de.wedoany.com-Bericht: Der NVIDIA-Inferenzsoftware-Stack hat auf seiner Blackwell-Plattform die Kosten pro Token des DeepSeek V4-Modells innerhalb eines Monats um bis zu 80 % gesenkt. Während Unternehmen von KI-Pilotprojekten zu produktiven KI-Fabriken übergehen, haben sich Infrastrukturentscheidungen von der reinen Chip-Leistung hin zu den Kosten pro Token verlagert – also wie viele nützliche Token pro Dollar und pro Watt Strom bei Einhaltung der Latenzziele erzeugt werden. Der NVIDIA-Inferenzsoftware-Stack ist mit NVIDIA GPUs, CPUs, Netzwerken und Systemen co-entwickelt und wird durch ein breites Open-Source-Ökosystem verstärkt, um die Hardwareleistung kontinuierlich zu steigern.
Führende Unternehmen und Inferenzanbieter haben bereits den Mehrwert des NVIDIA-Inferenzsoftware-Stacks auf Blackwell erlebt. Baseten nutzt die Open-Source-Bibliothek NVIDIA TensorRT-LLM auf Blackwell GPUs, um DeepSeek V4 Pro für Inferenz-, Codierungs- und Langkontext-Workloads bereitzustellen. Durch proprietäre Laufzeitoptimierungen wird der Token-Ausstoß pro Sekunde um bis zu 50 % gesteigert. Cognition verwendet das NVIDIA Dynamo-Inferenzframework zur Verwaltung von Inferenz-GPUs und bietet seinem Team einen sofort einsatzbereiten Weg zur Skalierung von Reinforcement-Learning-Workloads, ohne die Infrastruktur von Grund auf neu aufbauen zu müssen. Deep Infra setzt den NVIDIA-Inferenzsoftware-Stack ein, um ab dem ersten Tag hochleistungsfähige Open-Source-Modelle auf Blackwell zu betreiben, darunter DeepSeek V4. Together AI verwendet NVIDIA TensorRT-LLM auf Blackwell, um Cursor den Weg von der Modelloptimierung bis zum Produktionsendpunkt zu beschleunigen und so sein Echtzeit-Codierungserlebnis zu unterstützen.
Traditionelle Workloads wie Web-, Such- und Software-as-a-Service sind relativ vorhersagbar, aber agentische KI ist anders. Agenten können argumentieren, planen, Tools aufrufen, spezialisierte Unteragenten starten und große Kontextmengen in mehrstufigen Workflows verwalten. Dadurch wird eine einzelne Anfrage zu einem verteilten Rechenproblem, das Hunderte von Unteragenten, Tausende von Aufgaben und mehrere große Sprachmodelle umfassen kann, die auf GPUs, CPUs, DPUs und Speichersystemen laufen. Der Software-Stack entscheidet, ob sich diese Komplexität in verschwendete Rechenleistung oder in niedrigere Kosten pro Token verwandelt.
