
de.wedoany.com-Bericht: Das Qwen-Team von Alibaba hat Qwen-AgentWorld veröffentlicht, das zwei Modelle umfasst. Diese sind nicht dazu gedacht, Aktionen in einer Agentenumgebung auszuführen, sondern die Ergebnisse vorherzusagen, die diese Umgebungen zurückgeben. Sie decken sieben Bereiche ab: MCP, Suche, Terminal, Softwareentwicklung, Android, Web und Betriebssysteme.
Diese Veröffentlichung setzt Alibabas jüngste Investitionen in autonome Agenten fort. Das im Mai veröffentlichte Qwen3.7-Max wurde um eine 35-stündige autonome Ausführungsfähigkeit herum aufgebaut. Das Team weist darauf hin, dass der zentrale Engpass beim Training von Agenten in großem Maßstab in den Einschränkungen des Trainings in realen Umgebungen liegt: Suchmaschinen können keine kontrollierten Bedingungen injizieren, Echtzeit-Terminals erlauben keine bedarfsgerechte Simulation von Randfällen wie niedrigem Speicherplatz, und Agenten können systematisch nicht seltenen Szenarien ausgesetzt werden.
Das Forschungsteam trainierte Agenten in generierten Simulatoren und stellte fest, dass ihre Leistung diejenige übertraf, die ausschließlich auf Training in realen Umgebungen basierte. In einem weiteren Test wurde das Training eines Weltmodells als Aufwärmschritt vor der Feinabstimmung des Agenten eingesetzt, was die Leistung in allen sieben Benchmarks verbesserte, von denen drei im Training noch nie gesehen wurden. Die begleitende Veröffentlichung weist darauf hin, dass die Weltmodellierung ein entscheidender Schritt zur Erreichung eines universellen Agenten ist.
Im Gegensatz zu traditionellen Agentenmodellen, die die Aktionsauswahl optimieren, wird Qwen-AgentWorld darauf trainiert, die umgekehrte Frage zu beantworten: Was wird die Umgebung als Nächstes anzeigen, nachdem der Agent eine bestimmte Aktion ausgeführt hat? Die Veröffentlichung bezeichnet diese Methode als „Sprachweltmodell". Das Modell lernt unter einem einzigen Trainingsziel, den nächsten Umgebungszustand in allen sieben Bereichen vorherzusagen. Frühere verwandte Forschungen waren enger gefasst, wie z. B. das von Qwen im Februar veröffentlichte WebWorld, das nur die Webumgebung abdeckte; das von Snowflake im selben Monat veröffentlichte Agent World Model generierte einen codegesteuerten SQL-Support, anstatt das Modell zu trainieren, Zustände vorherzusagen. Qwen-AgentWorld ist das erste Modell, das sieben Bereiche in einem einzigen Modell abdeckt und die Umgebungsmodellierung bereits in der frühesten Vortrainingsphase integriert.
Der Trainingsprozess verwendete über zehn Millionen Umgebungsinteraktionsspuren von echten Agentenläufen und war in drei Phasen unterteilt: Die erste Phase lehrte das Modell die Funktionsweise der Umgebung, einschließlich Dateisystemen, Terminalzuständen, Browser-DOM-Änderungen und API-Antworten; die zweite Phase trainierte das Modell, zuerst über den Folgezustand nachzudenken und dann eine Vorhersage zu treffen; die dritte Phase verschärfte die Vorhersagen durch verstärkendes Lernen unter Verwendung von regelbasierten Überprüfungen und offenen Qualitätsbewertungen. Beide Modelle verwenden ein Mixture-of-Experts-Design, bei dem pro Token nur ein kleiner Teil der Parameter aktiviert wird. Das 35B-Modell aktiviert 3B, das 397B-Modell aktiviert 17B; beide unterstützen ein 256K-Kontextfenster. Für die GUI-Bereiche (Android, Web und Betriebssysteme) arbeiten die Modelle mit Textzugänglichkeitsbäumen und UI-Ansichtshierarchien, nicht mit Screenshots. Die Gewichte des 35B-Modells und AgentWorldBench sind unter der Apache 2.0-Lizenz verfügbar; die 397B-Gewichte wurden noch nicht öffentlich freigegeben.
