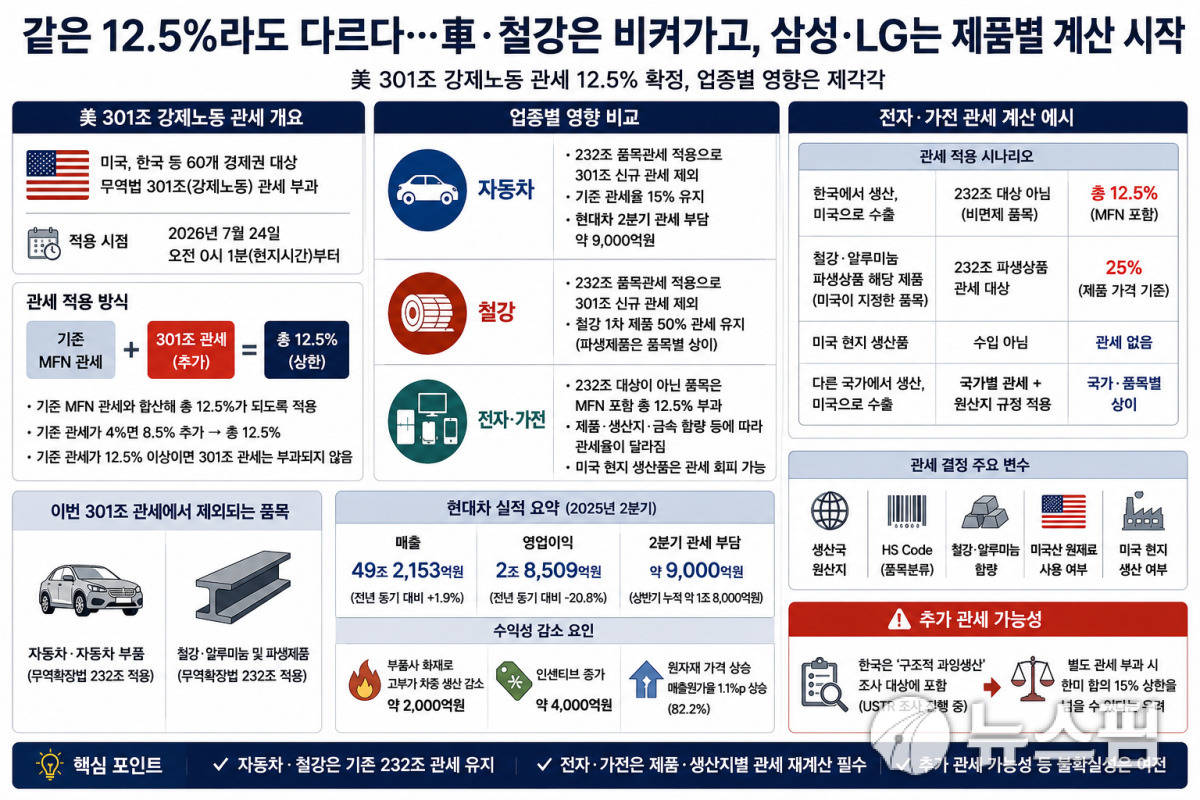
de.wedoany.com-Bericht: Lebensmittel- und Getränkehersteller beseitigen systematisch Produktionsverschwendung und beugen Kapazitätsengpässen durch Datenstandardisierung und maschinelles Lernen vor. Laut dem „State of Lean Manufacturing Report 2023" wenden in den USA nur 10 bis 15 Prozent der Unternehmen Lean-Prinzipien systematisch an und erzielen daraus signifikante Wettbewerbsvorteile und finanzielle Erträge. Der Kern von Lean Management und Six Sigma liegt stets in der Prozessoptimierung, der Befähigung der Mitarbeiter und der Lösung praktischer Probleme – nicht in blinden Kapitalinvestitionen.
