de.wedoany.com-Bericht: Netflix hat die Abfrageeffizienz der Apache Druid-Datenbank durch die Einführung einer intervallbewussten Caching-Strategie optimiert. Etwa 84 % der Analyseergebnisse stammen aus dem Cache, die Abfragelast wurde um etwa 33 % reduziert und die P90-Abfragezeit um 66 % verbessert. Diese Optimierung wird hauptsächlich durch eine externe Cache-Proxy-Schicht realisiert und adressiert das Problem redundanter Berechnungen und wiederholter Scans großer Datensätze, das bei kontinuierlich aktualisierten Abfragen von Rollfenster-Dashboards aufgrund leicht verschobener Zeitbereiche entsteht.
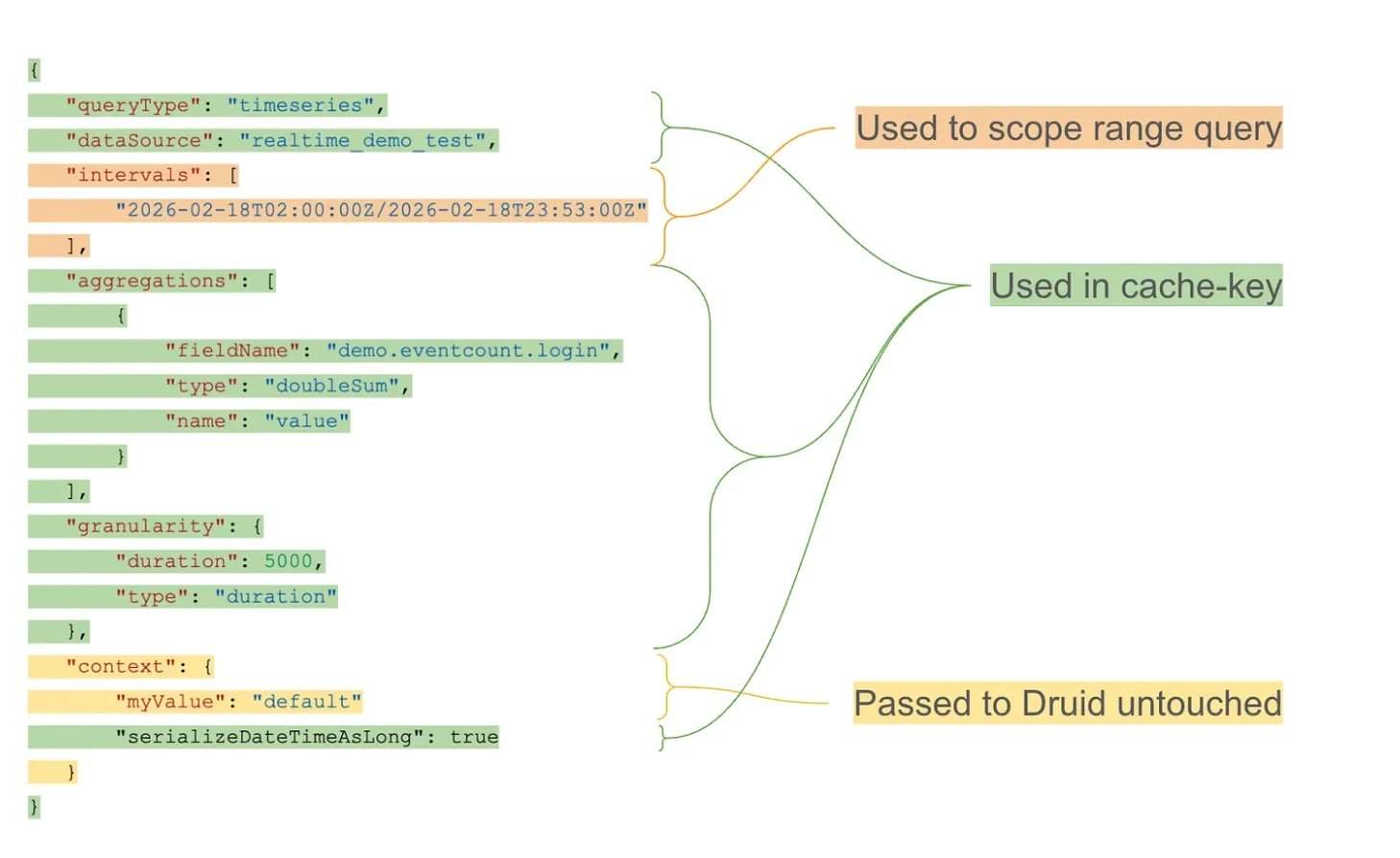
In der Größenordnung von Netflix muss das Echtzeit-Analysesystem Billionen von Datenzeilen verarbeiten, um Dashboards für Überwachung, Experimente und operative Entscheidungen zu unterstützen. Diese Dashboards führen häufig nahezu identische Abfragen durch, z. B. zur Statistik von Fehlerraten oder Engagement-Metriken innerhalb gleitender Zeitfenster. Evan King, Mitbegründer von Hello Interview, wies darauf hin, dass herkömmliches Caching wiederholte Abfragen mit geringfügig verschobenen Zeitgrenzen als unterschiedliche Anfragen behandelt, was zu einer geringen Cache-Wiederverwendungsrate und wiederholten Berechnungen in Apache Druid führt.
