
de.wedoany.com-Bericht: Artificial Analysis hat mit AgentPerf den ersten branchenweiten Benchmark für autonome KI eingeführt. Er bietet Entwicklern, Unternehmen und Infrastrukturanbietern eine standardisierte Methode zum Vergleich autonomer KI-Systeme. Die ersten Testergebnisse zeigen, dass die NVIDIA Blackwell Ultra NVL72-Plattform bei autonomen KI-Workloads eine führende Leistung erzielt und pro Megawatt 20-mal mehr Agenten unterstützt als NVIDIA Hopper-Systeme.

Autonome KI-Workloads unterscheiden sich grundlegend von dialogorientierter KI. Ein Chat-Abschluss gleicht einem Sprint – es bedarf nur eines einzigen Aufrufs eines großen Sprachmodells (LLM) und einer Antwort. Ein Agent hingegen ist eher wie eine Staffel: Er zerlegt ein Ziel in mehrere Schritte und arbeitet kontinuierlich daran, bis die Aufgabe erledigt ist.
Dieses Muster führt zu Dutzenden oder Hunderten von LLM-Aufrufen, die aneinandergereiht sind. Jeder Aufruf übergibt einen stetig wachsenden Kontext an den nächsten und führt bei jeder Übergabe Werkzeugaufrufe wie Code-Kompilierung und -Ausführung, Datenbanksuchen und Webbrowser-Durchläufe durch. Die Komplexität addiert sich nicht, sondern multipliziert sich.
Dieser Unterschied ist entscheidend für die Leistungsmessung. Bestehende KI-Inferenz-Benchmarks messen einzelne LLM-Aufrufe, also die Antwortgeschwindigkeit eines LLM auf eine einzelne Anfrage und wie viele Anfragen ein System gleichzeitig verarbeiten kann. Sie sind nicht für autonome Workloads ausgelegt, da verkettete LLM-Aufrufe, Werkzeugaufruf-Latenzen und wachsende Kontexte die Beschleunigungssysteme ganz anders belasten als einzelne LLM-Aufrufe.
Für Unternehmen, die Agenten in großem Maßstab aufbauen und bereitstellen, ist es entscheidend zu verstehen, wie schnell Agenten reagieren, wie viele gleichzeitig bereitgestellt werden können und wie viel nützliche Arbeit pro investiertem Dollar und pro Watt elektrischer Energie in der KI-Infrastruktur geleistet werden kann.
In der ersten Testrunde verwendete AgentPerf DeepSeek V4 Pro, ein großes Mixture-of-Experts-Modell, das die derzeit leistungsfähigsten Agenten antreibende Spitzenmodellklasse repräsentiert, um die autonome Leistung zu messen. Bei diesem Workload erzielte das NVIDIA GB300 NVL72 die höchste Leistung im Benchmark und unterstützte 20-mal mehr Agenten pro Megawatt als das NVIDIA HGX H200-System.
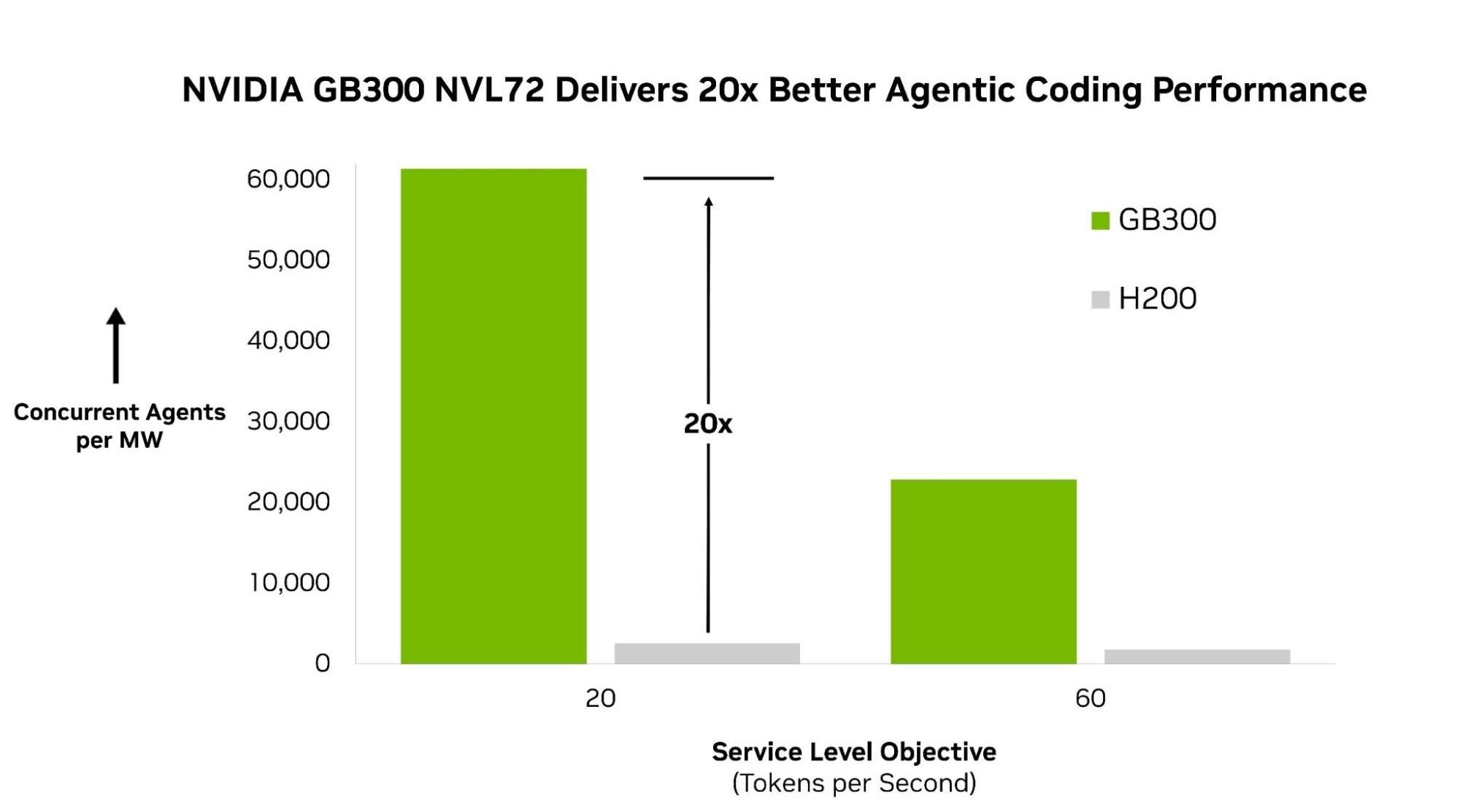
Dieser Leistungsvorteil resultiert aus einem extrem kohärenten Full-Stack-Design. Das GB300 NVL72 verbindet 72 GPUs zu einem Rack-Scale-System, sodass große MoE-Modelle wie DeepSeek V4 Pro effizient massiv parallel ausgeführt werden können. CUDA-Kerne beschleunigen die Ausführung zusätzlich durch die Überlappung von Kommunikation und Berechnung, sodass die Kosten der Koordination zwischen den Experten absorbiert werden, anstatt die Latenz zu erhöhen. Mit zunehmender Anzahl gleichzeitiger Agentensitzungen bleibt NVIDIA TensorRT LLM effizient, indem es die Eingabeverarbeitung von der Ausgabeerzeugung trennt, sodass jeder Schritt unabhängig optimiert werden kann. Diese Ergebnisse basieren auf einer von Grund auf neu entwickelten Benchmark-Methodik, die die tatsächliche Funktionsweise autonomer KI in der Produktion widerspiegeln soll.