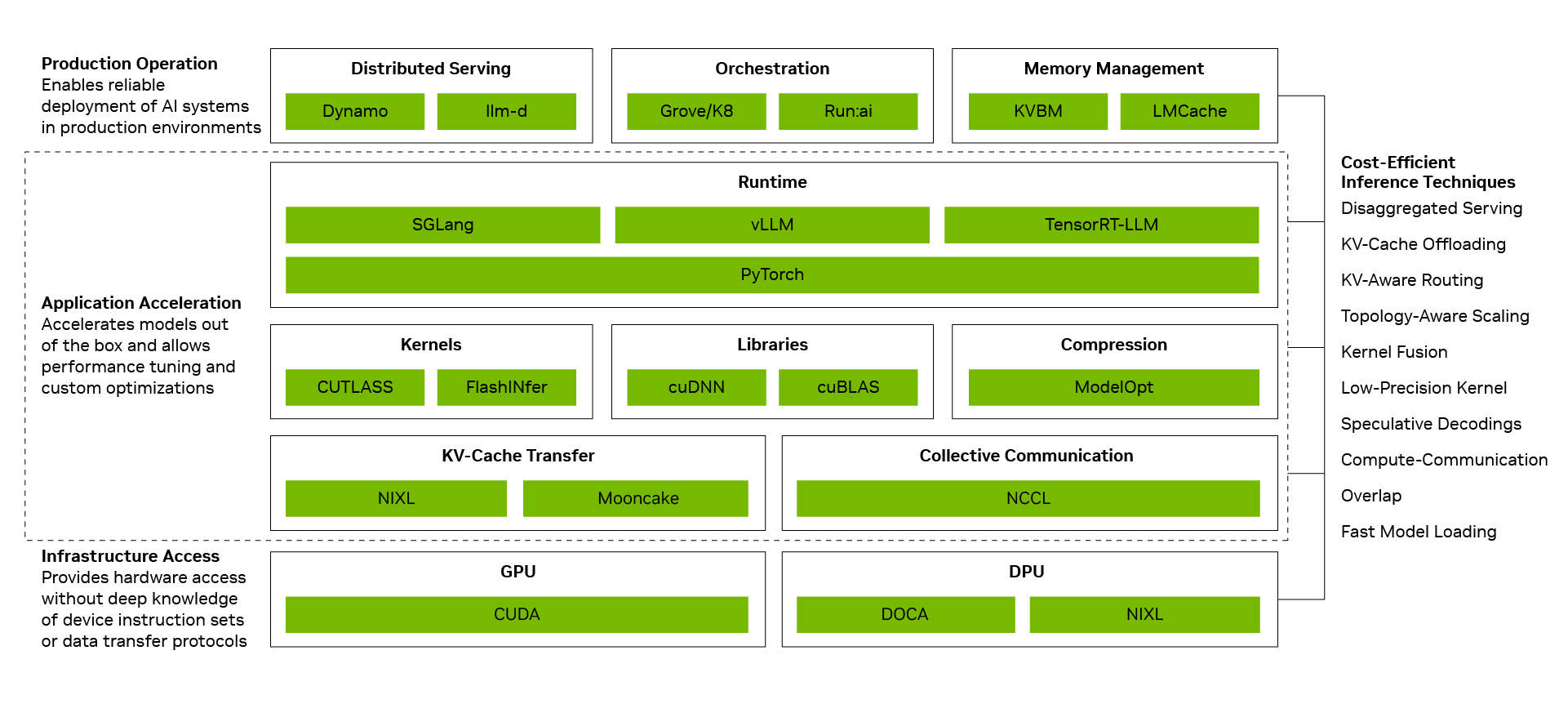
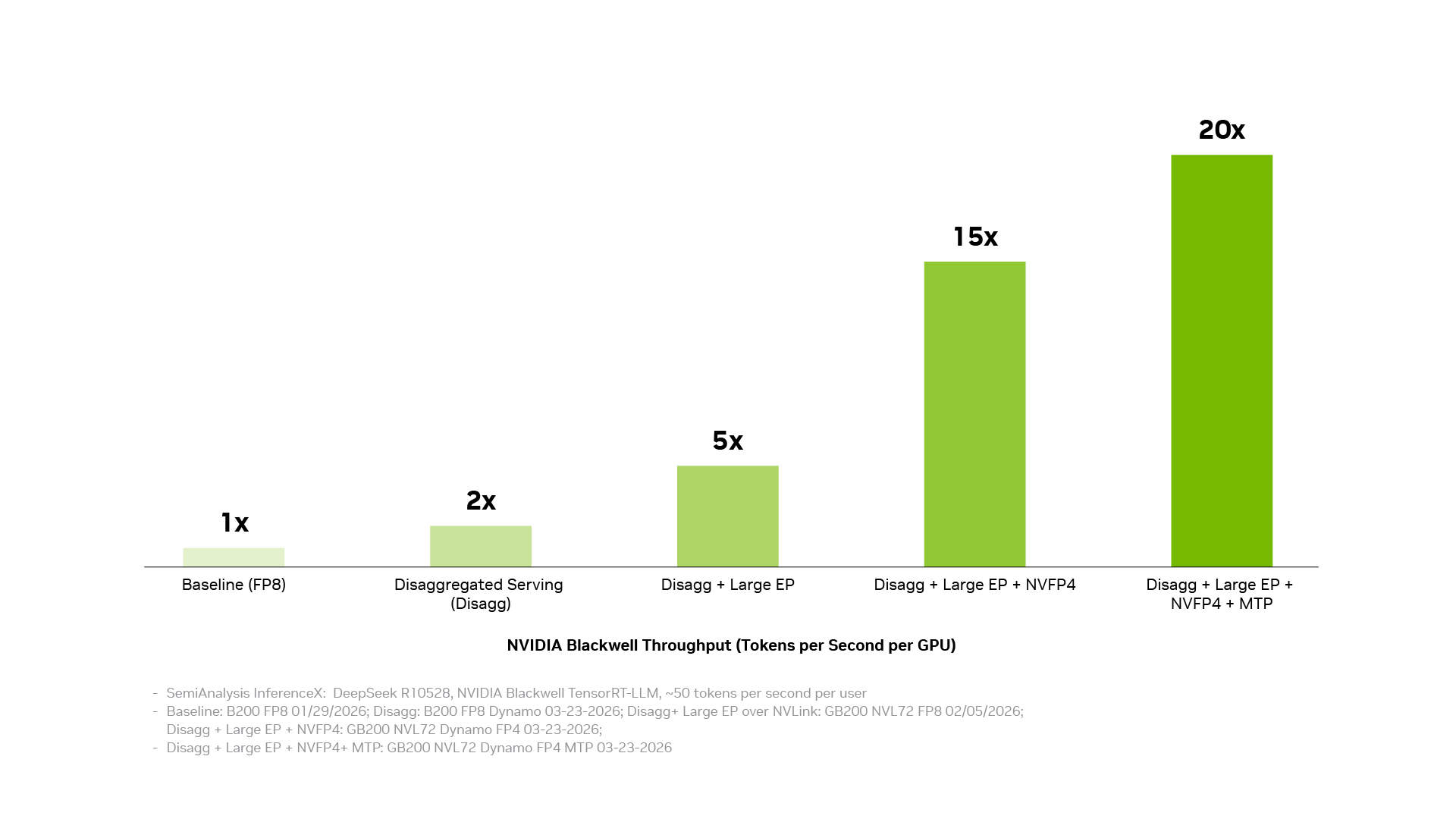
Niedrigere Kosten pro Token entstehen, wenn einzelne Optimierungen in Systemleistung umgesetzt werden. Der NVIDIA-Inferenzsoftware-Stack erreicht dies durch die Verbindung von drei Ebenen: Die Produktionsbetriebsebene koordiniert verteilte Dienste, Orchestrierung, automatische Skalierung und Speicherverwaltung; die Anwendungsbeschleunigungsebene führt Modelle mit hoher Leistung aus und bietet Entwicklern Raum für Optimierung und Anpassung; die Infrastrukturzugriffsebene legt die Fähigkeiten von NVIDIA GPUs, Netzwerken, Speicher und Systemen offen. Wenn diese Ebenen als System zusammenarbeiten, addieren sich die Optimierungseffekte. Entkoppelte Dienste, massiv parallele Experten auf Basis der NVIDIA NVLink-Interconnect-Technologie, NVFP4-Präzision und Multi-Token-Vorhersage bringen jeweils erhebliche Vorteile. In Kombination kann der Durchsatz um bis zu das 20-fache gesteigert werden.