Netflix‘ Ansatz zerlegt Abfrageergebnisse in zeitlich ausgerichtete Segmente, um sie in überlappenden Rollfenster-Abfragen wiederzuverwenden. Anstatt vollständige Abfrageausgaben zu cachen, speichert das System Zwischenaggregate für feste Zeitintervalle. Wenn eine neue Abfrage eintrifft, werden die gecachten Segmente für den relativ stabilen historischen Teil des Zeitfensters verwendet. Nur die Daten des aktuellsten Zeitintervalls werden aus Druid neu berechnet und mit den gecachten Ergebnissen zusammengeführt.
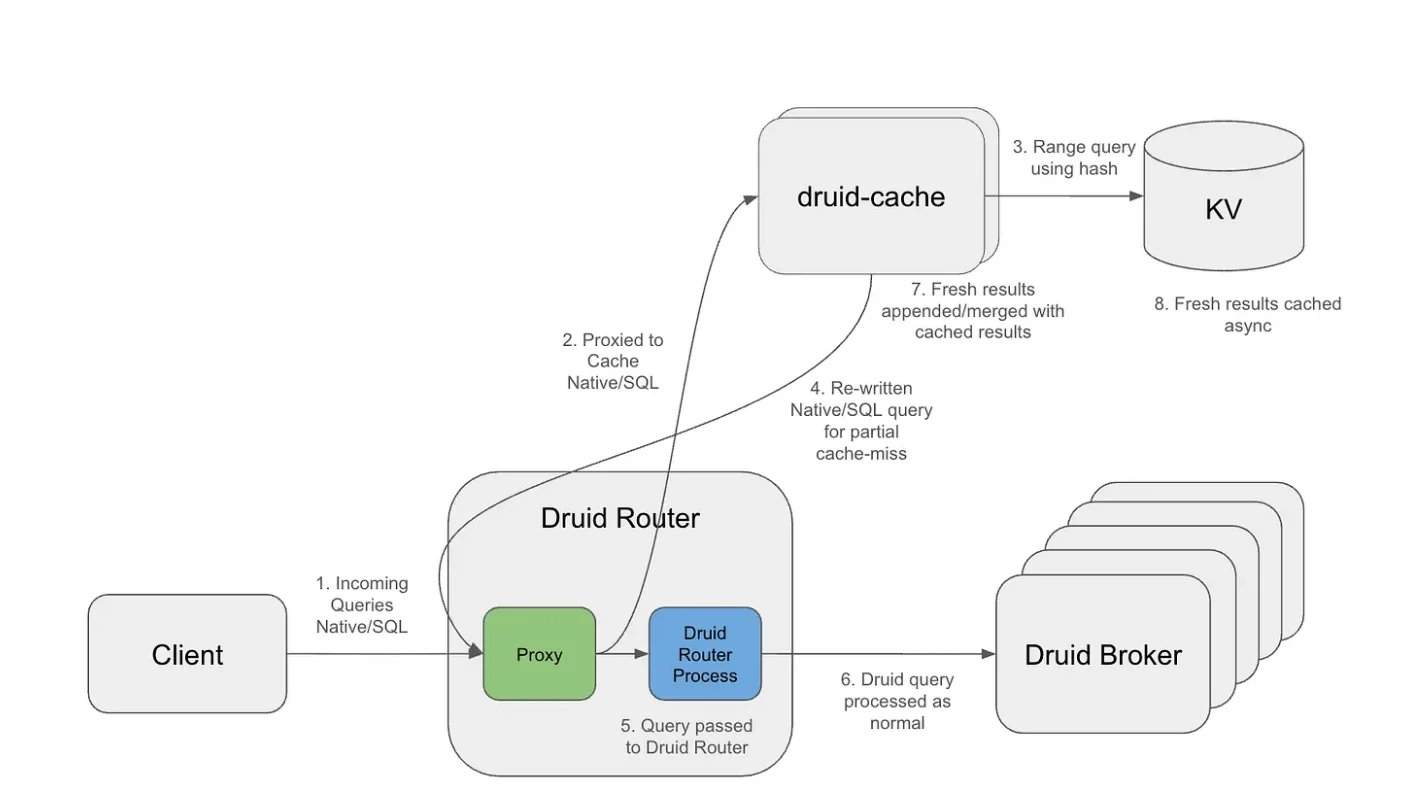
Bei einer Arbeitslast von über 10 Billionen Datenzeilen in Apache Druid wurden wiederholte Rollfenster-Abfragen zum Hauptengpass. Die Caching-Schicht verwendet granular ausgerichtete Buckets und eine exponentielle TTL-Strategie (Time-to-Live), um eine langfristige Zwischenspeicherung historischer Intervalle zu ermöglichen und gleichzeitig die Aktualität der neuesten Daten zu wahren. Architektonisch läuft die Caching-Schicht als externer Proxy, der eingehende Abfragen abfängt, die Abfragestruktur vom Zeitintervall trennt und wiederverwendbare Cache-Schlüssel generiert. Die Cache-Segmente werden in einem verteilten Schlüssel-Wert-System gespeichert, das unabhängiges Verfallen und effizientes Abrufen unterstützt.
