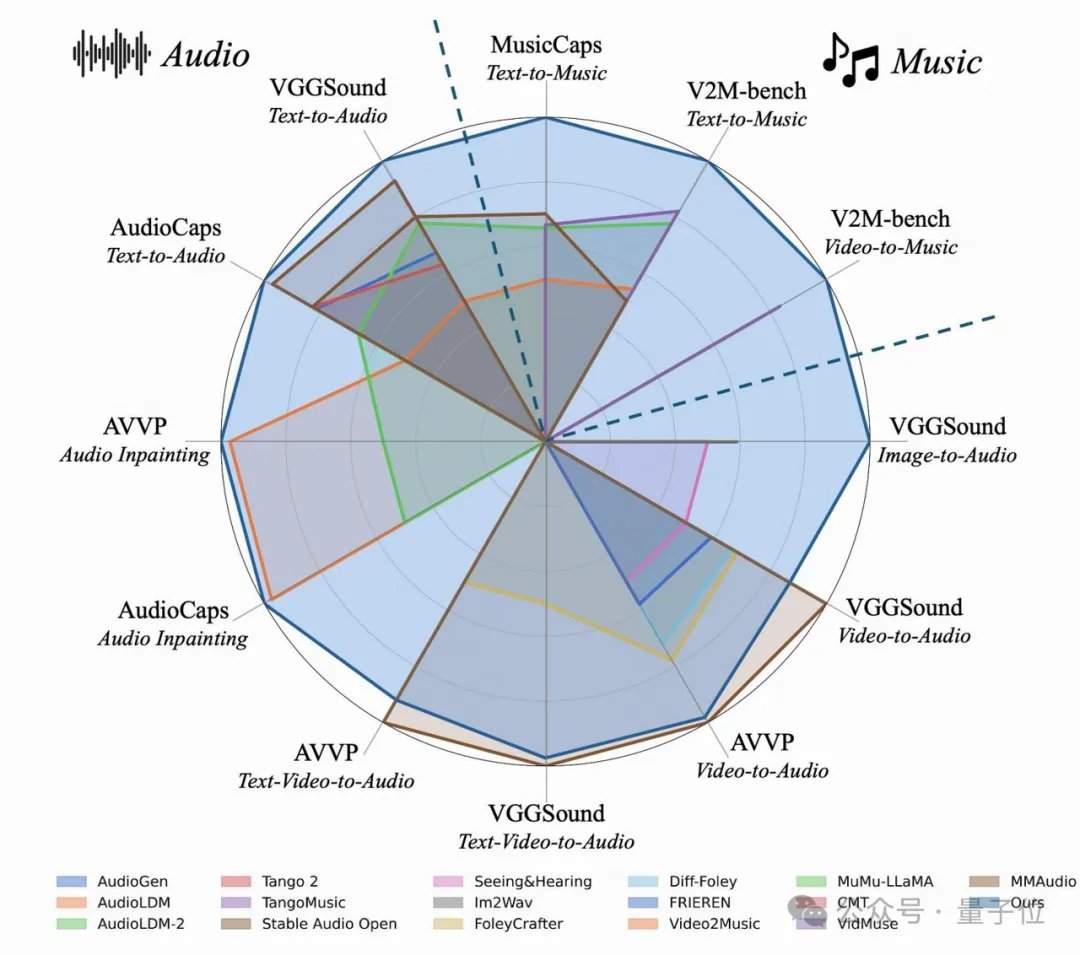
Die Forscher entdeckten überraschend, dass detailliertere Textbeschriftungen nicht nur die Text-zu-Audio-Generierung verbesserten, sondern auch die Ausrichtung bei der „stummen Videovertonung" deutlich steigerten. In den klassischen Testdatensätzen wie AudioCaps und MusicCaps besiegte oder erreichte das 4-Schritte-AudioX-Turbo-Modell in den wichtigsten Audioqualitätsindikatoren viele Basismodelle, die 50 bis 200 Schritte benötigen. Zur Bewertung der Befehlsbefolgungsfähigkeit erstellte das Team einen speziellen Benchmark namens T2A-bench. In den Tests zu Audiokategorien, -anzahl, -zeitstempeln und -reihenfolge übertraf AudioX-Turbo andere Basislinienmethoden deutlich, wobei einige Indikatoren im Vergleich zur Basislinie um mehr als das Doppelte verbessert wurden.
Die drei Hauptmerkmale von AudioX-Turbo sind: 4-Schritt-Inferenz mit 25-fach reduziertem Rechenaufwand im Vergleich zum Lehrermodell, bessere Ergebnisse und einem RTF von nur 0,02; ein 9,2-Millionen-starker Befehlsdatensatz, der erstmals eine präzise Zeitstempelsteuerung ermöglicht; Unterstützung multimodaler Eingaben wie Text, Video und Bilder für die Anything-to-Audio-Generierung. Der gesamte Trainingscode und die Modellgewichte des Projekts wurden als Open Source veröffentlicht. Das Paper trägt den Titel „AudioX-Turbo: A Unified Framework for Efficient Anything-to-Audio Generation" und wurde vom Team von Noiz AI, der Hong Kong University of Science and Technology und der Tsinghua-Universität erstellt. Die Projektseite ist https://zeyuet.github.io/AudioX-Turbo/.
Dieser Artikel wurde von Wedoany übersetzt und bearbeitet. Bei jeglicher Zitierung oder Nutzung durch künstliche Intelligenz (KI) ist die Quellenangabe „Wedoany“ zwingend vorgeschrieben. Sollten Urheberrechtsverletzungen oder andere Probleme vorliegen, bitten wir Sie, uns unverzüglich zu benachrichtigen. Wir werden den entsprechenden Inhalt umgehend anpassen oder löschen.
E-Mail: news@wedoany.com