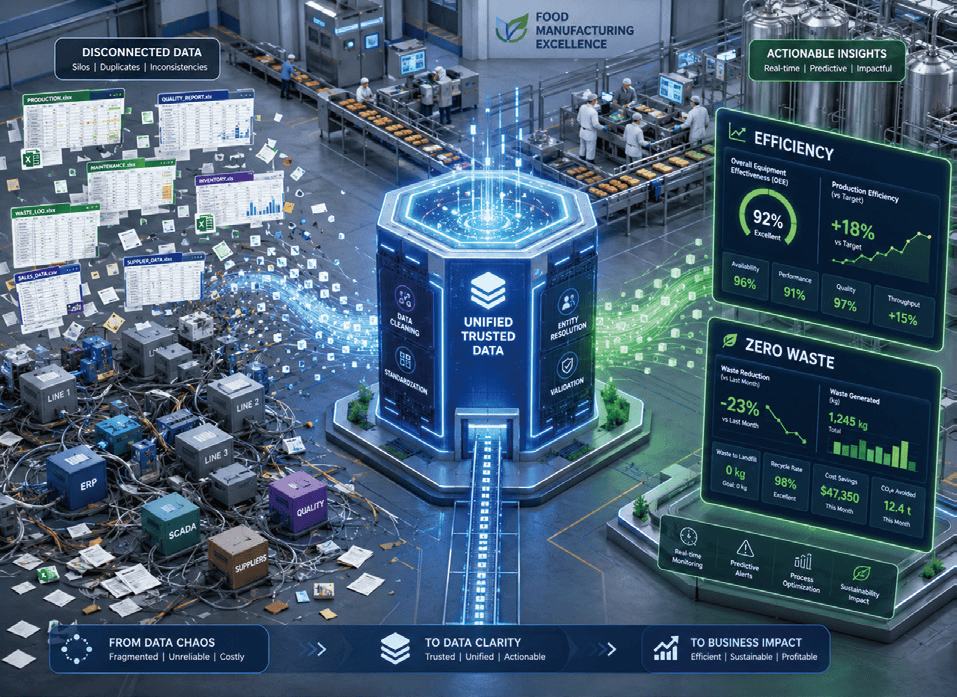
Heute verstärken Lebensmittel- und Getränkehersteller ihre Automatisierungsinvestitionen und stärken gleichzeitig ihre langfristige Wettbewerbsfähigkeit durch die Standardisierung von Fabrikdaten. Maschinelles Lernen wird bereits in Bereichen wie Verpackung, vorausschauender Wartung und Reinigung vor Ort (CIP) eingesetzt – es identifiziert präzise Verschwendungsquellen und liefert Optimierungslösungen. Markus Guerster, Gründer und CEO von MontBlancAI, betont, dass Lean Management im Zeitalter des maschinellen Lernens nicht nur Algorithmenmodelle erstellen darf, sondern Dateneinblicke in die täglichen Arbeitsabläufe integrieren muss. KI muss tief in Produktionsbesprechungen, Wartungsprotokolle und kontinuierliche Verbesserungszyklen eingebettet sein, sonst kann sie keinen dauerhaften Wert für das Unternehmen schaffen. John Oskin, Senior Vice President bei SmartSights, erklärt, dass die meisten Lebensmittel- und Getränkehersteller in den letzten 15 bis 20 Jahren erhebliche Summen in Hardware-Automatisierung investiert haben, Datenstandardisierung jedoch selten von Anfang an in die strategische Planung einbezogen wurde. Im Jahr 2024 gab Michael Warter, Senior Vice President und Chief Information Officer des Tiefkühlkostriesen Ruiz Foods, bekannt, dass das Unternehmen ein großes Datenstandardisierungsprojekt für die Forschungs- und Entwicklungsabteilung vorantreibt. Bisher waren Daten in isolierten Systemen verstreut; eine tiefgreifende Integration ist entscheidend, um Datensilos zu durchbrechen und die Abhängigkeit von Tabellenkalkulationen zu beenden. Erste Maßnahmen haben bereits bei der Einhaltung von Vorschriften und der Produktrückverfolgbarkeit Wirkung gezeigt. Er räumte ein, dass der Vorstand zunächst die tiefgreifende Bedeutung von Künstlicher Intelligenz für die Produktion nicht erkannt habe, aber heute erkenne das Führungsteam, dass Lean-Management-Prinzipien, die Reduzierung von Produktionsverschwendung und die zukünftige Entwicklung der KI eng miteinander verbunden sind.