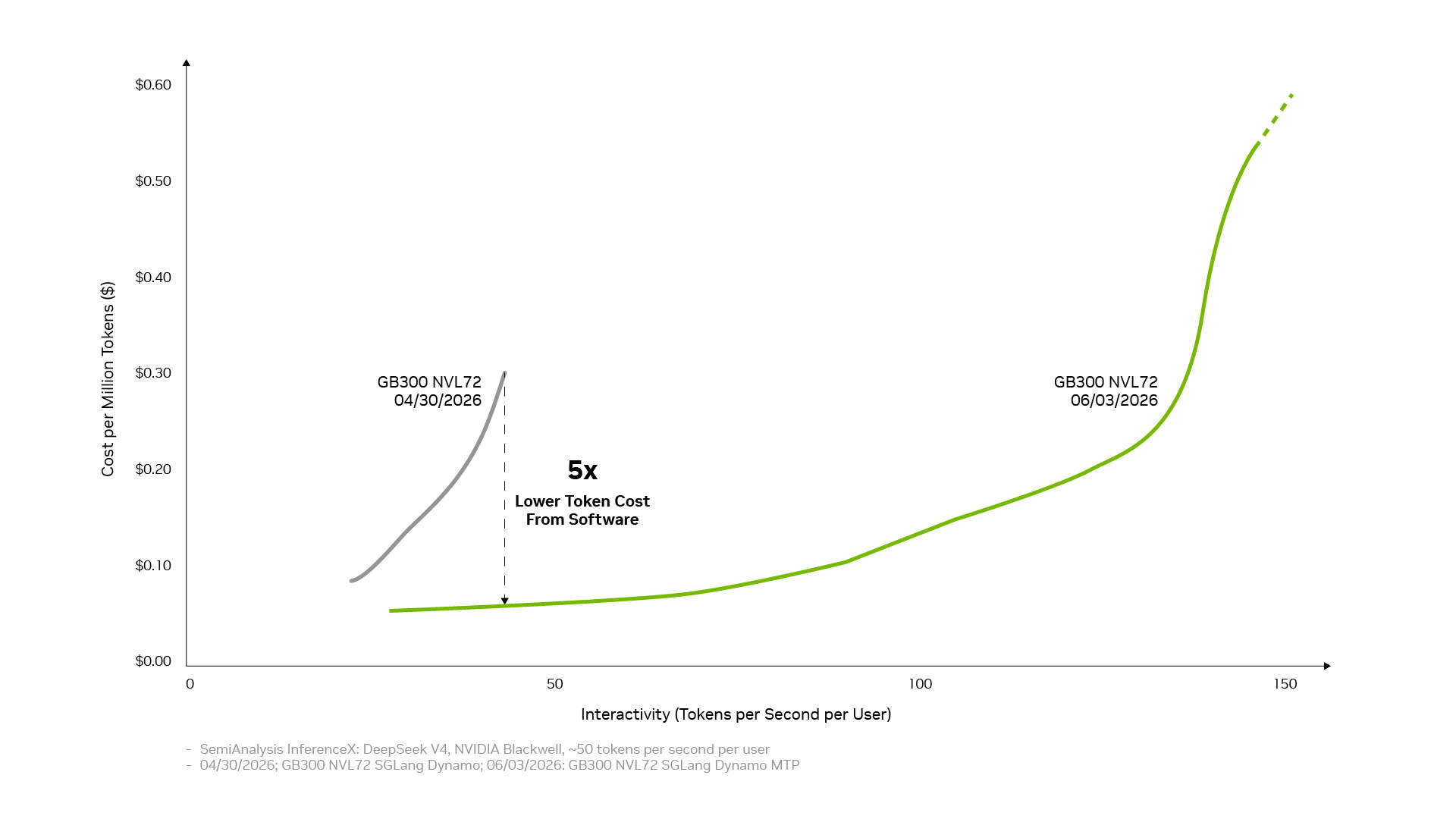
Dieselbe Full-Stack-Basis wird zudem durch das Open-Source-Ökosystem verstärkt. Viele der heute weit verbreiteten Open-Source-KI-Frameworks und Inferenzprojekte sind nativ auf NVIDIA CUDA aufgebaut. PyTorch ist ein typisches Beispiel: Es wurde 2016 eingeführt, unterstützt nativ CUDA und hat sich gemeinsam mit der NVIDIA-Architektur weiterentwickelt. Wenn bahnbrechende Technologien wie DFlash-Spekulationsdekodierung oder FastVideo in PyTorch implementiert werden, laufen sie sofort auf NVIDIA. Wenn führende offene Modelle wie DeepSeek V4 veröffentlicht werden, bieten führende Inferenzframeworks wie vLLM und SGLang ab dem ersten Tag Bereitstellungslösungen für die NVIDIA Blackwell-Architektur. Deshalb hat sich die Leistung von DeepSeek V4 auf Blackwell innerhalb eines Monats durch die Frameworks vLLM und SGLang um bis zu das Fünffache verbessert, wodurch die Kosten pro Token auf etwa ein Fünftel gesunken sind.
