de.wedoany.com-Bericht: Ein neunköpfiges Forschungsteam von Sina Weibo hat VibeThinker-3B vorgestellt, ein kompaktes Sprachmodell mit 3 Milliarden Parametern, das in mehreren Denk-Benchmarks mit größeren Systemen von Organisationen wie Google DeepMind, Open Artificial Intelligence (OpenAI), dem KI-Sicherheitsunternehmen Anthropic und DeepSeek mithalten oder diese sogar übertreffen kann.
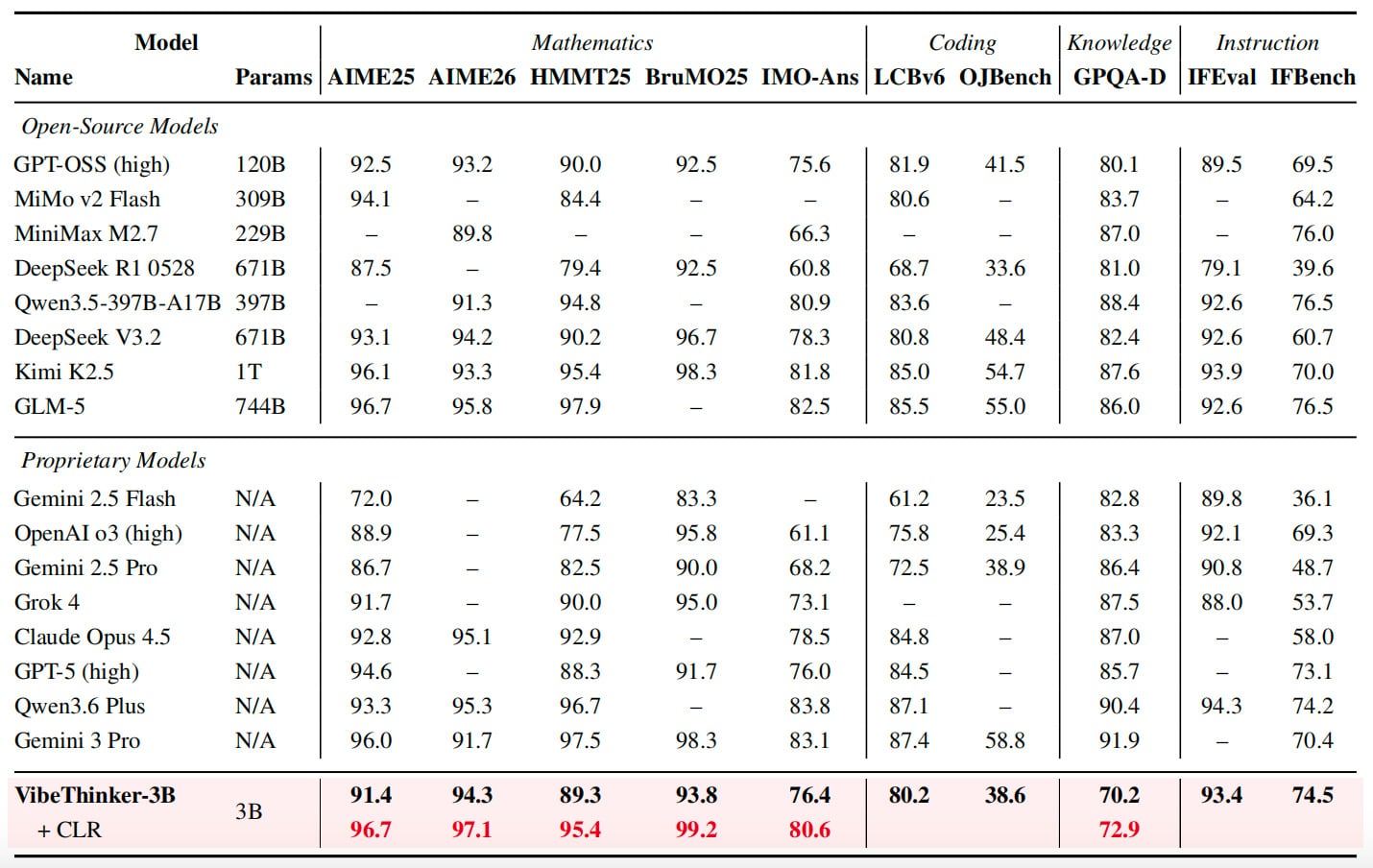
Das Modell erreichte bei AIME 2026 94,3 Punkte, was der Leistungsspanne von DeepSeek V3.2 mit 671 Milliarden Parametern entspricht, und schlug Gemini 3 Pro mit 91,7 Punkten. Durch eine Testzeit-Erweiterungsmethode namens „Claim-Level Reliability Assessment“ (Bewertung der Zuverlässigkeit auf Aussagenebene) steigerte VibeThinker-3B seine Punktzahl bei AIME 2026 weiter auf 97,1.