David Ariens, Gründer der Branchenmedien- und Beratungsplattform IT/OT Insider, erklärt, dass Lean Management und Six Sigma systematische Methoden zur Beseitigung von Verschwendung und zur Kontrolle von Prozessschwankungen bieten. Diese Methoden lassen sich nun auf das Datenmanagement übertragen – um den Aufwand bei der Datensuche, -bereinigung und -kontextualisierung zu reduzieren und eine zugrunde liegende Infrastruktur aufzubauen, die verhindert, dass jede neue Anwendung von Grund auf neu entwickelt werden muss. Derzeit zeichnet sich bei neuen Lebensmittelfabriken in den USA ein klarer datengetriebener Trend (Data-first) ab. Bob Rice, Vice President of Engineering bei Control Station, weist darauf hin, dass das Hauptziel beim Bau von Fabriken vor 20 Jahren darin bestand, „die Anlagen zum Laufen zu bringen". Heute legen große Projekte von Anfang an extrem hohe Betriebsstandards fest, die eine bestimmte Produktionskapazität bereits in der Anfangsphase der Inbetriebnahme erfordern, und führen sogar vor Baubeginn Datenanalyseplanungen durch. Datenpriorität bedeutet jedoch nicht, ein vollständiges maschinelles Lernmodell für die gesamte Fabrik zu erstellen. Ariens ergänzt, dass nur wenige Unternehmen eine vollständige „Manufacturing Ontology" aufbauen – ein maschinenlesbares High-Level-Modell, das die Zuordnung von Geräten und Prozessen, den Materialverbrauch in jeder Phase sowie die Abstimmung von Chargenrezepturen und Produktionsparametern definiert. Guerster ist der Ansicht, dass die größte Herausforderung bei der Umsetzung von Datenprojekten mit maschinellem Lernen derzeit in der abteilungsübergreifenden Zusammenarbeit liegt: Unterschiedliche Produktionslinien oder Standorte verwenden oft eigene Signalbenennungen, Maßeinheiten, Abtastraten und kontextuelle Metadaten, und die IT- und OT-Abteilungen arbeiten häufig isoliert voneinander. Ariens betont, dass selbst die fortschrittlichste Technologie eine Datenstrategie nicht retten kann, wenn IT und OT nicht zusammenarbeiten.
Die digitale Transformation von Unternehmen muss klein anfangen und sich auf schnelle Erfolge (Quick Wins) konzentrieren. Guerster erklärt, dass vor dem Start eines Datenprojekts der geschäftliche Nutzen geklärt werden muss. Erfolgreiche Unternehmen wählen in der Regel Szenarien mit klarem Umfang, die direkt mit quantifizierbaren Kernleistungsindikatoren (KPIs) verknüpft sind. Oskin befürwortet die Strategie „kleine Schritte, schnelle Iteration" und empfiehlt, für eine Schlüsselmaschine, eine Kernproduktionslinie oder einen wichtigen Indikator ein bis zwei KI-Projekte zu planen, die innerhalb einer Woche oder eines Monats Ergebnisse liefern. Marc Bertrand von SmartSights teilte in einem Webinar ein Fallbeispiel: Ein Kunde konnte mithilfe der Feature Importance Analysis und der Prescriptive Analysis erfolgreich den Engpass in der Verpackungslinie identifizieren und die Verschwendung erheblich reduzieren. Die Feature Importance Analysis identifiziert präzise die einflussreichsten Variablenparameter und hilft beim Aufbau effizienter, interpretierbarer Datenmodelle. Das Hauptanliegen des Kunden war die Festlegung von KPIs wie der Mean Time Between Failures (MTBF) oder die Bewertung des Werts der Maschinenzentren an den Engpassstellen der Verpackungslinie. Die ABLE-Technologie von SmartSights führte eine Root Cause Analysis für die Bündelmaschinen, Umhüllungsmaschinen und Palettiermaschinen in der Linie durch und identifizierte anhand potenzieller Ursachen genau die Maschine mit dem größten Einfluss auf die gesamte Linie. Gleichzeitig verwendete das Projektteam die Prescriptive Analysis, um die Verpackungslinie vollständig zu modellieren. Für den Kapazitätsengpass wurde ein entscheidender KPI namens „Effective Rate" eingeführt, der sich aus der Geräteverfügbarkeit multipliziert mit der durchschnittlichen Linienrate ergibt und die tatsächliche Produktion pro Minute genau misst. Bertrand weist darauf hin, dass die Schlussfolgerungen beider Algorithmen zwar datentechnisch korrekt, aber äußerst irreführend waren – die Analyse deutete auf die Palettiermaschine als Schwerpunkt hin, während das eigentliche Problem bei der Bündelmaschine lag. Dank der tiefgreifenden Einblicke durch maschinelles Lernen fand das Unternehmen einen Ausgleich, erhöhte gleichzeitig die Geschwindigkeitsobergrenze und die tatsächliche Betriebsrate beider Maschinen und überwand erfolgreich den Kapazitätsengpass in diesem Produktionszentrum.
Dieser Artikel wurde von Wedoany übersetzt und bearbeitet. Bei jeglicher Zitierung oder Nutzung durch künstliche Intelligenz (KI) ist die Quellenangabe „Wedoany“ zwingend vorgeschrieben. Sollten Urheberrechtsverletzungen oder andere Probleme vorliegen, bitten wir Sie, uns unverzüglich zu benachrichtigen. Wir werden den entsprechenden Inhalt umgehend anpassen oder löschen.
E-Mail: news@wedoany.com