
de.wedoany.com-Bericht: Forscher des IMDEA Software Institute, Nokia Bell Labs, der Complutense University of Madrid, der Aalto University und von Quobly haben eine FPGA-basierte Hardwarearchitektur zur Echtzeit-Decodierung von Quanten-LDPC-Codes entwickelt. Der auf ArXiv veröffentlichte Entwurf verwaltet korrelierte Fehlerarrays durch eine strukturelle Anordnung, optimiert Latenz, physische Fläche und Leistungsaufnahme und löst so den Engpass der klassischen Rechenverarbeitung, der die physische Skalierung von Quantenfehlerkorrekturschichten behindert. Die Architektur nutzt gezielte Ressourcenwiederverwendungsschleifen anstelle unbegrenzter Hardwareparallelisierung, um komplexe Multi-Qubit-Syndrom-Abhängigkeiten zu verarbeiten.
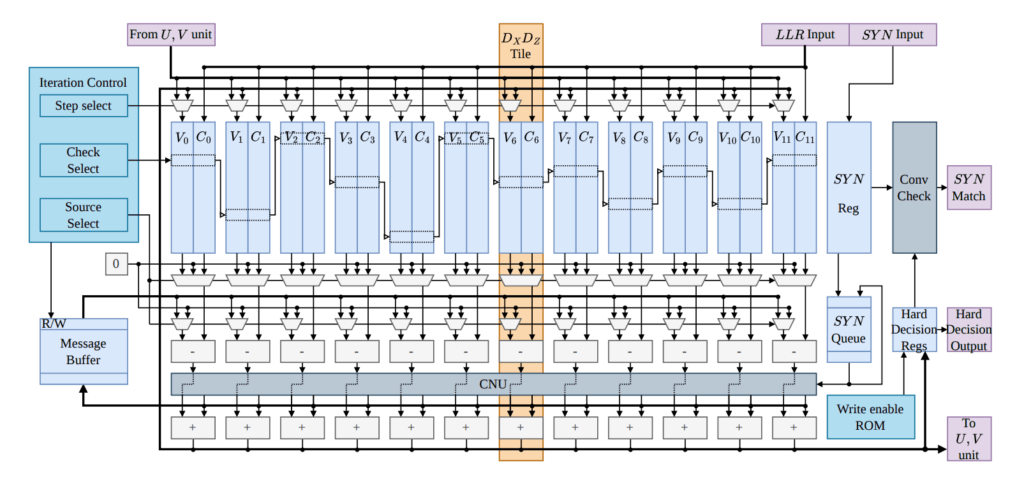
Das interne Layout des Decoders bildet direkt einen speziellen Graph-Enhanced and Reconnection Inference (GARI)-Rahmen ab. Standard-Decodierungsroutinen verarbeiten räumliche X- und Z-Fehlerkoordinaten normalerweise unabhängig voneinander, was die Tracking-Treue verringert, wenn Phasen- und Bit-Flip-Parameter durch kombinierte Y-Fehler-Pfade verknüpft werden. Die GARI-Transformation ändert die zugrunde liegende Detektor-Fehlermodell-Matrix, indem sie korrelierte Variablen trennt und kurze 4-Zyklen mit Y-Fehlern eliminiert, wodurch der Verwicklungsgraph durch strukturierte U- und V-Koordinatenabhängigkeiten ersetzt wird. Diese algebraische Rekonstruktion ermöglicht es der Hardware, die gemeinsame Decodierungsaufgabe auf entkoppelte Ausführungspfade zu verteilen, während der iterative Informationsaustausch zwischen den Fehlerdomänen aufrechterhalten und schädliche Nachrichtenkorrelationen unterdrückt werden.
Zur Ausführung der rekonstruierten Matrix unterteilt die Architektur die Verarbeitungsaufgaben in einen Belief-Propagation (BP)-Kern und ein parallelisiertes Tracking-Modul. Die Hauptmatrizen DX und DZ werden durch eine speicherbasierte, seriell geplante BP-Einheit geleitet, die Berechnungsparameter sequentiell nach der normalisierten Min-Sum-Regel aktualisiert. Die unabhängigen Prüfstrukturen der U- und V-Matrizen werden innerhalb separater Hardware-Tiles parallelisiert und synchron mit dem seriellen Kern in Verarbeitungsintervallen verarbeitet. Die modulare Kreuzverbindung verwendet binäre Radix-Sortierstufen als N-zu-N-Pipeline-Router, um explizite klassische Controller-Logik zu umgehen und Routing-Überlastungen sowie Datenbus-Stillstände zu verhindern.
Die Hardware-Implementierung wurde auf einem AMD VCU19P FPGA evaluiert und auf eine VU29P FPGA-Struktur abgebildet, um den [[144,12,12]] bivariaten Fahrradcode innerhalb eines Fensters von 12 aufeinanderfolgenden Syndrommessrunden zu decodieren. Die Architektur wendet numerische Quantisierungsbeschränkungen an, die die Eingangs-Log-Likelihood-Ratios (LLR) auf 6 Bit, Prüfknotennachrichten auf 8 Bit und Variablenknotenwerte auf 10 Bit begrenzen, während die numerische Genauigkeit des klassischen Gleitkomma-Tracking-Modells angenähert wird. Mit einer Betriebsfrequenz von etwa 274 MHz über AXI-Stream-Ports bietet die Pipeline-Ausführungsschleife eine durchschnittliche Decodierungslatenz von 596 Nanosekunden pro Runde und erfüllt damit die Echtzeit-Decodierungsanforderungen unter realistischen korrelierten Rauschverteilungen.
Ein einzelner Kern belegt eine begrenzte Fläche, darunter 7,5 % der gesamten Logik-Look-Up-Tables (LUTs), 3,5 % der Register und 26 % der internen Block-RAM (BRAM)-Elemente, die teilweise auf URAM-Blöcke abgebildet werden können, um den Speicherdruck zu verringern. Diese Ressourceneffizienz ermöglicht den gleichzeitigen Betrieb von drei Decodern in einer kombinierten Konfiguration innerhalb einer einzelnen VCU19P FPGA-Platine. Eine vollständige Tracking-Kombination von 24 gleichzeitigen Decodern kann auf acht physischen Hardware-Geräten bereitgestellt werden, verglichen mit 48 Platinen, die für eine vollständig parallelisierte alternative Architektur erforderlich wären.
Detaillierte Silizium-Ressourcenzuweisungen, Matrix-Transformationsableitungen und Routing-Latenz-Benchmarks sind in der vollständigen Vorabveröffentlichung auf ArXiv einsehbar.
Dieser Artikel wurde von Wedoany übersetzt und bearbeitet. Bei jeglicher Zitierung oder Nutzung durch künstliche Intelligenz (KI) ist die Quellenangabe „Wedoany“ zwingend vorgeschrieben. Sollten Urheberrechtsverletzungen oder andere Probleme vorliegen, bitten wir Sie, uns unverzüglich zu benachrichtigen. Wir werden den entsprechenden Inhalt umgehend anpassen oder löschen.
E-Mail: news@wedoany.com