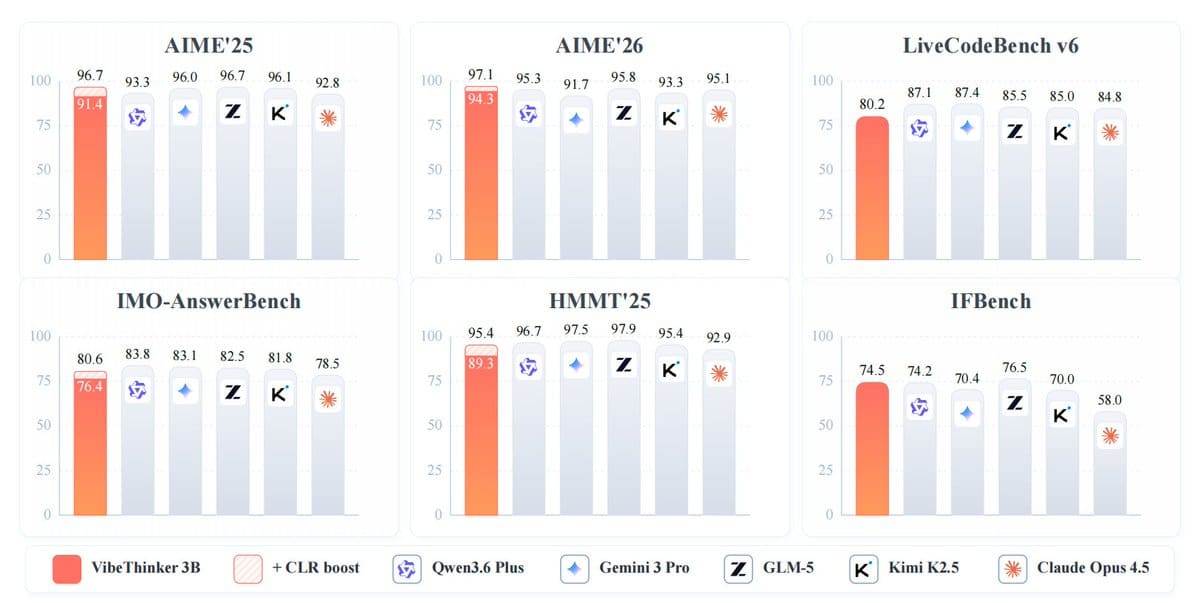
Bei anderen Benchmarks erzielte VibeThinker-3B bei AIME 2025 91,4 Punkte, bei HMMT 2025 89,3 Punkte, bei BruMO 2025 93,8 Punkte und bei IMO-AnswerBench 76,4 Punkte. In Bezug auf die Programmierfähigkeit erreichte das Modell einen Pass@1-Wert von 80,2 bei LiveCodeBench v6 und eine Akzeptanzrate von 96,1 % bei zuvor nicht gesehenen LeetCode-Wochen- und Doppelwochenwettbewerben, die von Ende April bis Ende Mai 2026 stattfanden. Beim Instruktionsbefolgungs-Test IFEval erzielte es 93,4 Punkte.
Das Modell bestand 123 von 128 erstmalig eingereichten LeetCode-Aufgaben und übertraf damit unter denselben Bewertungsbedingungen GPT-5.2, Doubao Seed 2.0 Pro, Kimi K2.5 und Claude Opus 4.6.
Die Parameteranzahl von VibeThinker-3B beträgt etwa 1/224 der von DeepSeek V3.2. Im Vergleich dazu hat GLM-5 744 Milliarden Parameter, während Kimi K2.5 über eine Billion Parameter verfügt. Das Modell ist kompakt genug, um auf einem handelsüblichen Laptop ausgeführt zu werden. Das Forschungsteam ist der Ansicht, dass überprüfbare Denkaufgaben (wie Mathematik und Programmieren) effizienter in kleinere Modelle komprimiert werden können als breites Faktenwissen, und bezeichnet dies als die „Parameter-Kompressions-Abdeckungs-Hypothese“.
Das Modell schneidet nicht in allen Bereichen hervorragend ab. Im GPQA-Diamond-Test erreichte es 70,2 Punkte, während Gemini 3 Pro 91,9 und Claude Opus 4.5 87,0 Punkte erzielten. Das Forschungsteam gibt an, dass dies ihre These stützt, dass kompakte Modelle bei überprüfbaren Denkaufgaben stark abschneiden können, aber größere Modelle mit breiterer Wissensabdeckung nicht ersetzen können.