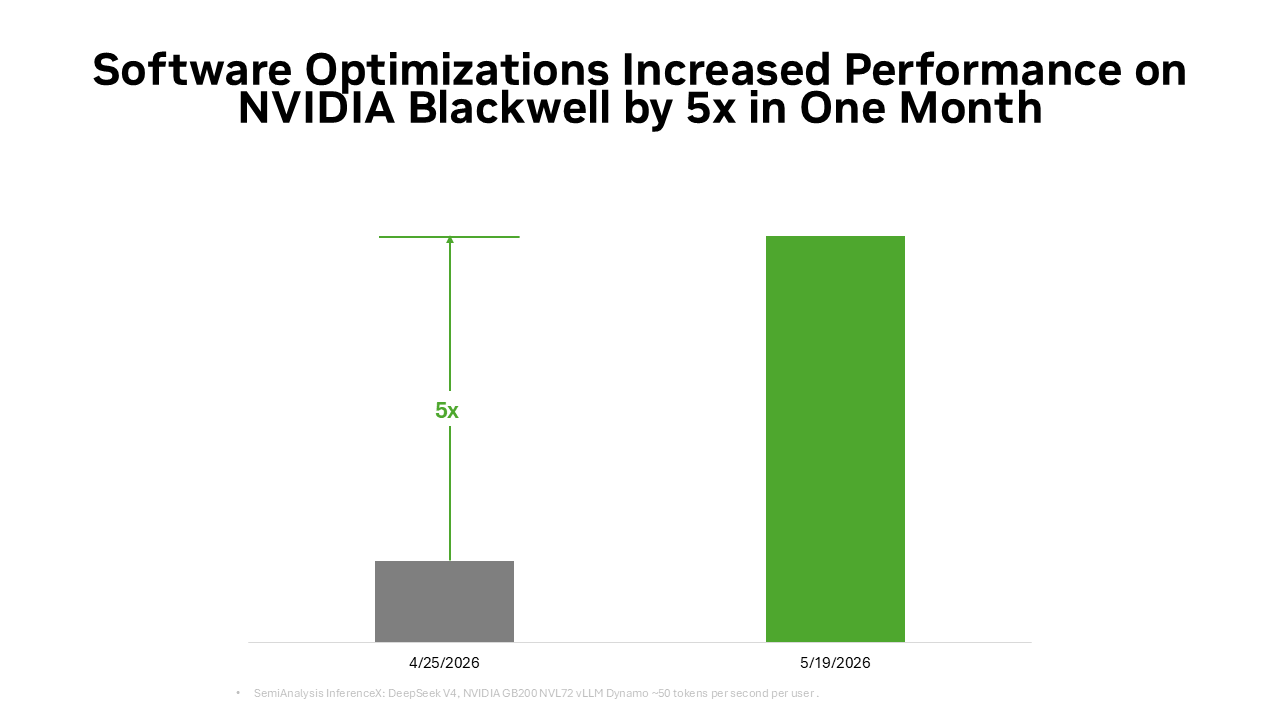
Das ist das Open-Source-Schwungrad: Immer mehr Entwickler optimieren CUDA-basierte Inferenzpfade, immer mehr Produktionsbereitstellungen fließen in das Ökosystem zurück, und jede Softwareverbesserung erhöht die Anzahl der ausgegebenen Token bei gleichzeitiger Senkung der Kosten pro Token.