Durch dieses Design muss nur das aktuellste Intervall neu berechnet werden, während historische Segmente in mehreren überlappenden Abfragen wiederverwendet werden können. Folglich verkleinert sich der Zeitbereich der an Druid ankommenden Abfrageoperationen erheblich, es werden weniger Segmente gescannt und weniger Daten verarbeitet. Bei bestimmten Arbeitslasten beobachtete Netflix eine Reduzierung der Ergebnisbytes um bis zu das 14-fache und eine drastische Verringerung der Segment-Scans.
Das System ist derzeit als experimentelle Schicht bereitgestellt und wird kontinuierlich weiterentwickelt. Zukünftige Arbeiten umfassen die Erweiterung zur Unterstützung von templatisierten SQL-Abfragen, die von Dashboard-Tools verwendet werden, um die Abhängigkeit von nativen Druid-Abfrageausdrücken zu verringern. Netflix untersucht auch die direkte Integration des intervallbewussten Cachings in Apache Druid, um die Notwendigkeit einer externen Proxy-Schicht zu eliminieren und die Abfrageplanungseffizienz zu verbessern.
Dieser Artikel wurde von Wedoany übersetzt und bearbeitet. Bei jeglicher Zitierung oder Nutzung durch künstliche Intelligenz (KI) ist die Quellenangabe „Wedoany“ zwingend vorgeschrieben. Sollten Urheberrechtsverletzungen oder andere Probleme vorliegen, bitten wir Sie, uns unverzüglich zu benachrichtigen. Wir werden den entsprechenden Inhalt umgehend anpassen oder löschen.
E-Mail: news@wedoany.com