VibeThinker-3B basiert auf Qwen2.5-Coder-3B von Alibaba und wurde durch einen vierstufigen Post-Training-Prozess verbessert. Die erste Stufe verwendet überwachte Feinabstimmung mit Daten für Mathematik, Programmieren, MINT-Denken, Dialoge und Instruktionsbefolgung, gefolgt von schwierigeren und längeren Denkproblemen. Trainingsbeispiele mit Denkspuren von weniger als 5000 Token wurden entfernt, ebenso wie solche, die von der früheren Version VibeThinker-1.5B mit einer Erfolgsquote von über 75 % gelöst werden konnten. Die zweite Stufe nutzt verstärkendes Lernen bei Mathematik-, Programmier- und MINT-Aufgaben mittels MaxEnt-Guided Policy Optimization. Die Forscher verwendeten ein einzelnes Fenster von 64.000 Token anstelle einer schrittweisen Erweiterung des Kontextfensters, da die schrittweise Erweiterung die Leistung bei der 3B-Größe verringerte. Eine separate „Long2Short Math RL“-Phase belohnt kürzere korrekte Antworten, um unnötige Weitschweifigkeit zu reduzieren. Die dritte Stufe destilliert erfolgreiche Denkspuren aus den Checkpoints des verstärkenden Lernens zurück in ein einheitliches Modell. Die letzte Stufe wendet verstärkendes Lernen auf Instruktionsbefolgungsaufgaben an, wobei regelbasierte Überprüfungen und Belohnungsmodelle zum Einsatz kommen.
Die Testergebnisse haben Aufmerksamkeit erregt, aber auch Bedenken hinsichtlich einer möglichen Überoptimierung des Modells auf die Benchmarks aufgeworfen. Einige Benutzer berichteten, dass das Modell bei praktischen Programmierproblemen schwächer abschneidet, einschließlich Schwierigkeiten mit gängigen Entwicklungswerkzeugen. Andere fragten, warum das Modell nicht an umfassenderen Softwareentwicklungs-Benchmarks getestet wurde. Die Forscher gaben an, dass die Trainingsdaten einer strengen Benchmark-Dekontamination unterzogen wurden, einschließlich der Filterung überlappender Texte. Die jüngsten LeetCode-Wettbewerbe bieten einen stärkeren Schutz vor Datenlecks, da sie nach jedem möglichen Trainingsstichtag stattfanden. Dennoch deuten Benutzerberichte auf eine Diskrepanz zwischen Benchmark-Ergebnissen und tatsächlicher Leistung hin.
Das Modell wurde unter der MIT-Lizenz veröffentlicht, und seine Gewichte sind über Hugging Face und ModelScope verfügbar. Innerhalb des ersten Tages nach der Veröffentlichung hatten Entwickler bereits GGUF-Quantisierungsversionen und abgeleitete Modelle erstellt.
Sina Weibo ist eher für seine Social-Media-Plattform als für Spitzenforschung im Bereich KI bekannt. VibeThinker-3B ist die zweite große Open-Source-KI-Veröffentlichung des Unternehmens innerhalb von sieben Monaten. Das im November 2025 veröffentlichte VibeThinker-1.5B soll in mehreren Mathematik-Benchmarks das ursprüngliche DeepSeek R1 geschlagen haben. Das Team gab an, dass die Kosten für das Post-Training bei 7.800 US-Dollar lagen, während die geschätzten Kosten für DeepSeek R1 bei 294.000 US-Dollar lagen.
Die Forscher behaupten nicht, dass VibeThinker-3B große universelle Modelle ersetzen kann. Sie sind der Ansicht, dass in hybriden KI-Systemen kleine Modelle Denkaufgaben übernehmen können, während große Systeme Faktenwissen liefern. Dieser Ansatz könnte die Kosten für den Einsatz fortschrittlicher Denkfähigkeiten senken und leistungsstarke Mathematik- und Programmierfähigkeiten auf Geräten mit begrenzter Hardware bieten. Die entscheidende Frage ist, ob sich die Benchmark-Leistung des Modells in zuverlässige reale Anwendungen übertragen lässt.
Dieser Artikel wurde von Wedoany übersetzt und bearbeitet. Bei jeglicher Zitierung oder Nutzung durch künstliche Intelligenz (KI) ist die Quellenangabe „Wedoany“ zwingend vorgeschrieben. Sollten Urheberrechtsverletzungen oder andere Probleme vorliegen, bitten wir Sie, uns unverzüglich zu benachrichtigen. Wir werden den entsprechenden Inhalt umgehend anpassen oder löschen.
E-Mail: news@wedoany.com