AgentPerf basiert auf realen Codierungs-Agenten-Trajektorien. Agenten erhalten Aufgaben, lesen Dateien, schreiben und bearbeiten Code, führen Befehle aus und iterieren basierend auf den Ergebnissen. Alle Daten stammen aus echten öffentlichen Code-Repositories in über 12 Programmiersprachen. Lange Sequenzlängen, Werkzeugaufrufmuster und Latenzen repräsentieren reale Codierungs-Workflows. AgentPerf misst, wie viele solcher autonomen Aufgaben eine Plattform gleichzeitig unterstützen kann, während sie vorgegebene Leistungsschwellenwerte wie Reaktionsfähigkeit und Ausgabe-Token-Rate einhält. Werkzeugaufrufe werden nicht tatsächlich ausgeführt, sondern mit repräsentativen CPU-Verarbeitungszeiten simuliert, sodass Ergebnisunterschiede ausschließlich die Auswirkungen der Beschleunigungsrechenleistung widerspiegeln. Die Ergebnisse lassen sich direkt in Infrastrukturentscheidungen umsetzen: Wie viele gleichzeitige autonome Aufgaben pro Beschleuniger und pro Megawatt Strom ausgeführt werden können.
Führende Inferenzanbieter, darunter Baseten, DeepInfra und Together AI, bedienen bereits autonome Workloads für Spitzenmodelle wie DeepSeek V4 Pro auf NVIDIA Blackwell. Together AI bietet Echtzeit-Inferenz für Cursor, eine KI-gesteuerte autonome Codierungsplattform, auf NVIDIA Blackwell. Die Agenten von Cursor debuggen Probleme, generieren Funktionen und führen Refactorings durch, während Entwickler weiterarbeiten. DeepInfra unterstützt Pam.ai, eine KI-Arbeitskraftplattform für Autohäuser, die Agenten vollständig auf NVIDIA Blackwell einsetzt, um Service-Termine zu buchen, Anrufe zu bearbeiten und ausgehende Verkaufsaktionen durchzuführen. Mit der kontinuierlichen Optimierung der Inferenzsoftware durch NVIDIA und das Open-Source-Ökosystem werden Leistung und Effizienz autonomer Workloads stetig steigen. Die NVIDIA Vera Rubin-Architektur befindet sich nun in voller Produktion und wird die nächste Generation an Infrastrukturkapazität bereitstellen, um die wachsende Nachfrage nach skalierbarer autonomer KI zu decken. Weitere Details zur AgentPerf-Methodik und den Full-Stack-Optimierungen finden Sie im entsprechenden technischen Blog.
Dieser Artikel wurde von Wedoany übersetzt und bearbeitet. Bei jeglicher Zitierung oder Nutzung durch künstliche Intelligenz (KI) ist die Quellenangabe „Wedoany“ zwingend vorgeschrieben. Sollten Urheberrechtsverletzungen oder andere Probleme vorliegen, bitten wir Sie, uns unverzüglich zu benachrichtigen. Wir werden den entsprechenden Inhalt umgehend anpassen oder löschen.
E-Mail: news@wedoany.com