Die Benchmark-Ergebnisse zeigen die Genauigkeit der Modelle bei der Vorhersage des von der Umgebung zurückgegebenen Inhalts, aber die Trainingsergebnisse offenbaren den tatsächlichen Wert dieser Vorhersagefähigkeit für den Aufbau von Agententeams – diese Zahlen sind wichtiger. Laut den Forschern übertrafen die in kontrollierten Simulationen trainierten Agenten die in realen Umgebungen trainierten. Die Injektion von gezielten Störungen verbesserte MCPMark von 24,6 auf 33,8. Bei Suchaufgaben übertrug sich das Training in einer vollständig fiktiven Welt auf reale Suchaufgaben und verbesserte den WideSearch F1 Item auf dem Open-Source-35B-Modell von 34,02 auf 50,31. Die Aufwärmtests zeigten, dass das Vortraining des Weltmodells BFCL v4 von 62,29 auf 71,25 und Claw-Eval von 53,60 auf 64,88 verbesserte, ohne dass eine agentspezifische Feinabstimmung erforderlich war.
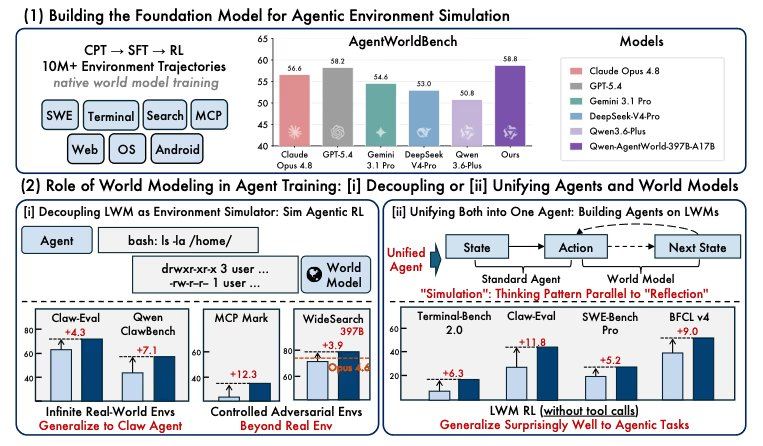
Nach der Veröffentlichung des Papers löste es Diskussionen unter KI-Forschern aus. Einige meinen, Qwen habe das Kernproblem umgekehrt, indem es das Modell trainiere, die Umgebung selbst vorherzusagen; dieses Vorhersagewissen werde dann auf Agentenaufgaben übertragen, selbst ohne agentspezifische Feinabstimmung. Andere Forscher wiesen darauf hin, dass AgentWorldBench ein von Alibaba im selben Paper erstellter und veröffentlichter Benchmark sei, bei dem das Modell mit einem Vorsprung von 0,46 gewonnen habe, was eine Überprüfung der Unabhängigkeit der Bewertungsstandards auslösen könnte. Das traditionelle Problem von simulierten RL-Methoden ist, dass Agenten dazu neigen, die Eigenschaften des Simulators zu überanpassen; wenn das Weltmodell zu sauber ist, lernt der Agent das Modell und nicht die Aufgabe. Die im Paper vorgenommenen Auslassungen und die Datenresultate gehen teilweise auf diese Bedenken ein; die Ergebnisse der Suche in fiktiven Welten zeigen, dass in diesen Umgebungen trainierte Agenten auf reale Suchaufgaben übertragen werden können.
Für Teams, die Agenten-Pipelines aufbauen und skalieren, bietet diese Arbeit eine dritte Option: kontrollierte Simulationen, die Randfälle injizieren, die in der Produktionsumgebung nicht auftreten. Synthetische Umgebungen sind eine legitime Trainingsschicht, eine Ergänzung zum RL in realen Umgebungen, kein Weg, es zu umgehen. Die Umgebungsfundamentierung vor dem Agententraining wirkt früher im Entwicklungsprozess als die meisten aktuellen Praktiken und kann die Leistung in mehreren Benchmarks verbessern, ohne dass agentspezifisches Training erforderlich ist. Was ein Modell vor dem Training lernt, ist viel wichtiger, als die meisten Pipelines berücksichtigen.
Dieser Artikel wurde von Wedoany übersetzt und bearbeitet. Bei jeglicher Zitierung oder Nutzung durch künstliche Intelligenz (KI) ist die Quellenangabe „Wedoany“ zwingend vorgeschrieben. Sollten Urheberrechtsverletzungen oder andere Probleme vorliegen, bitten wir Sie, uns unverzüglich zu benachrichtigen. Wir werden den entsprechenden Inhalt umgehend anpassen oder löschen.
E-Mail: news@wedoany.com










