
de.wedoany.com-Bericht: Robotik Der Streit um die technologische Ausrichtung stand im Mittelpunkt der Beijing Zhiyuan-Konferenz im Juni. Im vergangenen Jahr, mit der Erwärmung der Robotikbranche, hat die Diskussion darüber, ob Roboter den VLA-Ansatz (Vision-Sprache-Aktion) oder den Weltmodell-Ansatz verfolgen sollten, weiter an Fahrt aufgenommen. Dr. Guo Yandong, Gründer und CEO von ZhiPingFang, gab in seiner Eröffnungsrede auf dem Forum der Branchen-CEOs für verkörperte Intelligenz eine klare Antwort: Das Weltmodell ist keine Konkurrenz zum VLA, sondern ein Kernbestandteil seines Systems; nach der Integration von Weltmodell und VLA wird die gehirnähnliche Architektur eine wichtige Entwicklungsrichtung für die nächste Generation von Roboterhirnen sein.

Hinter dieser Einschätzung steht die technologische Ausrichtung von ZhiPingFang in den letzten drei Jahren. Guo Yandong ist der Ansicht, dass aus evolutionärer Perspektive Handlungsfähigkeit nicht isoliert entsteht; Lebewesen müssen zuerst ihre Umgebung wahrnehmen und verstehen, bevor sie handeln. Er definiert VLA neu, als Oberbegriff für eine datengetriebene End-to-End-Modellarchitektur, die mehrere Modalitäten fusioniert, und sieht keinen grundlegenden Unterschied oder Ersatz zwischen Weltmodell und VLA. Das Weltmodell löst die dichte, zeitdimensionale 4D-Vorhersage der physischen Umgebung, ist ein Teil der räumlichen Wahrnehmung von VLA und hilft, die Fähigkeiten des Roboterhirns zu verbessern. Guo Yandong erläutert den Grund für die notwendige Fusion: Beim Teekochen erfordert die logische Abfolge (zuerst den Teebeutel nehmen, dann Wasser eingießen) die Fähigkeiten des Sprachmodells, während das Weltmodell kurzfristige Vorhersagen (z.B. eine Tasse, die sich der Tischkante nähert, könnte herunterfallen) beherrscht. Nur die Kombination beider ermöglicht es dem Roboter, sowohl kurzfristige physikalische Vorhersagen als auch langfristige Aufgabenplanung zu bewältigen. ZhiPingFang nutzt das Weltmodell auch, um Randdaten zu generieren, die in realen Umgebungen schwer zu sammeln sind, um das VLA-Training zu ergänzen.
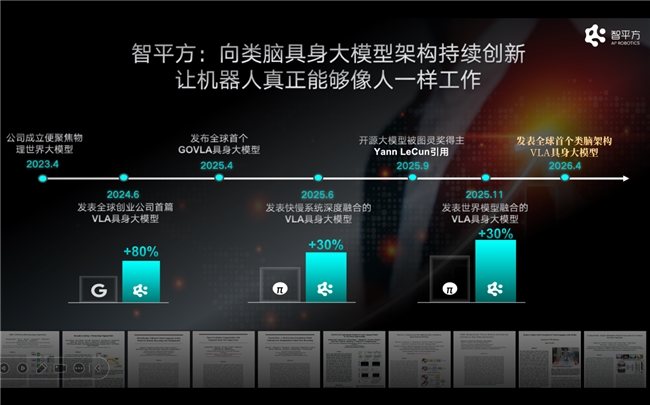
Basierend auf dieser Einschätzung hat ZhiPingFang im November 2025 gemeinsam mit der Universität Peking die neue Generation von Architektur Video2Act vorgestellt, die das Weltmodell integriert und erstmals das Paradigma „Vorhersagen, dann Ausführen" für Robotermodelle realisiert. Video2Act ist kein traditionelles Videogenerierungsmodell, sondern eine VLA-Architektur, die ein 4D-Weltmodell integriert. Durch die Modellierung dichter räumlicher Informationen und die kontinuierliche Eingabe von Aktionssequenzen kann der Roboter zukünftige Zustandsänderungen im Voraus verstehen und die Vorhersagefähigkeit in Handlungsentscheidungen umsetzen. In Tests durch Dritte erzielte Video2Act eine Leistungssteigerung von über 30% im Vergleich zu den fortschrittlichsten Modellen aus dem Silicon Valley. In der maßgeblichen Übersicht über Weltmodelle „World Model for Robot Learning: A Comprehensive Survey", die von weltweit führenden Wissenschaftlern wie dem Fellow der Royal Society und des Royal Academy of Engineering sowie Turing-KI-Forscher Philip Torr und dem Begründer des bestärkenden Lernens Pieter Abbeel gemeinsam verfasst wurde, wird Video2Act als repräsentatives Ergebnis des „Weltmodell+VLA-Fusionsansatzes" hervorgehoben zitiert.

Nach der Lösung des Problems der Fusion von Weltmodell und VLA konzentrierte sich ZhiPingFang auf die Herausforderung, wie Roboter stabil und effizient wie Menschen handeln können. Guo Yandong stellte auf der Zhiyuan-Konferenz das von ZhiPingFang neu veröffentlichte gehirnähnliche verkörperte Intelligenzsystem NeuroVLA vor. Dies ist das einzige verkörperte Intelligenzsystem, das gleichzeitig die drei biologischen Bewegungsfähigkeiten der aktiven Wahrnehmung, der Fehlerselbstwiederherstellung und des zeitlichen Gedächtnisses besitzt. Guo Yandong wies darauf hin, dass Roboter in der bestehenden VLA-Architektur zwar über ein starkes Verständnisvermögen verfügen, aber in realen, komplexen Umgebungen immer noch Probleme wie langsame Reaktion, zitternde Bewegungen und hohen Energieverbrauch haben. Der Grund liegt darin, dass die meisten Roboter auf ein einheitliches großes Modell angewiesen sind, das gleichzeitig Wahrnehmung, Schlussfolgerung und Steuerung verarbeitet.
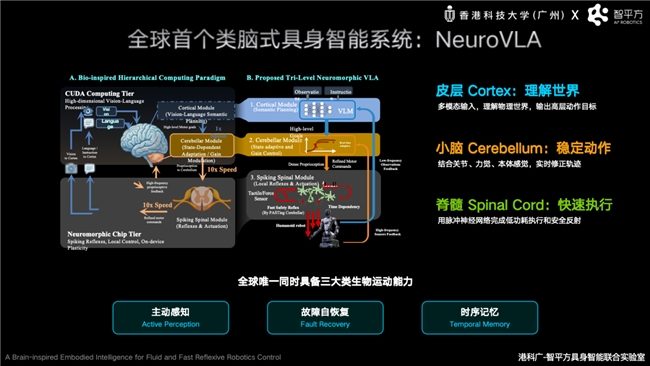
In Anlehnung an den Mechanismus des menschlichen Gehirns, bei dem die Großhirnrinde für das Denken, das Kleinhirn für die Bewegungskoordination und das Rückenmark für die unwillkürlichen Reflexe zuständig ist, hat ZhiPingFang die weltweit erste dreistufige gehirnähnliche Architektur „Großhirnrinde – Kleinhirn – Rückenmark" namens NeuroVLA entwickelt. Dabei ist die Großhirnrinde für das semantische Verständnis und die Aufgabenplanung zuständig, das Kleinhirn für die hochfrequente Bewegungskoordination und dynamische Korrektur, und das Rückenmark für die millisekundenschnelle Bewegungsausführung und Sicherheitsreflexe. Dieses Design verbessert die Stabilität, Echtzeitfähigkeit und Energieeffizienz des Roboters in der realen physischen Welt auf architektonischer Ebene. Experimentelle Ergebnisse zeigen, dass NeuroVLA das Zittern der Roboterbewegungen um über 75% reduzieren, innerhalb von 20 Millisekunden nach einer Kollision eine Reflexreaktion auslösen und den Systemstromverbrauch deutlich senken kann.

Vom End-to-End-VLA über Video2Act bis hin zu NeuroVLA hat ZhiPingFang in den letzten drei Jahren kontinuierlich systematische Innovationen rund um das Roboterhirn durchgeführt. Diese Entwicklungslinie folgt einer gemeinsamen Richtung: dem Roboter ein „Gehirn" zu geben, das dem menschlichen Gehirn ähnlicher ist.
Dieser Artikel wurde von Wedoany übersetzt und bearbeitet. Bei jeglicher Zitierung oder Nutzung durch künstliche Intelligenz (KI) ist die Quellenangabe „Wedoany“ zwingend vorgeschrieben. Sollten Urheberrechtsverletzungen oder andere Probleme vorliegen, bitten wir Sie, uns unverzüglich zu benachrichtigen. Wir werden den entsprechenden Inhalt umgehend anpassen oder löschen.
E-Mail: news@wedoany.com










